
TP CORBA / Mapping Java
Frank Singhoff
SOMMAIRE
Exercice supplémentaire 7 : simulateur de l’algorithme de Chang et Roberts
L'ORB que nous allons utiliser est JACORB. Cet ORB
implante les interfaces d'invocation
statique et dynamique, le mapping Java ainsi que plusieurs services d'objets de
l'OMG.
Avant de pouvoir utiliser cet ORB, vous devez mettre ŕ jour votre
environnement grâce au script corba.bash.
Ce script permet de définit
les variables nécessaires au bon fonctionnement de l'ORB. Pour
positionner ces variables, il suffit alors d'utiliser la commande source corba.bash
dans toutes les fenętres oů vous exécuterez des
processus CORBA.
Exercice 1 : premier pas
Le premier exercice consiste en un exemple simple d'application
client/serveur CORBA. L'objet hébergé par le serveur est constitué de deux
méthodes (incrementer et decrementer) définies dans l'interface IDL
calcul (fichier server.idl). Dans cet exercice, vous devez
compiler et exécuter l'application. Pour ce faire, il faut :
- Récupérez tous les
différents fichiers de cet exercice qui sont stockés dans
ce répertoire. Vous les stockerez tous dans le répertoire EXO1. Pour une compilation correcte de ce programme, il est
important de respecter les noms des répertoires.
- Depuis le répertoire EXO1, passez la commande :
make
pour générer les souches et squelettes ainsi que pour
compiler le client et le serveur. Le compilateur IDL utilisé ici se nomme idl. Le code Java généré par le
compilateur IDL est placé dans le répertoire generated/tpcorba/exo1.
Les fichiers .class sont placés
dans le répertoire classes/tpcorba/exo1.
- Lancer le serveur par la
commande jaco
tpcorba.exo1.Serveur.
- Enfin, lancer le client
par jaco tpcorba.exo1.Client num oů num est le nombre sur lequel le serveur doit effectuer le
calcul. Attention : le serveur écrit sur disque la référence de
l'objet qu'il gčre (fichier calcul.ref), il est donc
nécessaire de lancer le client et le serveur dans le męme répertoire.
On vous demande de regarder quelles sont les étapes que le serveur et le
client réalisent respectivement, pour initialiser l'objet CORBA, et pour invoquer
les méthodes de l'objet. Vous regarderez plus précisément les points
suivants :
- Quelles sont les
interactions entre le serveur et l'OA ?
- Quelle est la relation
entre la classe d'implémentation (classe calculImpl.java) et le squelette (le
squelette est défini par la classe calculPOA.java dans le répertoire generated/tpcorba/exo1) ?
- Dans la souche (classe _calculStub.java), oů se trouvent la
construction et l'émission de la requęte vers le serveur ?
- Chercher dans le squelette
(classe calculPOA.java) oů se situent les
appels ŕ l'implémentation de l'objet (classe calculImpl.java).
- Enfin, identifier dans
le fichier calcul.ref (fichier qui contient
la référence d'objet) l'adresse IP oů se trouve le serveur et le port TCP
utilisé pour les interactions entre les clients et le serveur. Vous
utiliserez ŕ cet effet la commande :
dior -f
calcul.ref
qui affiche ŕ l'écran le contenu de la référence
d'objet.
Pour vous aider, voici un bref rappel des principales rčgles du mapping IDL/Java
qui vont vous ętre nécessaires dans ce TP (le mapping complet est accessible ŕ
cet endroit)
:
- Les squelettes et les
souches sont implantés par une classe Java.
- A chaque type simple IDL
correspond un type simple Java (dans cet exercice, les types IDL long, double et string sont directement mappés en types Java int, double et String).
- Pour les signatures de
méthode avec des paramčtres en in, le mapping définit une
méthode IDL :
void methode(in type t);
en une méthode Java :
void
methode(type t);
- Pour les signatures de
méthode avec des paramčtres en out ou en inout, le mapping
définit une méthode IDL :
void
methode(out type t1, inout type t2);
en une méthode Java :
void methode(typeHolder t1, typeHolder t2);
Oů typeHolder
est une classe encapsulant une variable de type type (attribut value).
En effet, les paramčtres sont passés par copie dans Java. C'est donc le champ value de la classe typeHolder qui est utilisé pour véhiculer le
paramčtre du serveur vers le client.
Exercice 2 : attributs et exceptions
Pour cet exercice, récupérez les fichiers de ce répertoire.
Vous les stockerez tous dans le répertoire EXO2.
On se propose dans ce deuxičme exercice d'ajouter une fonctionnalité de
``mémoire'' ŕ notre calculatrice. La mémoire est implantée sous la forme d'un
attribut CORBA. On rappel qu'un attribut d'interface CORBA est une donnée
encapsulée dans un objet. Un attribut peut ętre consulté et/ou modifié ŕ
distance par un client. Dans notre cas, il s'agit d'un attribut en lecture
seule. Vous pourrez constater que l'attribut "memoire" du fichier IDL
est implanté en Java sous la forme d'une méthode du męme nom. Le client, pour
obtenir la valeur de cet attribut, doit donc invoquer cette méthode. Dans le
mapping IDL/Java, un attribut en lecture/écriture nécessite la production de
deux méthodes dans la souche. Une seule méthode est générée dans le cas d'un
attribut en lecture (voir les souches générées pour de plus amples
informations).
On vous demande de :
- Compléter la description
IDL server.idl, en ajoutant les
méthodes ajouteMemoire, soustraitMemoire, multiplieMemoire et miseAZero ŕ l'interface calcul. Chacune de ces
méthodes prend un unique paramčtre en in
de type double (sauf miseAZero qui ne prend pas de paramčtre). Elles mettent ŕ jour
la mémoire mais ne renvoient pas d'information au client. La méthode diviseMemoire doit lever une exception en cas de tentative de
division par zéro.
Une exception CORBA est un mécanisme proche d'une
exception Java : une exception CORBA est un événement déclenché lors
de l'invocation d'un objet et qui est transmis ŕ l'invoqueur de cet objet.
Invoqueur et invoqué ne sont pas nécessairement localisés sur la męme machine.
Une exception est déclarée avec le mot clef raises
dans l'IDL. Pour déclarer plusieurs exceptions dans un fichier IDL, il suffit
de les séparer par une virgule ; exemple : void
methode() raises (exception1, exception2, ...).
- Compléter la définition
de la classe d'implémentation dans le fichier calculImpl.java.
- Compléter le client afin
de tester les quatre méthodes implantées. Le client doit afficher l'état
initial de la mémoire, puis effectuer des opérations sur celle-ci. Enfin,
avant de se terminer, il devra afficher l'état final de la mémoire.
PS : Les zones de code ŕ compléter sont désignées par des étoiles.
Exercice 3 : usine ŕ objets
Nous regardons ici comment allouer dynamiquement des objets
CORBA. Pour ce faire, nous allons définir une usine ŕ objets. Une usine
ŕ objets offre des services permettant de créer et gérer dynamiquement des
objets CORBA.
Pour cet exercice, récupérez les fichiers de ce répertoire.
Vous les stockerez tous dans le répertoire EXO3.
Soit le fichier IDL server.idl. Ce fichier contient
deux interfaces :
- L'interface compte.
- Chaque objet de ce type
modélise un compte bancaire. Un compte bancaire mémorise le nom du
titulaire, le numéro du compte ainsi que son solde (cf. attributs en readonly).
- Les clients peuvent
effectuer des opérations de crédit, débit sur le compte (méthodes credit et debit).
- Les clients peuvent
virer une somme d'un compte vers un autre (méthode prelevement).
- Enfin, une méthode permet
au client de connaître le nombre de virements, d'opérations de débit et
de crédit effectués sur un compte (méthode nombre_operations).
- L'interface allocateur. La méthode nouveau_compte de cette interface
permet de créer dynamiquement un compte bancaire. La création dynamique
d'un objet CORBA nécessite les męmes opérations que la création des objets
CORBA au lancement du serveur : allocation de l'objet puis activation
auprčs de la POA grâce ŕ la méthode servant_to_reference.
Travail ŕ faire :
- Complétez les classes compteImpl.java et allocateurImpl.java qui implantent les
interfaces compte et allocateur. Les zones ŕ compléter sont signalées par des étoiles.
- Modifiez le client afin
de tester les différentes méthodes des deux interfaces CORBA (PS : le
client devra créer dynamiquement au moins deux comptes).
Exercice 4 : usines ŕ objets (2), énumérations, structures et séquences
Pour cet exercice, récupérez les fichiers de ce répertoire.
Vous les stockerez tous dans le répertoire EXO4.
Dans cet exercice, on vous demande, dans un premier, temps d'écrire un
serveur qui implante les interfaces IDL contenues dans le fichier server.idl. Dans un deuxičme temps, vous regarderez
comment sont utilisés les énumérations, les séquences et les structures IDL en
Java.
Le fichier server.idl
contient deux interfaces. L'interface abonne
mémorise les différentes informations d'un abonné ŕ un opérateur téléphonique.
L'interface gestionabonnes
assure la création/destruction/consultation des instances du type abonne. L'interface gestionabonnes contient les méthodes
suivantes :
- La méthode creation_abonne qui permet de créer un
objet CORBA de type abonne. Cet objet CORBA est
composé d'attributs identifiant un abonné (un numéro de téléphone unique,
un nom et un prénom). La référence sur l'objet CORBA créé est renvoyée au
client par le paramčtre inout
ref.
Par ailleurs, on vous demande de stocker les abonnés dans un tableau (ou
autre collection) au fur et ŕ mesure de leur création. Ainsi, lors de
l’appel ŕ la méthode creation_abonne,
vous
devrez ajouter l’objet de type abonne ŕ ce
tableau/collection. La méthode doit lever
une exception dejaExistant si le numéro de
téléphone est déjŕ utilisé.
- La méthode rechercher_abonne qui ŕ partir d'un
numéro de téléphone permet de récupérer la référence d'objet CORBA de type
abonne associé au numéro de
téléphone numero La méthode doit lever
une exception numeroInconnu si le numéro de
téléphone n'existe pas.
- La méthode resilier_abonne qui détruit l'objet
CORBA de type abonne associé au numéro de
téléphone numero. Pour détruire l'objet
CORBA, il suffit de le retirer du tableau oů vous stockez les objets de
type abonne. La méthode doit lever
une exception numeroInconnu si le numéro de
téléphone n'existe pas. Vous devez, en outre, supprimer l'objet CORBA de
la POA avec le code ci-dessous (ou ref est une référence
d'objet CORBA) :
// Desactive l'objet CORBA
//
try { byte [] ObjID = poa_.reference_to_id(ref);
poa_.deactivate_object(ObjID);
}
catch (Exception e) { System.out.println("POA Exception " + e);}
Travail ŕ faire :
- Proposez un serveur
(classes abonneImpl.java, gestionabonnesImpl.java et Serveur.java) qui implante le fichier IDL server.idl.
- Testez votre serveur
avec le client Client.java.
On souhaite enrichir les informations de cet annuaire en ajoutant pour
chaque abonné son adresse et son mode de facturation (facturation au forfait ou
selon sa consommation).
- Récupérez la
nouvelle version des fichiers suivants. Avec le compilateur IDL,
compilez server.idl. Cette nouvelle version
du fichier IDL contient un exemple de séquence, de structure et
d’énumération. Structures et énumérations sont utilisés pour mémoriser
l’adresse et le mode de facturation de l’abonné. Une séquence permet ŕ un
client d’obtenir toutes les références d’objets sur les abonnés
actuellement enregistrés.
- Quelles sont les classes
générées par le compilateur IDL pour les types type_adresse, type_abonnement
et table_abonne. A quoi servent elles ?
- Modifiez les classes
Java qui implantent les interfaces IDL en ajoutant le code nécessaire pour
les attributs adresse, abonnement et
liste_abonnes.
- Testez l’utilisation des
attributs adresse et abonnement en modifiant Client.java.
- Complétez le programme Liste.java. Ce programme client doit, grâce ŕ l’attribut liste_abonnes afficher ŕ l’écran les noms et prénoms de tous les
abonnés actuellement enregistrés.
