4. Scheduling with dependencies
This chapter describes services provided by Cheddar when the system you want to study has task dependencies. By task dependencies, we mean resources shared by several tasks (ex : semaphores) or precedency relationships between several tasks (due to buffer access or message exchange or also constraints between the end of a task and the start of another one).
4.1 Shared resources analysis tools
With Cheddar, you can define shared resources. Shared resources can be seen as semaphores. They can be accessed by several tasks. Tasks that require access to an already allocated semaphore are blocked (and then, unscheduled). To define a shared resource in a Cheddar project, call the submenu "Edit/Entities/Softwares/Resource". The window below is then displayed :
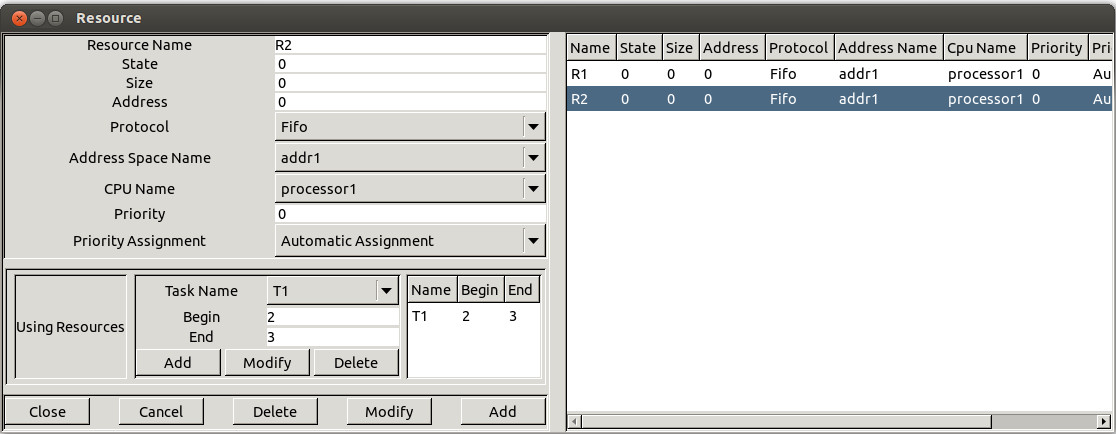
Figure 4.1 Add a new shared resource
Before adding a shared resource, at least one processor and one task must already exist in your project. A resource is defined by the following information :
- An unique name.
- An initial value/state (simular to a semaphore initial value). During a scheduling simulation, at a given time, if a resource value is equal or less than zero, the requesting tasks are blocked until the semaphore/shared resource is released. An initial value equal to 1 allows you to design a shared resource that is initially free and that can be used by only one task at a given time.
- A protocol. Currently, you can choose between PCP (for Priority Ceiling Protocol), PIP (for Priority Inheritance Protocol) or "No protocol". With PCP or PIP, accessing shared resources may change task priorities [SHA 90]. The "No protocol" just means that no task prioriy will be changed at accessing the shared resource.
- A processor name: Each shared resource has to be hosted by a given processor.
- A priority: defines the ceiling priority of the resource
- A priority assignment: characterize the way that Cheddar assigns ceiling priority to resource
- automatic assignment: assigns automatically ceiling priorities to resources. The attribute priority is ignored during simulation.
- manual assignment: assigns manually ceiling priorities to resources. The attribute priority is used during simulation
- Finally, we must give information on tasks that need the resource. Tasks hold resources in critical section. Each critical section has to be defined by:
- The task name requiring the shared resource.
- The start time of the critical section.
- The end time of the critical section. Of course, you can define several critical sections for a given task of a given shared resource.
By default, shared resources analysis tools are not included in the scheduling simulation engine of Cheddar. See "Tools/Scheduling/Options" if you want to take care of shared resources during scheduling simulation and if you want to display shared resources time line. Blocking time on shared resources can be computed from scheduling simulation analysis if scheduling simulation is invoked from the sub-menu "Tools/Scheduling/Scheduling Simulation".
Finally, from the "Tools/Resources/Bound on Blocking time" sub-menu, you will find services to compute bounds on blocking time of each tasks. These bounds are computed without assumption on the scheduling actually generated for the analyzed system. To compute blocking time bound, shared resources have to used PCP or PIP protocols.
4.2 Task precedencies
With Cheddar, dependencies are links between at least two tasks. There are three different types of dependencies : precedencies, message and buffer dependencies. Precendencies express order constraints between end or beginning of task execution. Message dependencies express relationships between a sender and a receiver task of a given message. Buffer dependencies express relationships between producer and consumer of data in a given buffer.