Exercice 5 : introduction au service de désignation CORBA
Dans cet exercice, on teste le service de désignation de
CORBA dont une description simplifiée est donnée par le module IDL CosNaming. La documentation
concernant le service de désignation de CORBA est ici.
Pour cet exercice, récupérez les fichiers de ce répertoire.
Vous les stockerez tous dans le répertoire EXO5. Dans ces fichiers se trouvent
deux exemples de client/serveur utilisant le serveur de noms de CORBA.
- Compilez ces exemples
par la commande :
make
- Testez le premier
exemple grâce aux commandes suivantes :
- Lancez le serveur de
noms CORBA grâce ŕ la commande :
ns -Djacorb.naming.ior_filename=/home/xxx/ns.ref
oů /home/xxx/ns.ref
est le nom du fichier oů vous souhaitez que l'IOR du service de nom soit
mémorisé.
jaco tpcorba.exo5.Serveur -ORBInitRef NameService=file:///home/xxx/ns.ref
- Oů -ORBInitRef permet de définir ŕ quel endroit le bus ŕ objets peut
obtenir l'IOR du service de nom. Enfin, le client doit ętre lancé par :
jaco tpcorba.exo5.Client -ORBInitRef NameService=file:///home/xxx/ns.ref
·
Questions :
- Etudiez le premier
exemple constitué des fichiers Client.java et Serveur.java. Vous regarderez plus particuličrement le code
précédé par les commentaires ETAPE xxx. Décrivez le traitement
effectué lors de chacune de ces étapes.
- On regarde maintenant
le deuxičme exemple constitué des fichiers Client_contexte.java et Serveur_contexte.java. Dans Serveur_contexte.java, plusieurs contextes
sont déclarés et utilisés. Ces contextes forment une arborescence de
contextes et d'objets. Donnez cette arborescence.
- Dans Client_contexte.java, on consulte les
liaisons avec les objets CORBA de deux façons différentes : par un accčs absolu
lorsque l'on stipule le chemin complet d'un objet ŕ partir de la racine
lors d'une unique opération resolve ; par un accčs relatif
lorsque l'on effectue plusieurs opérations resolve en progressant successivement de contexte en
contexte. Dans le programme Client_contexte.java, pour chaque
commentaire LIAISON xxx, dite si la consultation de la liaison est absolue ou
relative.
Exercice 6 : construction et parcours d'une arborescence de noms
Dans cet exercice, on vous demande d'écrire un client qui utilise le service de
désignation de CORBA. Vous devez récupérer les fichiers de ce
répertoire. Vous les stockerez tous dans le
répertoire EXO6.
Question 1 :
· Le programme
Init.java crée un ensemble
d'objets de type etudiant : les
objets e1, e2, e3,
e4, e5 et e6. On
vous demande de compléter ce programme afin d'enregistrer ces objets dans
différents contextes (les contextes "Licence",
"Licence1", "Licence2", "Licence3", "Master" et "Effectifs") selon l'arborescence
suivante :
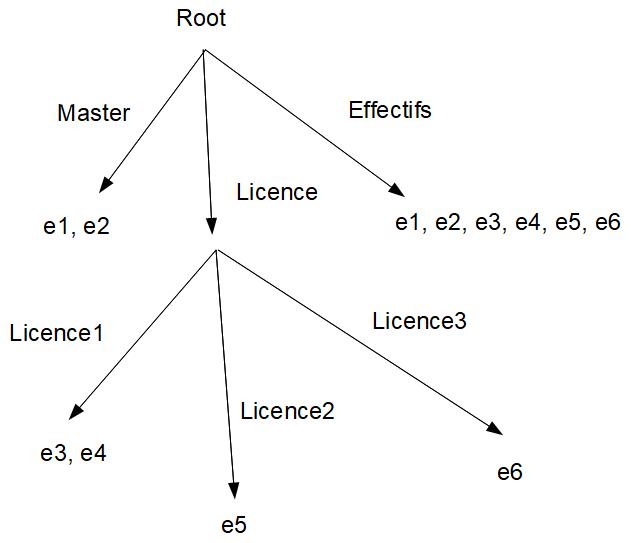
· Testez
l'arborescence construite avec le programme Init.java.
Pour ce faire, utilisez la commande :
nmg
-ORBInitRef NameService=file:///home/xxx/ns.ref
ou la commande :
lsns -ORBInitRef
NameService=file:///home/xxx/ns.ref
Ces deux outils affichent la liste des liaisons mémorisées par
un serveur de noms dont l'IOR est stocké dans le fichier /home/xxx/ns.ref.
Question 2 :
On cherche maintenant ŕ compléter un programme qui permet de parcourir une arborescence de noms.
Le programme ŕ compléter est le
fichier Cherche.java.
Ce programme permet de saisir et exécuter plusieurs commandes ŕ l'écran.
Ce programme maintient un contexte courant ŕ partir duquel l'utilisateur peut
explorer l'arborescence de noms. Les commandes disponibles sont les suivantes :
- racine. Cette commande permet de revenir ŕ la racine
de l'arborescence. Aprčs cette commande, le contexte courant est la racine de l'arborescence.
- deplacer. Cette commande permet d'aller dans un contexte accessible depuis le contexte
courant. La commande prends comme argument, soit la chaine de caractčre "..", soit un nom de contexte.
Cette commande doit conduire ŕ positionner le contexte courant vers le nom passé en
argument ou le contexte parent si la chaine de caractčre est "..".
- lister. Cette commande liste l'ensemble des bindings contenus du contexte courant.
Pour chaque binding, on vous demande d'afficher si c'est un bingding sur un contexte ou un objet.
Cette commande ne change pas le contexte courant.
- fin. Cette commande termine le programme.
Modifier le programme Cherche.java afin d'implanter les commandes
racine, lister
et deplacer.
Tester votre programme avec les programmes de la question 1.
Exercice 9 : exercice de synthčse sur l'invocation statique
On souhaite implanter un service d'accčs ŕ une bibliothčque dont l'interface IDL
est donnée ici.
Pour ce faire, on suppose que le serveur propose deux interfaces IDL : les interfaces IDL
ouvrage et bibliotheque.
L'interface ouvrage ne comporte que des attributs qui stockent
les différentes informations pour chaque ouvrage.
Les données associées ŕ chaque ouvrage sont le titre de l'ouvrage, les auteurs,
le type d'ouvrage (ex : livre, DCD, ...) ainsi
qu'un ensemble de mots clefs qui caractérisent le contenu de l'ouvrage.
Les méthodes accessibles par l'interface IDL
bibliotheque sont les suivantes :
- La méthode ajouter_ouvrage.
Cette méthode permet ŕ un client d'ajouter un ouvrage dans la bibliothčque.
Pour ce faire, le client doit fournir
le titre de l'ouvrage. Les autres informations de l'ouvrage sont renseignées ultérieurement
avec les attributs de l'interface ouvrage.
Si un client tente d'ajouter un ouvrage dont le titre est déjŕ enregistré, l'objet CORBA doit
lever l'exception deja_trouve.
- La méthode rechercher_ouvrage.
Cette méthode permet d'obtenir, sous la forme d'une séquence, toutes les
références d'objet des ouvrages qui correspondent ŕ une requęte. La requęte
en question consiste ŕ sélectionner parmi
tous les ouvrages de la bibliothčque
les ouvrages dont un des mots clefs correspond au mot passé en argument de la méthode
rechercher_ouvrage.
Si aucun titre n'a été sélectionné, l'objet CORBA doit
lever l'exception non_trouve.
Question 1 :
- Proposer un serveur qui implante chaque interface IDL.
- Proposer deux clients :
- Le client Enregistrer.java, qui permet d'enregistrer au sein du serveur un ensemble d'ouvrages,
chaque ouvrage est doit comporter plusieurs mots clefs.
Pour conduire vos tests, vous pourrez utiliser cet ensemble d'ouvrage et de mots clefs:
- Ouvrage o1, comportant les mots clefs suivants : mc1, mc2, mc3, mc4
- Ouvrage o2, mots clefs : mc1,
- Ouvrage o3, mots clefs : mc5, mc2, mc6
- Ouvrage o4, mots clefs : mc1, mc2, mc7
- Ouvrage o5, mots clefs : mc8, mc1, mc9, mc4
- Le client Rechercher.java, qui prend en argument un mot clef et qui affiche l'ensemble
des ouvrages comportant ce mot clef.
Question 2:
Dans cette deuxičme question, on souhaite utiliser le service de nom CORBA pour indexer
les mots clefs. On ré-utilise les exemples d'ouvrages et de mots clefs utilisés dans la
question 1.
Avec ces données ci-dessus, le serveur de nom CORBA doit contenir un contexte
pour chaque mot clef. Chaque contexte associé ŕ un mot clef
contient alors la référence CORBA de tous les ouvrages oů ce mot clef est utilisé.
Ainsi, le contexte dont le nom est mc4 devra contenir les références
CORBA des objets o1 et o5.
- Modifier votre serveur et le client Enregistrer.java afin de publier l'arborescence ci-dessus
lors de l'enregistrement des ouvrages.
- Utiliser nmg afin de vérifier que votre arborescence est correcte.
- Modifier Rechercher.java afin que la recherche des ouvrages correspondant au mot
clef passé en ligne de commande soit effectuée par consultation des informations mémorisées dans le serveur
de nom CORBA uniquement. Pour réaliser cette consultation, il vous fraudra utiliser un itérateur
du service de Nom CORBA.
Cet itérateur permet d'obtenir la liste des bindings mémorisés dans un objet de type
NamingContext. Ainsi, l'extrait de code ci-dessous
affiche les bindings de mon_contexte:
BindingIteratorHolder ite = new BindingIteratorHolder();
BindingListHolder dummy = new BindingListHolder();
mon_contexte.list(0, dummy, ite);
BindingHolder b = new BindingHolder();
while (ite.value.next_one(b)) {
System.out.print("ouvrage : " );
for(int l=0;l < b.value.binding_name.length;l++) {
System.out.print(b.value.binding_name[l].id);
System.out.print(b.value.binding_name[l].kind);
}
System.out.println("");
}
Exercice 10 : exercice de synthčse bis : mise en oeuvre d'un serveur de noms
On souhaite implanter un service de nom dont l'interface
est décrite dans le ficher ns.idl donné ici.
Il s'agit d'un service de noms CORBA simplifié ne comportant qu'une seule interface, l'interface
NamingContext.
Cette interface ne fournit que les méthodes suivantes : bind, rebind, bind_new_context,
rebind_new_context et resolve.
Le fonctionnement des méthodes ci-dessus sont les męmes que dans le service de nom standardisé
par CORBA. Par ailleurs :
- Comme avec le serveur de nom CORBA, le serveur de nom ŕ implanter devra initialement instancier
un objet de type NamingContext afin de représenter la racine de l'arborescence de noms.
- Lorsqu'un client souhaite se connecter au serveur de noms, il ne pourra pas utiliser la
méthode resolve_initial_references. La référence d'objet CORBA sur la racine du serveur de noms
devra ętre transmise au client par un fichier .ref
-
L'application que vous devez implanter ici
remplace donc la commande ns : ainsi, pour tester cette application, il vous faudra
lancer votre serveur (fichier NS.java) qui implante l'interface tpcorba.exo10.NamingContext
ainsi qu'un client (fichier Test_NS.java) permettant de tester ce serveur. Vous ne devez
donc pas utiliser ns, nmg ou lsns.
Question 1 :
- Compléter le serveur NS.java en fournissant une
mise en oeuvre de l'interface IDL NamingContext.
Pour cette premičre question et afin de simplifier le travail ŕ réaliser, on suppose que
le serveur n'accepte que des tableaux de NameComponent de taille 1. Si un client
invoque cette interface avec un tableau de taille supérieur ŕ 1,
alors le serveur devra lever l'exception NameComponentSizeError.
- Tester votre mise en oeuvre avec le client Test_NS.java.
Question 2 :
Modifier votre mise en oeuvre afin de fournir un mécanisme permettant de lister le contenu d'un contexte.
Question 3 :
Dans cette question, on souhaite supprimer la contrainte liée ŕ l'exception NameComponentSizeError.
Avec le service de noms CORBA, lorsqu'un tableau de NameComponent
comporte n entrées et qu'un tel tableau est utilisé
avec une méthode de NamingContext, alors les n-1 premičres entrées référencent
le nom de contextes qui doivent exister au sein du serveur de noms
et la ničme entrée contient la liaison ŕ enregistrer.
Modifier votre mise en oeuvre afin de pouvoir manipuler des
tableaux de NameComponent dont la taille est supérieure ŕ 1.
Exercice 7 : invocation dynamique
Pour cet exercice, récupérez les fichiers de ce répertoire.
Vous les stockerez tous dans le répertoire EXO7. Vous disposez d'une
application complčte (interface, client et serveur) manipulant la DII de CORBA.
- Compilez et testez cette
application.
- Identifiez dans le
client (programme Client.java.) oů se situent les invocations
du serveur. Indiquez pour chaque invocation la méthode invoquée ainsi que
les paramčtres utilisés. Ce programme est un exemple d'invocation
dynamique : en effet, il n'utilise pas de souche pour transmettre les
requętes au serveur.
- Proposez un programme
Java dont le comportement est identique ŕ Client.java mais qui utilise la méthode d'invocation statique.
Exercice 8 : utilisation d'une Interface Repository
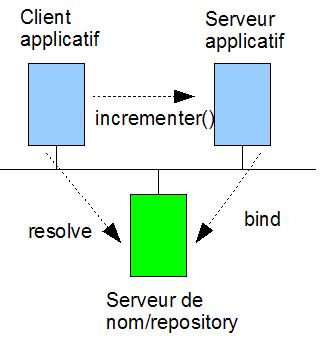
L'objectif de cet exercice est d'utiliser un service similaire ŕ l'Interface
Repository de CORBA. Le service que nous allons étudier est couplé ŕ un service
de nom. Nous illustrons l'emploi de ce service avec la DII. Cet exercice met en
oeuvre trois entités (cf. figure ci-dessus):
- Le serveur applicatif
offre un service métier quelconque. Dans cet exercice, on suppose que le
serveur applicatif implante un interface IDL offrant des services de
calcul (mini calculatrice).
- Le client applicatif
utilise les services de calcul mis ŕ disposition par le serveur
applicatif. Il invoque le serveur applicatif grâce ŕ la DII.
- Le client applicatif se
connecte au serveur applicatif via l'Interface Repository. Pour ce faire,
il utilise la méthode resolve lui permettant de
récupérer une référence d'objet ŕ partir d'un nom symbolique. D'autre
part, la méthode resolve permet au client de
récupérer une description de l'interface mise ŕ disposition par le serveur
applicatif. L'analyse de cette description permet au client, grâce ŕ la
DII, d'invoquer l'objet hébergé par le serveur applicatif sans utiliser de
souche.
- Pour que le client
puisse découvrir le service, il est nécessaire que le serveur applicatif
publie son objet ŕ l'Interface Repository avec la méthode bind. La méthode bind permet aussi au serveur
applicatif d'enregistrer auprčs de l'Interface Repository les informations
décrivant l'interface IDL qu'il met ŕ disposition.
Pour cet exercice, récupérez les fichiers de ce répertoire.
Vous les stockerez tous dans le répertoire EXO8,
puis, vous compilerez ces programmes grâce au Makefile.
Dans ce répertoire, on vous donne :
- Une
implémentation du serveur d'Interface Repository. Le serveur est lancé par
:
jaco ir.IR
- Un
serveur applicatif qui peut ętre lancé par :
jaco ir.Serveur
- Enfin, un client du
serveur de Repository qui doit ętre complété : le fichier Liste.java.
Le serveur applicatif (Serveur.java)
instancie trois objets CORBA (les objets c1,
c2 et c3). Ces objets implantent l'interface calcul (cf. application.idl). Puis, le serveur applicatif décrit
l'interface calcul grâce ŕ
l'Interface Repository. Pour ce faire, le serveur utilise les interfaces du
fichier ir.idl.
Le fichier ir.idl contient trois
interfaces mémorisant les informations contenues dans un fichier IDL:
- AttributeDescription permet de décrire les
informations d'un attribut IDL.
- OperationDescription permet de décrire les
informations d'une méthode déclarée au sein d'une interface IDL.
- InterfaceDescription permet finalement de
décrire les informations d'une interface IDL.
Enfin, une quatričme interface (interface IRepository) constitue le point d'entrée
du service. Cette derničre interface offre les services suivants :
- La méthode resolve permet, ŕ partir d'un nom symbolique (argument object_name), de récupérer sa référence (argument ref_obj) et la description de son interface (argument interface_desc).
- La méthode bind permet d'associer un nom symbolique (argument object_name) avec sa référence (argument ref_obj) et la description de son interface (argument interface_name). Aprčs la création du binding, le client récupčre une
référence d'objet lui permettant de manipuler la description de
l'interface de l'objet (argument de retour de la méthode bind). Cet argument de retour, dont le type est InterfaceDescription doit, par la suite,
ętre utilisé par le client afin de décrire les attributs et les méthodes
de l'interface. Cette description est effectuée grâce aux méthodes create_attribute et create_operation qui permettent
d'ajouter la description d'attribut et de méthode ŕ une description
d'interface.
- La méthode bind_existing_interface permet d'associer un
nom symbolique (argument object_name) avec sa
référence(argument ref_obj). Vis-ŕ-vis de la
méthode bind, on suppose que
l'interface IDL est déjŕ enregistrée dans l'Interface Repository. Le
client doit donc, lors du bind_existing_interface, donner la référence
sur la description de l'interface (argument interface_desc). La méthode bind_existing_interface permet donc
d'enregistrer plusieurs objets applicatifs de męme type (c-ŕ-d implantant
la męme interface IDL).
Question 1 :
Le programme Liste.java contient
un début de client pour l'Interface Repository. On suppose que l'on fournit en
paramčtre du programme Liste.java
(via la ligne de commande) le nom symbolique d'un objet préalablement instancié
par Serveur.java (exemple : c1 c2
ou c3).
Modifier le programme Liste.java
afin qu'il :
- Récupčre, avec resolve, la description de l'interface de l'objet dont le nom
symbolique est passé en ligne de commande.
- Affiche ŕ l'écran, grâce
ŕ l'attribut operations de l'interface InterfaceDescription, la liste des méthodes
de l'interface associée ŕ l'objet passé en ligne de commande pour le
programme Liste.java. Vous afficherez la
signature de chaque méthode (liste des arguments). Pour mettre en oeuvre
ces invocations a l'IR, vous utiliserez des invocations statiques
(utilisation d'une souche pour invoquer l'IR)
Question 2 :
Le serveur applicatif instancie des objets de type calcul. L'interface calcul
propose différents services. Ainsi, calcul
propose des méthodes pour additionner deux doubles (méthode plus), soustraire deux doubles (méthode moins), multiplier deux doubles (méthode multiplie) et diviser deux doubles
(méthode divise).
Proposez un deuxičme programme Java (Invoque.java)
qui :
- Récupčre une référence
sur un objet instancié par Serveur.java dont le nom est passé
en ligne de commande.
- Invite l'utilisateur ŕ
saisir le nom de la méthode ŕ invoquer (qui peut ętre soit plus, soit moins, soit multiple soit divise).
- Invite l'utilisateur ŕ
saisir deux doubles (paramčtres de la méthode ŕ invoquer).
- Invoque la méthode
choisie avec ses deux paramčtres, puis finalement, affiche le résultat du
calcul. Pour cette invocation vous ne devez pas employer de souche : la
requęte doit ętre construite avec la DII.
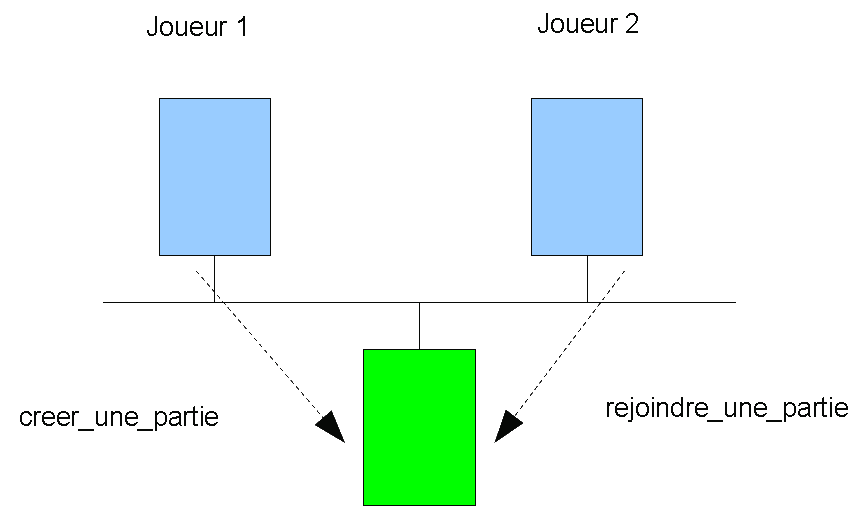
Exercice supplémentaire 1 : mise en oeuvre d'un jeu de monopoly
Les fichiers associés ŕ ce projet sont disponible dans ce répertoire.
L'objectif du CC est de réaliser un jeu de Monopoly. Vous trouverez sur Wikipedia
toutes les informations nécessaires concernant les rčgles de ce jeu. Toutefois,
il existe de nombreuses variations de ce jeu, tant sur les rčgles que sur les
cases du plateau. Pour ce projet, vous ętes libre d’implanter les rčgles de
votre choix.
L'application ŕ réaliser est constituée de plusieurs entités
(cf. figure ci-dessus) :
-
Une entité par joueur. Il peut y avoir plusieurs joueurs.
-
Et une entité qui gčre
le déroulement de la partie : il s'agit du gestionnaire de parties.
Le gestionnaire de parties est un serveur CORBA. Ce serveur
implante les interfaces IDL partie
et gestionnaire_de_parties. Vous
trouverez une ébauche de ces interfaces IDL dans le fichier
monopoly.idl. L'interface
gestionnaire_de_parties constitue le point
d'entrée de l'application. Les objets CORBA partie
sont alloués ŕ la demande des joueurs. Ce fichier IDL doit vous servir de point
de départ pour réaliser votre projet : vous pouvez le modifier selon vos
besoins. Vous serez d'ailleurs obligé de le compléter afin de déterminer
comment le jeu mémorise les différentes données associées ŕ une partie et
comment les joueurs peuvent transmettre leurs données au gestionnaire de
parties.
Chaque entité associée ŕ un joueur est ŕ la fois un serveur CORBA et un client
CORBA. En effet, chaque joueur instancie un objet CORBA de type
joueur (cf. fichier IDL
monopoly.idl) et invoque les objets CORBA
du gestionnaire de parties. Les objets CORBA joueur
sont invoqués par le gestionnaire de parties afin de transmettre différents
messages aux joueurs. Les messages sont simplement affichés ŕ l'écran et soit
informe le joueur du déroulement de la partie, soit l’invite ŕ faire une
action. Par exemple, lorsque le gestionnaire de partie envoie un message ŕ un
joueur lui indiquant que c’est son tour de jouer, le joueur lance un dčs et
indique au gestionnaire de parties l’action qu’il souhaite faire (ex:
acheter une gare). Chaque joueur est aussi un client CORBA car il invoque les
méthodes des objets partie et gestionnaire_de_parties du gestionnaire de
parties.
Pour la mise en oeuvre des joueurs, vous devez utiliser la
classe Orb_Run.java. La classe Orb_Run.java
démarre une POA de façon non
bloquante et permet au joueur d'invoquer le gestionnaire de parties une fois
que l'objet joueur CORBA est
correctement initialisé. Le fichier JoueurProcess.java
illustre ce fonctionnement. La structure du programme utilisé par un joueur est
donc la suivante :
- Initialiser un ORB et
une POA.