4.2.1 Editing Task precedencies
To create a dependency, choose "Edit/Entities/Softwares/Dependencies". The window of figure 4.2 is then displayed :
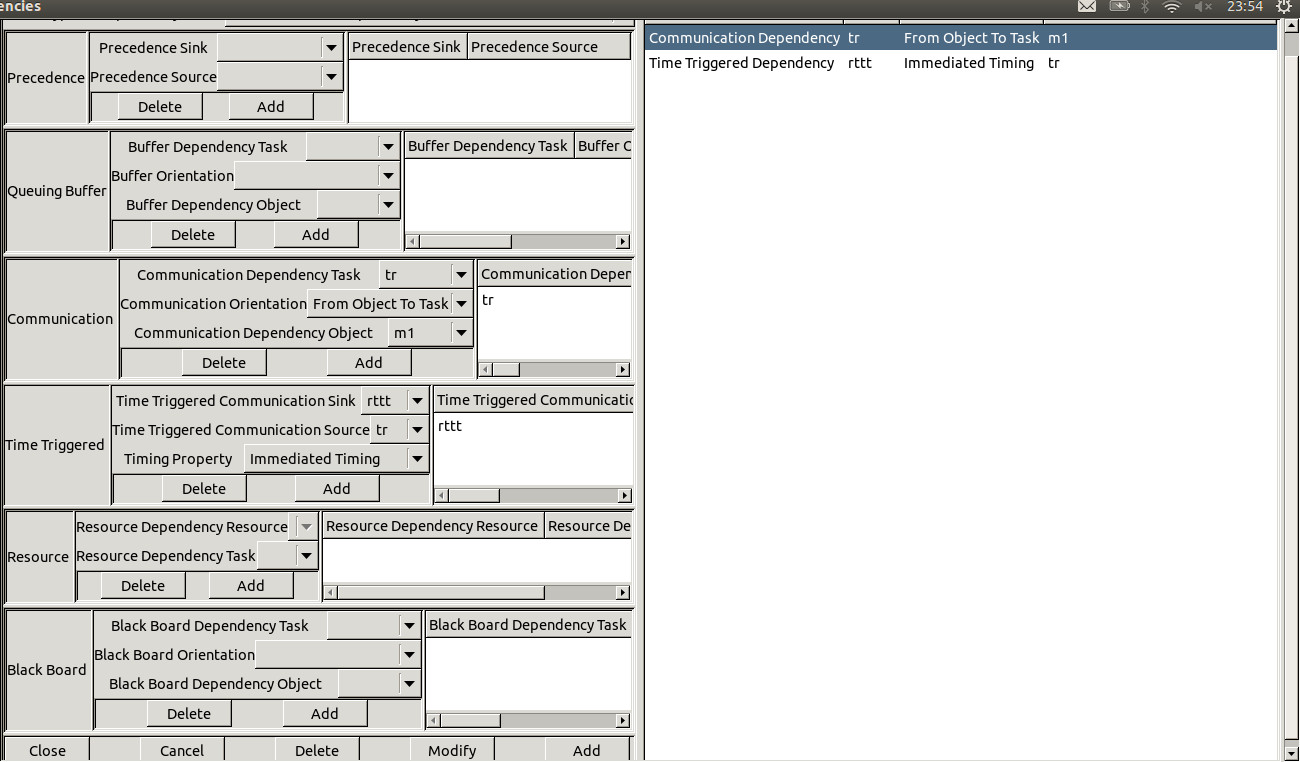
Figure 4.2 Add a new dependency
A dependency is characterized by:
-
The type of dependency. We distinguish:
-
precedence dependency ...
- precedence_sink ...
- precedence_source ...
-
queuing buffer dependency ...
- buffer dependent task ...
- buffer orientation ...
- buffer dependency object ...
-
communication dependency ...
- communication dependent task ...
- communication orientation ...
- communication dependency object ...
-
time triggered communication dependency ...
- sampled timing ...
- immediate timing ...
- delayed timing ...
-
resource dependency ...
- resource dependency resource ...
- resource dependency task ...
-
black board buffer dependency ...
- black board dependent task ...
- black board orientation ...
- black board dependency object ...