- Instancier un objet joueur, puis la classe Orb_Run.java
afin de pouvoir servir les requętes sur l'objet joueur.
- Invoquer les méthodes
des interfaces/objets partie et gestionnaire_de_parties
pendant le déroulement
d'une partie.
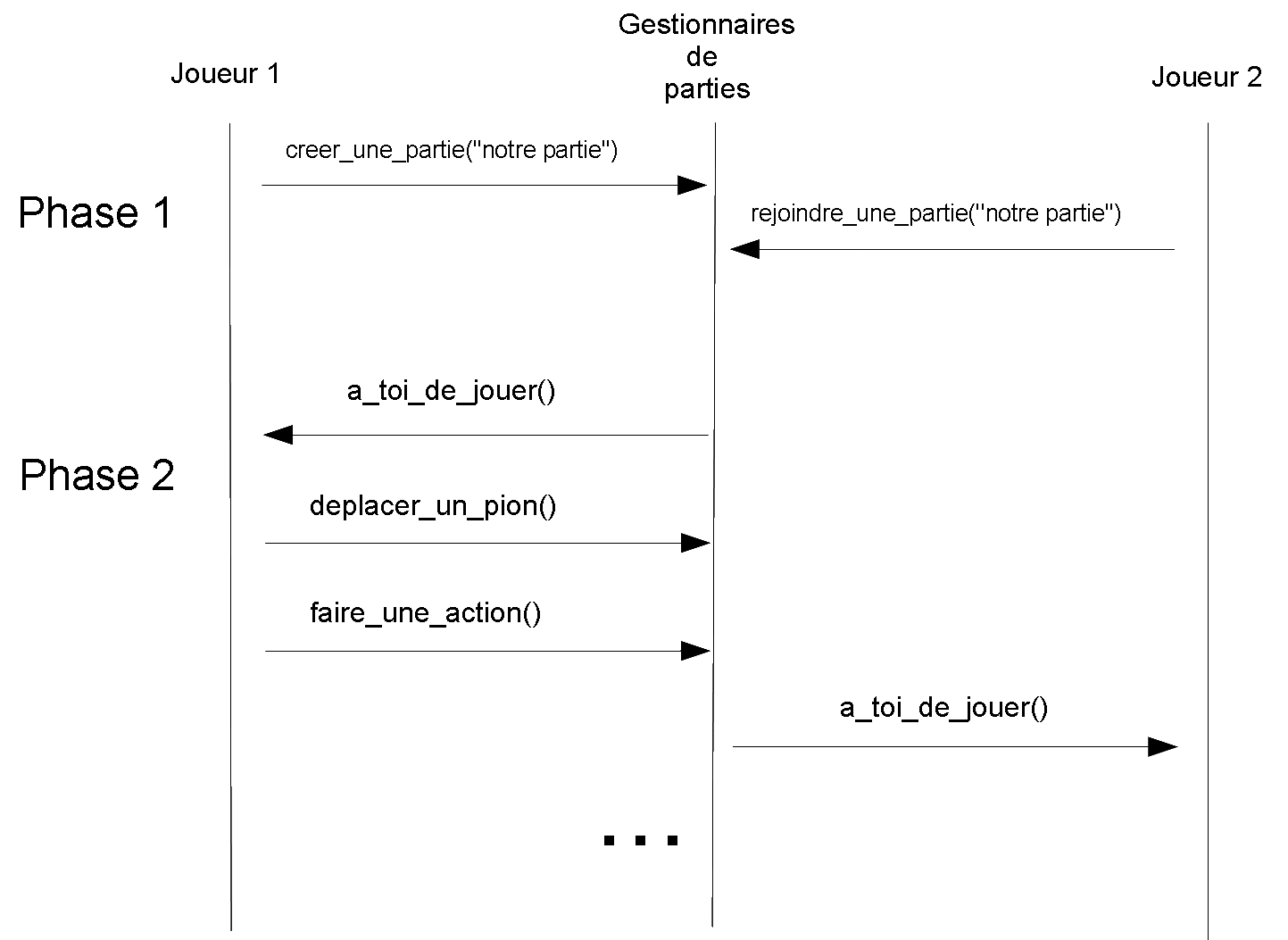
Le diagramme de séquence ci-dessus décrit le fonctionnement général de l'application
ŕ réaliser. Le déroulement d'une partie s'effectue en deux phases :
- Phase 1: initialisation
de la partie.
Le gestionnaire de parties commence par instancier l'interface gestionnaire_de_parties, puis, attend l'arrivée
des joueurs. Le premier joueur demande la création d'une partie. Puis, les
suivants s'enregistrent auprčs du gestionnaire pour une partie donnée.
Chaque partie est identifiée par un nom. Lorsqu'un joueur s'enregistre, il
donne au serveur une référence d'objet sur son objet CORBA de type joueur.
- Phase 2: déroulement de
la partie.
Une fois que tous les joueurs sont connus par le gestionnaire de parties,
alors celui-ci invite un participant ŕ jouer. Le protocole entre un joueur
et le gestionnaire de parties est le suivant:
- Le gestionnaire de
partie envoie une invitation au joueur. Cette invitation consiste ŕ
envoyer un message au joueur grâce ŕ la méthode
a_toi_de_jouer
-
En réponse ŕ ce
message, le joueur simule un lancer de dés, puis, déplace son pion
grâce ŕ la méthode deplacer_un_pion.
- La demande de
déplacement du pion par le joueur conduit le gestionnaire de parties ŕ lui
indiquer une éventuelle action qu'il peut réaliser. Le joueur peut par la
suite indiquer au serveur de parties s'il souhaite faire (ou non) cette
action.
- Enfin, lorsque cet
échange entre le joueur et le gestionnaire de partie est achevé, le
gestionnaire de partie passe au joueur suivant.
Travail ŕ faire :
On vous demande :
De proposer des interfaces IDL qui permettent aux différentes entités
d'échanger les données nécessaires ŕ ce jeu (ex : position des joueurs,
rues/gares/maisons/argent détenus pour chaque joueur, informations
diverses sur l'état de la partie, ...).
De proposer une mise en oeuvre des différentes interfaces IDL et du
protocole de communication entre le gestionnaire de parties et les joueurs.
Vous ętes libre d’adapter le fichier IDL ainsi que le protocole de
communication entre le gestionnaire de parties et les joueurs comme bon vous
semble.
Exercice supplémentaire 2 : usine ŕ calculatrice
Pour cet exercice, dans un nouveau répertoire,
récupérez les fichiers suivants : Makefile,
Client.java, calcul_Impl.java, usine_Impl.java, Calculatrice.java, et tpcorba.idl. Vous les
stockerez tous dans un répertoire commun.
On revient sur notre calculatrice mais, maintenant, le serveur doit gérer un
ensemble de calculatrices. Pour chaque calculatrice, il maintient une référence
sur l'objet CORBA, un identifiant (un nom sous la forme d'une chaîne de
caractčres utilisée par les clients pour désigner une calculatrice
particuličre) ainsi qu'un nombre d'utilisateurs (nombre de clients qui
manipulent la calculatrice). Ces informations doivent ętre encapsulées dans des
instances de la classe Calculatrice.java.
L'objectif est de permettre au client de créer et détruire des calculatrices ;
mais aussi d'utiliser des calculatrices précédemment créées par d'autres
clients.
Dans cet exercice, il vous est demandé de :
- Rappel : pour déclarer
plusieurs exceptions dans un fichier IDL, il suffit de les séparer par une
virgule ; exemple : void
methode() raises (exception1, exception2, ...).
Modifier le fichier tpcorba.idl. en rédigeant pour
l'interface usine les quatre méthodes
suivantes (n'oubliez pas de déclarer les exceptions utilisées par chaque
méthode) :
- La méthode creation qui prend un premier paramčtre en inout contenant une référence sur un objet ``calcul'' ainsi
qu'un deuxičme paramčtre en in de type string désignant le nom de la calculatrice ŕ créer. Cette
méthode doit créer une nouvelle instance de la classe calcul_impl. Elle doit permettre au client d'obtenir une
référence sur le nouvel objet CORBA créé. La méthode doit lever une
exception (dont le nom sera calculatriceDejaExistante) si l'objet demandé
existe déjŕ. On souhaite que le serveur crée un nombre de calculatrice
inférieur ŕ un paramčtre donné lors du lancement du serveur. Si le nombre
d'objet maximal est atteint, le serveur ne crée pas d'objet et lčve
l'exception plusDePlace.
- La méthode suppression qui prend un paramčtre en in de type string désignant le nom de la
calculatrice ŕ détruire. L'objet CORBA pourra ętre désactivé grâce ŕ la
méthode deactivate_obj de la BOA (cette
méthode nécessite un seul paramčtre : une référence d'objet
CORBA). La méthode doit lever une exception si l'objet ŕ supprimer est
encore utilisé ; c'est ŕ dire si le nombre d'utilisateurs associé ŕ
l'objet est différent de zéro. Le nom de cette exception est calculatriceEnUtilisation. De męme, si le
paramčtre string adresse une
calculatrice inexistante, le serveur lčve l'exception calculatriceInconnue.
- La méthode connecter qui prend un paramčtre en inout contenant une référence sur l'objet CORBA ainsi qu'un
deuxičme paramčtre en in de type string désignant le nom de la calculatrice concernée. Cette
méthode doit incrémenter le nombre d'utilisateurs associé ŕ une
calculatrice. Par contre, elle ne crée pas d'objet CORBA : elle
permet d'avertir l'usine ŕ objets qu'un client souhaite utiliser une
calculatrice déjŕ existante. Elle doit permettre au client d'obtenir une
référence sur l'objet CORBA concerné. La méthode doit lever une exception
si le paramčtre string adresse une
calculatrice inexistante (exception calculatriceInconnue).
- La méthode deconnecter qui prend un paramčtre en in de type string désignant le nom de la
calculatrice concernée. Cette méthode ``déconnecte'' un utilisateur d'une
calculatrice. Elle permet d'avertir l'usine ŕ objets que le client ne
souhaite plus utiliser la calculatrice. La méthode doit lever l'exception
aucunUtilisateur si l'objet n'a déjŕ
plus d'utilisateur (c'est ŕ dire si le nombre d'utilisateur associé ŕ
l'objet est égal ŕ zéro). Si le paramčtre string adresse une calculatrice inexistante, l'exception calculatriceInconnue est levée.
- Complétez l'implantation
des interfaces usine et calcul (c'est ŕ dire les fichiers usine_Impl.java et calcul_Impl.java ).
- Ecrire un serveur
permettant de lancer l'usine ŕ objets. Le nombre de calculatrices que le
serveur peut allouer durant son fonctionnement doit ętre précisé par
l'utilisateur lors du lancement du serveur.
- Tester votre application
avec le client.
Exercice supplémentaire 3 : le jeu du trivial pursuit
Pour cet exercice, dans un nouveau répertoire,
récupérez les fichiers suivants : trivial.idl,
Orb_Run.java,
Dans cet exercice, on souhaite implanter le jeu du trivial pursuit. Ce jeu peut
ętre joué par plusieurs joueurs. Il consiste ŕ répondre chacun son tour ŕ une
question. Le premier joueur qui a repondu convenablement ŕ six questions remporte
la partie (chaque bonne réponse permet au joueur de remporter un camembert ; la
victoire d'un joueur est donc atteinte lorsqu'il détient 6 fromages !). Les
questions sont triées par catégories (ex : sports, sciences, géographie ...).
On suppose ici que le joueur peut choisir la catégorie lorsqu'on lui pose une
question.
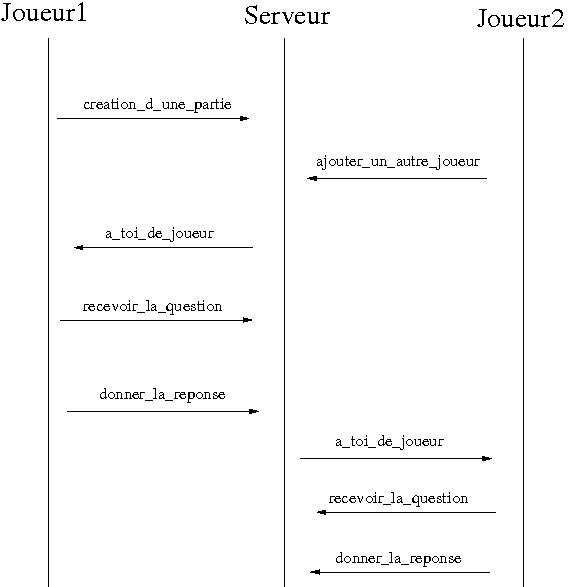
L'application est composée d'un serveur de parties et d'un ensemble de joueurs.
Le serveur de parties stocke l'état de la partie de trivial pursuit. Il s'agit
d'un serveur CORBA qui gčre des objets CORBA de type partie et jeux.
L'interface jeux constitue le
point d'entrée de l'application. Les objets CORBA partie sont alloués ŕ la demande des joueurs.
Chaque joueur est un serveur CORBA car il instancie un objet de type joueur. Le joueur est aussi un client
CORBA car il invoque les méthodes des objets partie
et jeux du serveur de parties.
Vous devez utiliser la classe Orb_Run.java
pour démarrer la POA de façon non bloquante afin que le joueur puisse invoquer
le serveur de parties une fois que son objet CORBA est initialisé. Cette classe
implante un thread dont le rôle est de servir les requętes sur l'objet de type joueur.
Le diagramme de séquence ci-dessus décrit le fonctionnement général de
l'application avec deux joueurs. Le serveur de parties commence par instancier
l'interface jeux, puis, attend
l'arrivée des joueurs. Le premier joueur demande la création d'une partie au
serveur de parties. Puis, le deuxičme joueur s'enregistre auprčs du serveur.
Lorsqu'un joueur s'enregistre, il donne au serveur une référence d'objet sur
son objet CORBA de type joueur.
Une fois que tous les joueurs sont connus par le serveur de parties, alors
celui-ci invite un des joueurs ŕ jouer. Cette invitation consiste ŕ envoyer un
message au joueur grâce ŕ la méthode a_toi_de_jouer.
En réponse ŕ ce message, le joueur concerné récupčre la question grâce ŕ la
méthode recevoir_la_question et
renvoie sa réponse grâce ŕ la méthode donner_la_reponse.
Le serveur informe alors le joueur du nombre de points (ou camemberts) qu'il a
gagné puis, passe au joueur suivant.
Exercice supplémentaire 4 : event services avec type any
Voir le répertoire EXOSUPP4.
XVII.
Projet CC/SOR 2014/2015 : mise en śuvre d’un jeu de dames
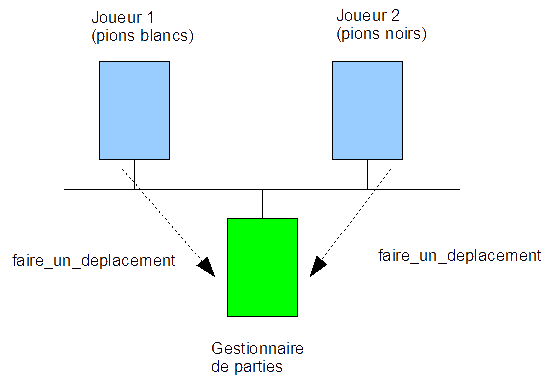
L'objectif du CC est de réaliser un jeu de dames. Vous trouverez sur Wikipedia
toutes les informations nécessaires concernant les rčgles de ce jeu. L'application
ŕ réaliser est constituée de 3 entités (cf. figure ci-dessus) :
- Les deux premičres
entités sont les joueurs de dames. Chaque joueur dispose de pions de
couleur noir ou blanc.
- La troisičme entité gčre
le déroulement de la partie : il s'agit du gestionnaire de parties.
Le gestionnaire de parties est un serveur CORBA. Ce serveur
implante les interfaces IDL partie
et gestionnaire_de_parties. Vous
trouverez une ébauche de ces interfaces IDL dans le fichier dames.idl. L'interface gestionnaire_de_parties constitue le point
d'entrée de l'application. Les objets CORBA partie
sont alloués ŕ la demande des joueurs. Ce fichier IDL doit vous servir de point
de départ pour réaliser votre projet : vous pouvez le modifier selon vos
besoins. Vous serez d'ailleurs obligé de le compléter afin de déterminer
comment le jeu mémorise les différentes données associées ŕ une partie et
comment les demandes de déplacement de pions d'un joueur peuvent ętre
transmises au gestionnaire de parties.
Chaque joueur est ŕ la fois un serveur CORBA et un client CORBA. En effet,
chaque joueur instancie un objet de type joueur
(cf. fichier IDL dames.idl). Ces
objets CORBA joueur sont
invoqués par le gestionnaire de parties afin de transmettre un message aux
joueurs. Le message doit simplement ętre affiché ŕ l'écran afin d'avertir le
joueur du déroulement de la partie. Chaque joueur est aussi un client CORBA car
il invoque les méthodes des objets partie
et gestionnaire_de_parties du
gestionnaire de parties. Pour la mise en oeuvre des joueurs, vous devez
utiliser la classe Orb_Run.java.
La classe Orb_Run.java démarre
une POA de façon non bloquante et permet au joueur d'invoquer le gestionnaire
de parties une fois que l'objet joueur
CORBA est correctement initialisé. La structure du programme utilisé par un
joueur est donc la suivante :
- Initialiser un ORB et
une POA.
- Instancier un objet joueur, puis la classe Orb_Run.java
afin de pouvoir servir les requętes sur l'objet joueur.
- Invoquer les méthodes
des interfaces/objets partie et gestionnaire_de_parties pendant le déroulement
d'une partie.
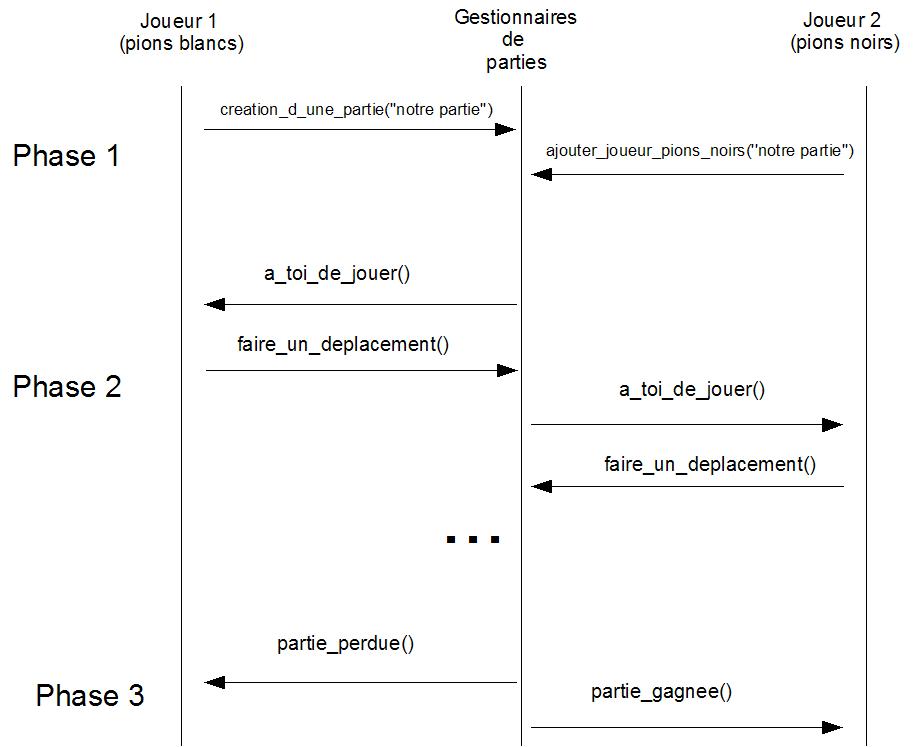
Le diagramme de séquence ci-dessus décrit le fonctionnement général de
l'application ŕ réaliser. Le déroulement d'une partie s'effectue en trois
phases :
- Phase 1: initialisation
de la partie.
Le gestionnaire de parties commence par instancier l'interface gestionnaire_de_parties, puis, attend l'arrivée
des joueurs. Le premier joueur demande la création d'une partie. Puis, le
deuxičme joueur s'enregistre auprčs du gestionnaire. Lorsqu'un joueur
s'enregistre, il donne au serveur une référence d'objet sur son objet
CORBA de type joueur.
- Phase 2: déroulement de
la partie.
Une fois que tous les joueurs sont connus par le gestionnaire de parties,
alors celui-ci invite le joueur ayant des pions blancs ŕ jouer. Cette
invitation consiste ŕ envoyer un message au joueur grâce ŕ la méthode a_toi_de_jouer. En réponse ŕ ce message, le joueur concerné propose
un déplacement de pions grâce ŕ la méthode faire_un_déplacement. Le serveur effectue le
déplacement, puis, vérifie si la partie est terminée. Le cas échéant, il
invite le joueur suivant ŕ jouer.
- Phase 3: fin de la
partie.
Aprčs chaque déplacement, le gestionnaire de partie doit vérifier si la
partie est terminée. Si la partie est terminée, alors il avertit le
gagnant et le perdant en invoquant les méthodes partie_perdue et partie_gagnee respectivement. La
partie est alors finie.
Travail ŕ faire :
On vous demande :
· De proposer
une interface IDL qui permette aux différentes entités d'échanger les données
nécessaires (ex : position des pions lors d'un déplacement, information sur
l'état du jeu, ...).
· De proposer
une mise en oeuvre des trois entités.
Vous pouvez travailler seul ou en binome. Le projet est ŕ rendre par mail ŕ
Frank Singhoff pour le 9 mars au plus tard. On vous demande de faire un
mini-rapport dans lequel vous décrirez le mode d'emploi de votre logiciel, ses
fonctionnalités ainsi que sa conception (structure du logiciel). Vous serez
évalué sur :
- La qualité du rapport : description de la conception
(sa structure, l'interface IDL par exemple),
le manuel d'utilisation, les tests effectués => pas de jeu de tests, pas de note.
- Le logiciel réalisé :
ses fonctionnalités, la propreté du code, sa conception (structure), sa
fiabilité.
- Sur la démonstration que
vous effectuerez le 9 mars.
Exercice supplémentaire 6 : simulation d'une ruche
XVIII.1 Architecture de l’application répartie ŕ
implanter
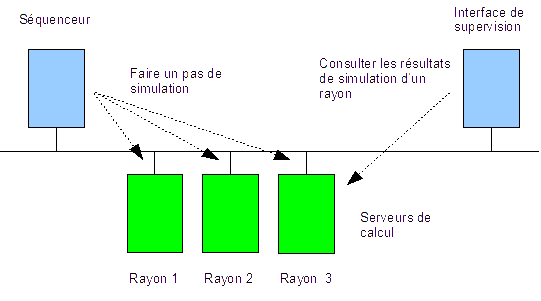
L'objectif du CC est de réaliser un outil de simulation. L’outil de simulation
offre des moyens pour étudier le comportement d’une ruche. La figure ci-dessus
décrit l’architecture de l’environnement de simulation. Cette architecture est
constituée de 3 composants :
- Les serveurs de
calcul : leur nombre dépend de la simulation ŕ effectuer. Pour cet
exercice, on suppose que 3 serveurs de calcul sont utilisés.
- Le séquenceur : il
contrôle et commande les serveurs de calcul afin de conduire la
simulation.
- L’interface de
supervision : cette interface récupčre réguličrement chez les
serveurs de calcul, les résultats de la simulation et les présente ŕ
l’utilisateur.
- L’interface de
supervision et le séquenceur sont des clients CORBA. Le dialogue entre ces
clients et les serveurs de calcul s’opčre grâce aux interfaces IDL
stockées dans le fichier ruches.idl.
XVIII.2 Phénomčne que l’on cherche ŕ simuler
On cherche ŕ simuler le comportement d’une ruche. Une ruche
est constituée de plusieurs rayons. Chaque rayon contient des cellules. On
suppose qu’un rayon est un tableau de 1000 cellules (50 cellules en largeur sur
20 cellules en hauteur). Une cellule peut:
- Etre vide.