4.2.2 How to transform a dependent task set into an independent task set: the Chetto/Blazewicz modification rules
4.2.3 Computing end to end response time: the Holistic approach
4.3 Buffer analysis tools
Cheddar allows you to define buffers shared by tasks. If you want to define a buffer, a processor, an address space and a least one task have to be defined before. A buffer can be added to a Cheddar project with the submenu "Edit/Entities/Softwares/Buffer". The window below is then displayed :
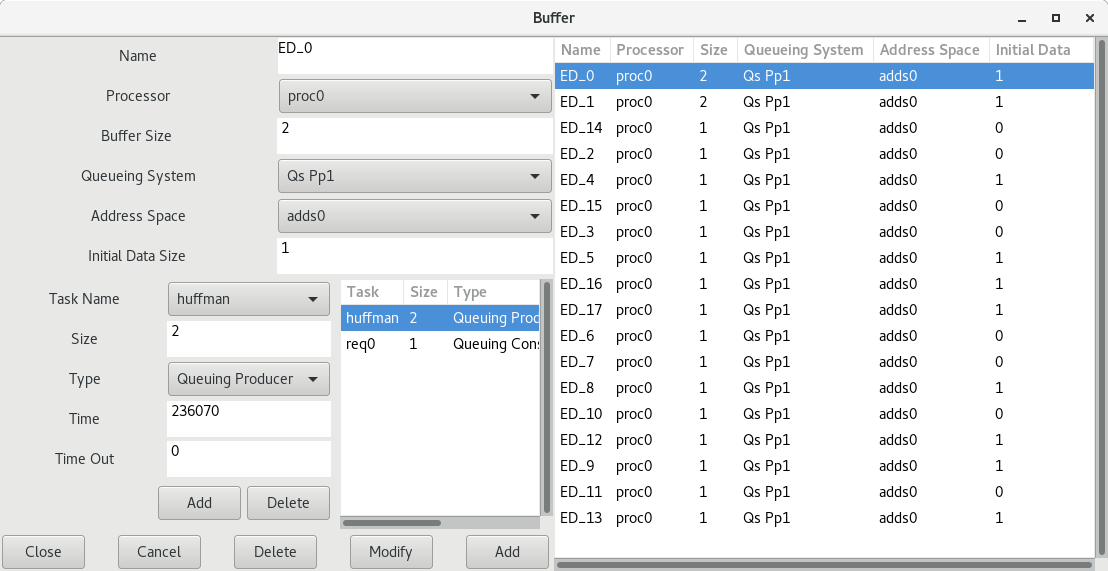
Figure 4.3 Add a new buffer
- A buffer has a unique name, size, initial data size and is hosted by a processor and an address space.
- A queueing system model is assigned to each buffer. This queueing system model describes the way buffer read and write operations will be done at simulation time. This information is also used to apply buffer feasibility tests.
- A list of tasks which access to the buffer (read or write operations). Two type of tasks can access a buffer : producers and consumers. We suppose that a producer/consumer writes/reads a fixed size of information in the buffer. For each producer or consumer, the size of the information produced or consummed have to be defined. The time of the read/write operation is also given : this time is relative to the task capacity.
- Buffer Underflow : Underflow event occurs when a task reads from a buffer and the read data size is greater than the current data size in the buffer. When it happens, a task does not read the buffer and current data in a buffer is not consumed.
- Buffer Overflow : Overflow event occurs when a task writes to a buffer and the write data size plus the current data size in the buffer is greater than Buffer Size. When it happens, a task does not write any data to the buffer.
Like tasks, two kinds of tools can be invoked by the user from a buffer : simulation and feasibility tools. At first, the simulation of the task scheduling can help the user to see how the buffer is filled or not with messages (see "Tools/Buffer/Buffer simulation" submenu). In this case, a scheduling simulation must be previously run. The result is then displayed in a window as below :
Buffer Feasibility mainly consists of computing buffer bounds. Bounds computed here suppose that each task that is defined as "producer", produces one message per periodic activation. In the same manner, each "consumer" extracts one message during each of its periodic activation.
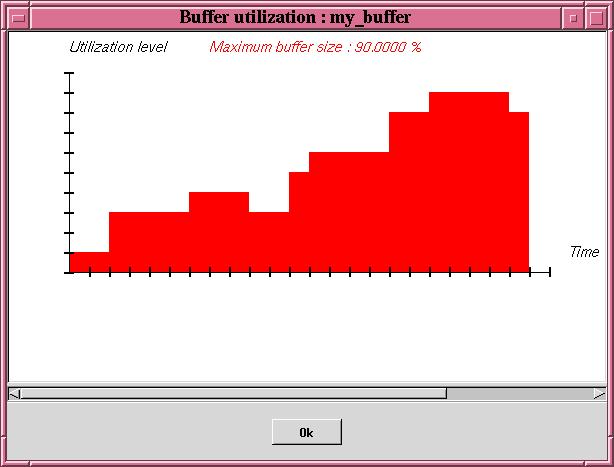
Figure 4.4 Display buffer utilization factor computed from scheduling simulation
The picture contains the buffer utilization level for each time.
Second, the feasibility tool provides a way to compute bounds on buffer utilization level. At the time we write this User's guide, bounds do not depend on the type of the scheduler. Bounds can be computed from the "Tools/Buffer/Buffer feasibility" submenu.