- Contenir du miel. En
général, les cellules contenant du miel sont sur la partie haute du rayon.
- Contenir du pollen. En
général, les cellules contenant du pollen sont sur la partie haute du
rayon.
- Contenir une larve
d’abeille. La larve passe par plusieurs phases. Au jour J, la reine pond
un śuf dans la cellule. A J+3, l’śuf éclot et donne naissance ŕ un
asticot. A J+8, la cellule est operculée. On suppose qu’ŕ J+8, la larve
consomme une cellule de miel et la moitié d’une cellule de pollen juste avant
que sa cellule soit operculée. A J+21, l’abeille adulte sort de la cellule
(on dit qu’elle émerge) et la cellule et donc ŕ nouveau vide, pręte ŕ
accueillir un nouvel śuf.
On suppose par ailleurs que :
- Au démarrage de la
simulation, un rayon ne contient que des cellules vides et un certain
nombre de cellules pleines de miel et de pollen.
- La reine pond par jour
entre 3 et 5 śufs sur chaque rayon. La reine pond en priorité dans les
cellules vides adjacentes aux śufs déjŕ présents dans le rayon. Par contre,
si le rayon ne contient aucun śuf, alors la reine pond dans n’importe
quelle cellule vide du rayon.
- Lorsque du pollen ou du
miel rentre dans la ruche et doit ętre stocké dans un rayon, il doit ętre
stocké dans la partie la plus haute du rayon contenant des cellules vides.
XVIII.3 Déroulement d’une simulation
Une simulation se déroule de la façon suivante :
- Les 3 serveurs de calcul
sont d’abord démarrés, puis, le séquenceur est initialisé.
- Le séquenceur envoie
ensuite ŕ chaque serveur de calcul les données initiales. Ici, les données
initiales sont l’état de chaque rayon. Spécifier l’état d’un rayon
consiste ŕ spécifier l’état de chacune de ses cellules.
- Puis, le séquenceur
instancie autant de threads que de serveurs de calcul (et donc de rayons).
- La simulation est
itérative et est guidée par le temps : chaque itération représente
l’écoulement d’une unité de temps (jours, minutes, années selon le
phénomčne simulé). Dans notre cas, une itération (aussi appelé
« pas de simulation ») représente l’écoulement d’un jour dans la
ruche. La simulation itérative est conduite par le séquenceur comme
suit :
- Le séquenceur démarre
l’itération n
de la simulation en demandant ŕ chacun de ses threads d’invoquer la
méthode faire_un_pas_de_simulation du serveur de calcul
associé. Calculer une itération d’un rayon de la ruche consiste ŕ faire
évoluer chaque cellule du rayon, c’est ŕ dire :
- Vieillir les śufs et
asticots déjŕ présents. Faire naître les abeilles prętes ŕ naître.
- Pondre (si possible)
les nouveaux śufs. Si toutes les cellules sont pleines sur le rayon,
alors les śufs ne sont pas pondus et sont perdus.
- Stocker (si possible)
les nouvelles cellules de miel. Si toutes les cellules sont pleines sur
le rayon, alors les nouvelles cellules de miel récoltées sont perdues.
- Stocker (si possible)
les nouvelles cellules de pollen. Si toutes les cellules sont pleines
sur le rayon, alors les nouvelles cellules de pollen récoltées sont
perdues.
- …
- Lorsque la méthode faire_un_pas_de_simulation est terminée pour tous
les rayons, le séquenceur demande ŕ ses threads de lancer l’itération n+1.
La
simulation progresse donc au męme rythme pour tous les rayons: c’est une
simulation dite « synchrone ».
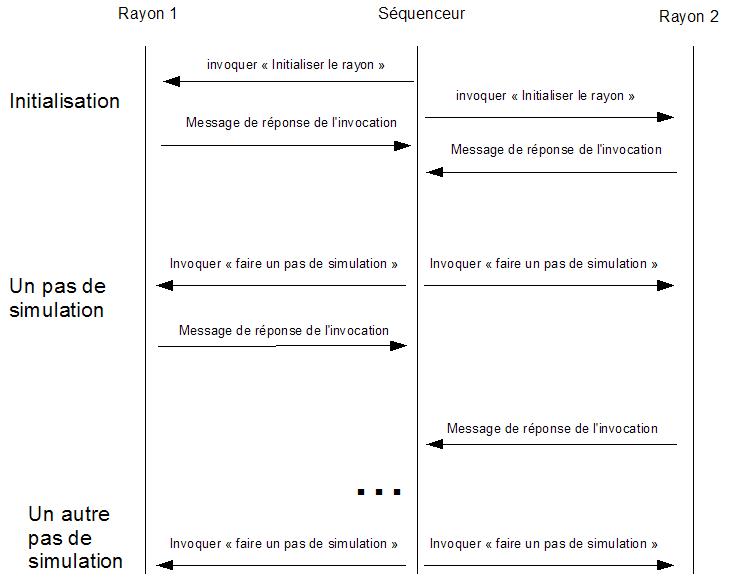
Le diagramme de séquence ci-dessus résume les différents échanges de message
durant une simulation. On peut bien sur imaginer que le séquenceur guide la
simulation avec d’autres primitives plus élaborées. Ainsi, la primitive simuler_jqa de ruches.idl
doit permettre de faire tourner la simulation pendant plusieurs jours.
- L’interface de
supervision peut ętre lancée ŕ tout moment, ŕ la demande l’utilisateur.
L’interface de supervision doit pouvoir interroger les différents serveurs
de calcul, ŕ la demande de l’utilisateur, afin de récupérer les résultats
de simulation pour chaque rayon (population d’abeilles, śufs, larves,
miels, …).
XVIII.4 Travail ŕ faire :
On vous demande :
- De proposer des
interfaces IDL qui permette aux différentes entités d'échanger les données
nécessaires ŕ la mise en śuvre des simulations. Ainsi, deux interfaces
doivent ętre proposées par rayon :
1. une premičre interface
qui modélise les données d’un rayon afin que l’interface de supervision puisse
les récupérer (population d’abeille, miel et pollen perdus, nombre de larves,
nombre d’śufs pondus et perdus, position des śufs/larves/miel/pollen sur le
rayon, …).
2. une deuxičme interface
qui permette de contrôler les simulations de chaque rayon, interface utilisée
par le séquenceur.
- De proposer une mise en
oeuvre des trois entités (séquenceur, serveurs de calcul et interface de
supervision).
Exercice supplémentaire 7 : Simulateur de l’algorithme de Chang et Roberts avec
CORBA
Cet exercice est noté et constitue la note de projet de l'UE Systčmes
répartis. Vous pouvez travailler seul ou en binome. Le projet est ŕ rendre par
mail ŕ Frank Singhoff le 25 mars au plus tard. On vous demande de faire un
rapport de deux pages maximum dans lequel vous décrirez le mode d'emploi
de votre logiciel, ses fonctionnalités ainsi que sa conception (structure du
logiciel). Vous serez évalué sur :
- Le logiciel réalisé :
ses fonctionnalités, la propreté du code, sa conception (structure), sa
fiabilité.
- La qualité du rapport.
- La qualité du jeu de
tests.
Nous nous contenterons ici de résumer le principe de
l'algorithme d’élection de Chang et Roberts :
- Cet algorithme suppose
que chaque processus possčde un identifiant unique (ou UID par la suite)
et que les processus sont organisés en un anneau unidirectionnel.
- Un (ou plusieurs)
processus initialisent une élection en envoyant un message ŕ leur voisin
dans l’anneau. Ce message contient l’IUD du processus émetteur.
- Le processus récepteur
compare l’UID reçu avec son propre UID. Si les UID sont égaux, alors le
processus récepteur est élu, sinon, il transmet ŕ son voisin le plus
grand des deux numéros.
- Dans un deuxičme temps,
le processus élu diffuse alors aux autres processus son UID afin de
communiquer ŕ tous les processus le processus élu.
Travail ŕ faire :
On vous demande de proposer une
application Java/CORBA qui implante l’algorithme ci-dessus.
- Le
programme Java simule une des machines du systčme réparti. Les machines sont
organisées en anneau unidirectionnel. Pour ce faire, le programme Java sera
lancé autant de fois que de machine dans l’anneau. Chaque machine simulée par
le programme CORBA doit avoir son UID (qui est un entier) et qui peut ętre
obtenu, par exemple, grâce ŕ un argument en ligne de commande.
- Chaque
programme hébergera un objet CORBA qui permet ŕ un programme d’envoyer un
entier (l’UID) ŕ la machine successeur.
- Chaque
programme sera donc ŕ la fois client et serveur CORBA : client car il peut
envoyer un entier sur la demande de l’utilisateur et serveur car il peut
recevoir simultanément l’identifiant d’un autre programme.
- L’élection
est déclenchée par l’utilisateur grâce au clavier.
- Chaque
programme doit afficher toutes les secondes s’il est la machine élue.
- Vous
devrez utiliser la classe Orb_Run.java.
Instancier la classe Orb_Run.java
permet de démarrer une POA de façon non bloquante, ce qui permettra au
programme Java de lire les saisies clavier tout en servant simultanément les
requętes CORBA. Le fonctionnement du programme sera le suivant :
1. Le programme commence
par initialiser l’objet CORBA permettant aux différentes machines de dialoguer.
2. Puis, il lance une POA
non bloquante.
3. Enfin, il attend la
saisie au clavier d’un caractčre qui va déclencher l’algorithme d’élection.
- Vous
testerez votre programme avec un anneau de 3 machines au moins.
Quand un processus tombe en panne (par
exemple, quand un processus est arręté par l’utilisateur), la boucle de
machines est brisée. On vous demande de modifier votre mise en śuvre de sorte
que les machines vérifient périodiquement la panne de leur successeur. En cas
de panne d’une machine, son prédécesseur doit reconstruire la boucle en se
connectant au successeur de la machine en panne. Lorsque la boucle est
reconstituée, une phase d’élection doit ętre automatiquement déclenchée.
Modifiez votre programme CORBA de
sorte que :
- La panne
d’un programme peut ętre détecté grâce ŕ CORBA : un programme qui invoque
son successeur reçoit au bout de quelques secondes une exception org.omg.CORBA.TRANSIENT si celui-ci
est en panne.
- On
suppose qu’une seule panne arrive dans le systčme : lorsqu’une machine en
panne est détectée, on suppose qu’aucune panne supplémentaire ne peut
intervenir. Votre solution devra donc proposer une solution lorsque le systčme
est victime d’une panne de machine au maximum.
- Vous
testerez cette nouvelle mise en śuvre avec un anneau de 3 machines au moins.
Exercice supplémentaire 8 : mise en śuvre d’un protocole de cache mémoire
Nous nous contenterons ici de résumer le principe de
l'algorithme réparti par diffusion de Kai Li et Paul Hudak.
Principes de l'algorithme
L'objectif de cet algorithme est de permettre ŕ des
processeurs faiblement couplés de partager des données par un systčme de
mémoire partagée répartie, en s'assurant que cette mémoire est cohérente. Pour
Li et Hudak, une mémoire est cohérente si une opération de lecture ŕ une
adresse retourne toujours la derničre valeur écrite ŕ cette adresse, quels que
soient les processeurs effectuant ces opérations de lecture et d'écriture.
Cet algorithme met en jeu un ensemble de processus qui
s'exécutent sur des sites distincts, qui ne peuvent pas avoir de défaillances.
Ces sites sont faiblement couplés, en ce sens qu'ils ne peuvent s'échanger des
informations que sous forme de messages transmis par un canal de communication
asynchrone.
Cet algorithme s'appuie sur deux types de communication. Un
message envoyé en diffusion est reçu par tous les sites impliqués dans
l'algorithme. Un message envoyé en point ŕ point ŕ un émetteur unique et un
destinataire unique.
Un ensemble de processus se partagent des pages de mémoire.
Les accčs aux pages peuvent se faire en lecture ou en écriture ; ŕ tout moment,
sur une page donnée, il peut y avoir plusieurs lecteurs ou exclusivement un
seul rédacteur. Un défaut de page est donc effectué soit en lecture, soit en
écriture.
Pour chaque page, ŕ un moment quelconque, il existe un site
propriétaire qui assure la gestion des accčs ŕ la page et sert les demandes des
autres sites. Le propriétaire est défini comme le dernier site ayant effectué
une écriture sur ladite page ; il n'y a donc pas de propriétaire fixe.
Chaque site possčde une table des pages notée Ptable renseignant, pour chaque page,
les valeurs suivantes :
- Le type d'accčs (Access) du site sur la page
peut prendre ces valeurs : lecture, écriture ou nil. Si l'accčs est ŕ nil,
le site n'a aucun accčs sur la page ; dans ce cas, la valeur des autres
champs de la Ptable
pour cette page sur ce site est non-significative.
- Le propriétaire (Owner) indique qui est
propriétaire de la page (le dernier rédacteur). Il peut s'agir en fait
d'un simple booléen permettant de déterminer si le site est ou non
propriétaire de la page.
- Liste des lecteurs (Copyset) : c'est la liste des
sites possédant une copie en lecture de la page ; lors d'une écriture,
cette liste permet au site propriétaire (c'est-ŕ-dire au dernier
rédacteur) d'annoncer aux sites lecteurs que leur copie de la page devient
invalide (procédure d'invalidation).
- Le verrou (Lock) : il s'agit d'un
sémaphore tel que décrit par Dijkstra assurant la synchronisation des
accčs aux pages.
Description de l'algorithme
L'algorithme de Li et Hudak est structuré en cinq éléments.
Chacun de ces éléments existe sur tous les sites.
Les algorithmes ci-dessous présentent les différents modules
de l'algorithme de Li et Hudak, tels qu'ils sont décrits dans l’article disponible ici.
Ils exposent le cas de requętes sur une page p.
Ces requętes sont éventuellement distantes ; elles sont dans ce cas émises par
le site s. Le site local, oů
sont exécutés ces algorithmes, est désigné par ego.
Les gestionnaires de défaut en lecture et en écriture gčrent
les défauts de page effectués localement. De męme, les serveurs en lecture
et en écriture délivrent les pages demandées par d'autres sites via le
réseau. Un serveur d'invalidation reçoit et applique les requętes
d'invalidation de pages.
Gestionnaire de
défauts en lecture :
Verrouiller (PTable[p].verrou)
Diffuser une demande en lecture pour p
Attendre la réception de p
PTable[p].accčs := lecture
Déverrouiller (PTable[p].verrou)
Serveur en
lecture :
Verrouiller (PTable[p].verrou)
Si je suis le propriétaire de p
Alors
PTable[p].copyset := PTable[p].copyset + s
PTable[p].accčs := lecture
Envoyer p au site s
Fin si
Déverrouiller (PTable[p].verrou)
Gestionnaire de
défauts en écriture :
Verrouiller (PTable[p].verrou)
Diffuser une demande en écriture pour p
Attendre
la réception de p et de son copyset
Invalider (p,PTable[p].copyset)
PTable[p].accčs := écriture
PTable[p].copyset := ensemble vide
PTable[p].propriétaire := ego
Déverrouiller (PTable[p].verrou)
Serveur en
écriture :
Verrouiller (PTable[p].verrou)
Si je suis le propriétaire de p
Alors
Envoyer p et PTable[p].copyset au site s
PTable[p].accčs := nil
PTable[p].propriétaire := s
Fin Si
Déverrouiller (PTable[p].verrou)
Fonction
d'invalidation(p, copyset) :
Pour i dans
copyset Faire
Envoyer
une requęte d'invalidation de p au site i
Fin Pour
Serveur
d'invalidation :
PTable[p].accčs := nil
Travail ŕ faire :
- Proposer une
implantation pour ce service
Exercice supplémentaire 9 : mise en śuvre d’un calendrier
Cet exercice est tiré d’un précédent examen.
On souhaite implanter un calendrier en CORBA/Java. Pour ce faire, vous disposez
de l’interface IDL ical.idl
ainsi que du Makefile
suivant.
Cette application fonctionne de la façon suivante :
- L'attribut calendrier_entier permet de lire en une
fois toutes les données d'un calendrier. Chaque donnée d'un
calendrier est décrite par la structure donnee du fichier IDL.
- Au sein du serveur,
l'interface usine
est instanciée une fois et permet:
1. De créer de nouveaux
calendriers grâce ŕ la méthode creer_calendrier.
Cette méthode requiert le nom du calendrier ŕ créer, puis, alloue un objet
CORBA de type calendrier.
L'argument ref permet au client
de récupérer la référence sur l'objet ainsi instancié. Par la suite,
l'objet calendrier permet au
client d'ajouter des données grâce ŕ la méthode ajouter_donnee.
2. De se connecter ŕ un calendrier
existant grâce ŕ son nom via la méthode rechercher_calendrier.
Travail ŕ faire :
1. Proposer un serveur et
les classes Java qui implantent les interfaces IDL calendrier et usine.
2. Proposer un client qui
utilise ce service et qui fonctionne de la façon suivante :
o
Le client récupčre, grâce ŕ la méthode rechercher_calendrier,
la référence d’un objet calendrier
dont le nom est passé en ligne de commande.
o
Puis, il liste, grâce ŕ l'attribut/séquence calendrier_entier, pour le calendrier passé en argument,
les données actuellement stockées chez le serveur. Vous afficherez le contenu
de chaque structure stockée dans cette séquence (description, année, jour, mois
et le libellé associé). Pour tester cette fonctionnalité, vous devrez écrire un
premier client qui crée un calendrier et lui ajoute des données.
Exercice supplémentaire 5 : mise en śuvre d’un systčme de fichier distant
Dans cet projet, on vous demande d'implanter un serveur qui permet d'accčder
via CORBA ŕ un mini systčme de fichiers. Les interfaces
IDL de ce serveur sont les suivantes.
Le serveur permet de créer, lire ou écrire dans des fichiers qui peuvent ętre,
soit des fichiers réguliers, soit des répertoires. On suppose que les fichiers
réguliers sont des fichiers textes. Chaque fichier accessible par le serveur
l'est au travers d'objets CORBA. Pour mettre ŕ disposition ce systčme de
fichiers, deux interfaces devront ętre implantées :
- L'interface regular_file qui permet aux clients de manipuler un fichier
régulier particulier.
- L'interface directory qui permet aux clients de manipuler un répertoire
donné. A partir d'un objet CORBA représentant un répertoire donné, il est
possible d'accéder aux fichiers réguliers et aux sous répertoires qu'il
contient.
Un client qui souhaite manipuler des fichiers doit donc obtenir des références
d'objets CORBA représentant ces dits fichiers.
L'interface regular_file
contient les méthodes suivantes :
- La méthode read. Cette méthode est une demande de lecture du fichier
de size caractčres. Le résultat
de la lecture est déposé dans la chaîne de caractčres data et la méthode retourne le nombre de caractčres
effectivement lus. Chaque objet de type regular_file
mémorise un offset ŕ partir duquel les lectures et écritures doivent ętre
effectuées.
- La méthode write. Cette méthode permet d'effectuer une écriture dans le
fichier de size caractčres. La chaîne
de caractčres ŕ écrire dans le fichier est contenue dans data. La méthode retourne le nombre de caractčre
effectivement écrits.
- La méthode seek positionne l'offset du fichier ŕ la position new_offset.
- Enfin, la méthode close permet de fermer le fichier. Tout accčs au fichier
grâce ŕ la référence d'objet ŕ partir de laquelle la méthode close a été invoquée devient alors interdit.
L'interface directory contient
les méthodes suivantes :
- L'attribut number_of_file permet au client de connaître le nombre de fichiers
réguliers et de sous répertoires inclus dans le répertoire associé ŕ un
objet CORBA de type directory (répertoire que nous
désignerons dans la suite par le terme de "répertoire courant").
- La méthode open_regular_file permet d'ouvrir un
fichier régulier existant dans le répertoire courant. Grâce ŕ cette
méthode, le client obtient une référence d'objet CORBA associée au fichier
régulier ouvert. name est le nom du fichier
régulier ŕ ouvrir et m le mode d'ouverture du
fichier. Le fichier peut ętre ouvert :
- En lecture seule (mode read_only) : l'offset est alors positionné au début du fichier.
- En écriture seule
(modes write_append et write_trunc). Avec le mode write_append, l'offset est positionné sur la fin de fichier. Ce
mode permet d'ajouter de nouvelles données dans le ficher. Avec le mode write_trunc, l'offset est positionné au début du fichier et le
fichier est vidé ŕ l'ouverture. Ce mode permet de réinitialiser le
contenu d'un fichier régulier.
- En lecture et en
écriture (mode read_write). L'offset est alors
positionné sur le début du fichier mais le fichier n'est pas vidé. Les
données qui seront écrites remplaceront alors celles précédemment
mémorisées.
- La méthode open_directory permet d'obtenir une référence sur un objet CORBA
associé ŕ un sous répertoire existant dans le répertoire courant. name est le nom du sous répertoire ŕ ouvrir.
- La méthode create_regular_file permet de créer, dans
le répertoire courant, un nouveau fichier régulier dont le nom est name.
- La méthode create_directory permet de créer, dans
le répertoire courant, un nouveau sous répertoire dont le nom est name.
- La méthode delete_file supprime le sous répertoire ou le fichier régulier du
répertoire courant dont le nom est name.
- La méthode list_files permet d'obtenir la liste des fichiers réguliers et
des sous répertoires contenus par le répertoire courant. La méthode
retourne le nombre total de fichiers réguliers et de sous répertoires
contenus dans le répertoire courant. La référence d'objet CORBA de type file_list est un itérateur permettant d'obtenir, par appel
successif ŕ la méthode next_one, les noms des
différents sous répertoires et fichiers réguliers du répertoire courant.
Lorsque la méthode next_one retourne false, la liste de sous répertoires et de fichiers réguliers
a été entičrement parcourue. A chaque appel de la méthode next_one, une structure directory_entry renseigne pour chaque
fichier son nom ainsi que son type (répertoire ou fichier régulier).
Travail ŕ faire :
- Proposez un serveur qui
implante les interfaces directory, regular_file et file_list. Les méthodes doivent
tenir compte des conditions d'erreur suivantes :
- Accčs ŕ un fichier
inexistant (exception no_such_file).
- Lecture sur un fichier
dont l'offset pointe aprčs le dernier caractčre du fichier (exception end_of_file).
- Demande de
positionnement d'un offset erroné (exception invalid_offset).
- Demande d'opération
impossible compte tenu du type de fichier. (exception invalid_operation)
- Demande de création
d'un fichier déjŕ existant (exception already_exist).
Vous ętes libre d'ajouter
d'autres exceptions si vous estimez que certains cas d'erreurs doivent ętre
traités. Par ailleurs, vous pouvez étendre l'interface IDL donné,
mais votre serveur doit au minimum
offrir les services décrits ci-dessus.
Vous donnerez un client
illustrant les différents services offerts par votre serveur: ce client
donc faire office de jeu de test.
Vous pouvez travailler seul ou en binôme. Le projet est ŕ rendre par mail ŕ
Frank Singhoff pour le 17 mars au plus tard. On vous demande de faire un
rapport. Ce rapport de 3 pages maximum doit contenir le mode d'emploi de votre logiciel, ses
fonctionnalités ainsi que sa conception (structure du logiciel). Vous serez
évalué sur :
- La qualité du logiciel
réalisé : ses fonctionnalités, la propreté du code, sa conception
(structure), sa fiabilité.
- Le niveau de détail de votre jeu de test, et donc du client proposé.
- La qualité du rapport.
- Sur la démonstration que
vous effectuerez la semaine du 17 mars.
Exercice supplémentaire 10
Dans ce TP, on vous demande d'implanter un serveur qui
implante ce fichier IDL.
Vous devez livrer le travail par email ŕ singhoff@univ-brest.fr AVANT de quitter la
salle de TP. Un émargement vous sera demandé une fois la livraison du travail
constaté par F. Singhoff.
Le fichier IDL server.idl comporte deux
interfaces CORBA : l'interface commande et
l'interface carnet_commandes.
L'interface commande mémorise chez le serveur les données d'une commande :
- Une commande a un numéro unique.
- Une commande est expédiée ŕ un client, ŕ une addresse donnée.
- Une commande comporte plusieurs articles. Pour chaque article commandé, il faut
préciser le produit concerné, le nombre de produit ainsi que le prix unitaire d'un produit.
- La méthode void ajouter_article(in article a) permet d'ajouter un article ŕ une commande.
- La méthode long calculer_montant() calcule le montant total de la commande
en sommant pour l'ensemble des articles le prix unitaire
de chaque produit multiplié par le nombre
de produit.
L'interface carnet_commandes mémorise chez le serveur les objets CORBA commande
:
- La méthode commande ajouter_commande(in string nom_client)
permet d'ajouter une commande dans le serveur. A la création d'une commande, un numéro
de commande unique doit ętre généré et le nom du client
associé ŕ cette commande doit ętre donné (argument nom_client).
- La méthode void annuler_commande(in long numero) permet
de supprimer une commande mémorisée par le serveur.
- La méthode void rechercher_commande(inout commande cmd, in long numero)
permet de rechercher la commande numéro numero préalablement enregistrée
dans le serveur.
- Enfin, la méthode long calculer_chiffre_affaire () calcule le montant total
de l'ensemble des commandes mémorisées dans le serveur.
Question 1 :
Proposer une implantation de l'interface CORBA commande.
Vous donnerez un Serveur et un Client permettant de tester cette mise en oeuvre.
La complétude des tests réalisés par ce Client/Serveur sera prise en compte dans la notation.
La qualité du logiciel (robustesse et propreté) sera également prise en compte dans la
notation.
Question 2 :
Proposer une implantation de l'interface CORBA carnet_commandes.
Vous donnerez un Serveur et un Client permettant de tester cette mise en oeuvre.
La complétude des tests réalisés par ce Client/Serveur sera prise en compte dans la notation.
La qualité du logiciel (robustesse et propreté) sera également prise en compte dans la
notation.
Exercice supplémentaire 11
Dans ce TP, on vous demande d'implanter une application CORBA
ŕ partir
des éléments suivants.
Vous devez livrer votre travail par email ŕ singhoff@univ-brest.fr AVANT de quitter la
salle de TP. Un émargement vous sera demandé une fois la livraison du travail
constaté par F. Singhoff.
Le fichier IDL server.idl comporte deux
interfaces CORBA : l'interface dictionnaire et
l'interface usine_dictionnaire.
L'interface dictionnaire mémorise chez le serveur un ensemble de mots :
- Toutes les informations d'un mot sont
mémorisées dans la structure IDL entree.
- Chaque mot est défini par un type énuméré (type énuméré
type dont les valeurs sont verbe, adjectif ou nom) ainsi que par plusieurs
définitions.
- Toutes les définitions d'un mot donné sont stockées dans le tableau les_definitions.
- L'utilisateur peut interagir avec un dictionnaire grâce ŕ deux méthodes:
- La méthode void ajouter(in entree e) qui permet d'ajouter un mot dans le dictionnaire.
- La méthode void rechercher (in string un_mot, out entree e) qui
permet de trouver les informations du mot un_mot et de les retourner au client.
Lorsque le mot n'existe pas dans le dictionnaire, l'exception non_trouve doit ętre levée par le
serveur.
L'interface usine_dictionnaire
permet d'instancier un objet dictionnaire
grâce ŕ la méthode void creation_dictionnaire(out dictionnaire d).
Question 1 :
Proposer une implantation de l'interface CORBA dictionnaire.
Vous donnerez un Serveur et un Client permettant de tester cette mise en oeuvre.
La qualité des tests réalisés par ce Client sera prise en compte dans la notation.
La qualité du logiciel (robustesse et propreté) sera également prise en compte dans la
notation.
Lorsque vous aurez terminé cette question, signalez vous ŕ F. Singhoff pour
la prise en compte de votre travail.
Question 2:
Proposer une implantation de l'interface CORBA usine_dictionnaire.
Vous donnerez un Client et un Serveur permettant de tester cette mise en oeuvre.
La qualité des tests réalisés par ce Client sera prise en compte dans la notation.
La qualité du logiciel (robustesse et propreté) sera également prise en compte dans la
notation.
Lorsque vous aurez terminé cette question, signalez vous ŕ F. Singhoff pour
la prise en compte de votre travail.
TP noté CORBA/SOR 2017/2018 : mise en oeuvre d'un livre de recettes
Dans ce TP, on vous demande d'implanter une application CORBA
ŕ partir
des éléments suivants.
Le fichier IDL server.idl comporte deux
interfaces CORBA : l'interface livre et
l'interface recette.
Ces interfaces offrent un moyen pour stocker des recettes de cuisines. Ainsi, chaque objet de
type recette mémorise le nom du plat ainsi que tous ses ingrédients.
La liste des ingrédients pour un plat donné est mémorisée dans une séquence de structure ingredient.
Un ingrédient est défini par un nom, une quantité et une unité (grammes, litres ...).
Au sein du serveur,
l'interface
livre est instanciée une fois et permet d'enregistrer les recettes
grâce ŕ la méthode nouvelle_recette : cette méthode alloue un objet
CORBA de type recette afin que les ingredients et le nom de cette nouvelle recette puisse y
ętre stockés.
Finalement, l'utilisateur peut interagir avec le serveur grâce ŕ deux méthodes:
- La méthode void ajouter_ingredient(in ingredient i) qui permet d'ajouter un ingrédient ŕ une recette.
- La méthode void nouvelle_recette (in string nom_recette, inout recette r) qui
permet d'ajouter une nouvelle recette au sein du livre.
Lorsque la recette existe déjŕ dans le livre, l'exception recette_deja_existante doit ętre levée par le
serveur.
Question 1 :
Proposer une implantation de l'interface CORBA recette.
Vous donnerez un Serveur et un Client permettant de tester cette mise en oeuvre.
La qualité des tests réalisés par ce Client sera prise en compte dans la notation.
La qualité du logiciel (robustesse et propreté) sera également prise en compte dans la
notation.
Question 2:
Proposer une implantation de l'interface CORBA livre.
Vous donnerez un Client et un Serveur permettant de tester cette mise en oeuvre.
La qualité des tests réalisés par ce Client sera prise en compte dans la notation.
La qualité du logiciel (robustesse et propreté) sera également prise en compte dans la
notation.
TP noté CORBA/SOR 2018/2019 : mise en oeuvre d'un jeu de morpion
On souhaite implanter le jeu du morpion avec l'interface IDL CORBA
donnée ici. Ce jeu se déroule avec deux joueurs.
On souhaite implanter un serveur qui va gérer les parties de morpion avec les
deux interfaces IDL
le_serveur et une_partie.
- L'interface le_serveur ne comporte qu'une seule méthode, la méthode
creation_partie qui permet de créer un objet CORBA une_partie
mémorisant toutes les informations d'une partie de morpion.
- L'interface une_partie stocke les informations d'une partie
et offre les méthodes invoquées par les joueurs lors du déroulement du jeu.
Avec cette interface IDL, une partie se déroule de la façon suivante:
- Les joueurs jouent chacun leur tour.
- On suppose que le joueur 1 utilise des cercles
et que le joueur 2 utilise des croix.
- L'état du jeu est mémorisé dans un tableau de 3 lignes et 3 colonnes.
- Chaque case de ce tableau peut avoir 3 valeurs possibles: vide,
cercle
ou croix. Une case comporte la valeur vide
quand les joueurs n'ont déposé ni croix ni cercle.
Une case comporte la valeur cercle
quand le joueur 1 y a déposé un cercle.
Une case comporte la valeur croix
quand le joueur 2 y a déposé une croix.
- Quand l'un des joueurs a aligné 3 croix ou 3 cercles, alors il a gagné.
L'alignement peut ętre vertical, horizontal ou en diagonale.
- L'attribut etat permet à un client de connaitre le contenu
de la matrice : cet attribut retourne un tableau de 9 cases correspondant
aux 3x3 cases du morpion.
- Avec cette interface, on souhaite implanter un client CORBA qui permet aux joueurs
d'interagir avec le serveur de parties.
- La méthode jouer permet au client de jouer pour le joueur 1 et le joueur 2, c'est à dire
de déposer soit une croix soit un cercle dans le tableau:
- Les paramètres x et y sont respectivement le numéro de ligne et de colonne
ou le joueur souhaite déposer soit un cercle, soit une croix.
- Le paramètre valeur
permet d'indiquer au serveur si le joueur dépose une croix ou un cercle, ce qui permet donc de
savoir si c'est le joueur 1 ou le joueur 2 qui souhaite jouer.
- Enfin, le paramètre gagne retourne une valeur positive si le joueur qui vient de jouer
à gagner. La valeur de gagne est négative sinon.
Questions :
- Proposer un serveur qui implante les deux interfaces IDL.
- Pour le test de votre serveur, implanter un client dont le fonctionnement est le suivant:
- Le programme client commence par instancier une partie chez le serveur.
- Ensuite, il invite le joueur 1 à saisir au clavier la case à cocher
puis invoque la méthode jouer.
- Si la partie est gagnée, le client affiche un message et termine.
- Si la partie n'est pas terminée,
le client invite le joueur 2 à saisir au clavier la case à cocher
puis invoque la méthode jouer.
- Si la partie est gagnée, le client affiche un message et termine.
- Si la partie n'est pas terminée, le client recommence les opérations
2 à 6.
TP noté CORBA/SOR 2022/2023 : réservation de chambre d'hotel
Dans ce exercice, on vous demande d'implanter une application CORBA
ŕ partir
des éléments suivants.
Le fichier IDL server.idl comporte deux
interfaces CORBA : l'interface chambre et
l'interface reservations.
Ces interfaces offrent un moyen pour stocker des
réservations. Une réservation est une association entre
le nom d'un client, le numéro d'une chambre est un numéro de semaine.
En effet, les réservations d'une chambre se font pour une semaine complčte.
La
structure reservation mémorise ces informations.
Chaque chambre est décrite par un objet CORBA qui comporte les informations suivantes :
- Le numéro de la chambre qui est unique dans l'hotel
(attribut numero)
- Le nombre de personne que peut héberger la chambre (attribut
nombre_personne)
- Le type de chambre : les chambres peuvent ętre soit avec vue sur mer, soit
avec vue sur le parc (attribut chambre_type vue
Au sein du serveur,
l'interface
reservations est instanciée une fois et permet d'enregistrer les
chambres de l'hotel et les réservations associées.
Le serveur doit donc initialement comporter un seul objet CORBA du type
reservations.
L'utilisateur peut interagir avec le serveur grâce ŕ 3 méthodes:
- La méthode
void creation_chambre (out chambre c, in long numero, in long nombre_personne, in chambre_type v);
permet la description d'une chambre dans le serveur.
Le client récupčre la référence sur l'objet CORBA grâce au premier argument.
Les arguments suivants décrivent la chambre ŕ ajouter.
- La méthode
void ajout_reservation(in reservation resa);
permet d'ajouter une nouvelle réservation dans le serveur.
recette au sein du livre.
Pour rappel, une réservation est décrite par le nom d'un client, le numéro de la chambre
et le numéro de semaine pour laquelle la chambre doit ętre réservée.
- Enfin la méthode
chambre consultation_reservation(in string nom_client, in long semaine);
permet de consulter une réservation. La méthode permet de connaitre la chambre
qui a été réservée pour le client et la semaine passés en argument de la méthode.
Travail ŕ faire :
Proposer une implantation des interface CORBA chambre
et reservations.
Vous donnerez un Serveur et un client permettant de tester cette mise en oeuvre.
La qualité des tests réalisés par ce Client sera prise en compte dans la notation.
La qualité du logiciel (robustesse et propreté) sera également prise en compte dans la
notation.
Page maintenue
par Frank Singhoff (singhoff@univ-brest.fr)
Derničre mise ŕ jour le 8 janvier 2023