
Le langage Ada
F. Singhoff, D. Massé, L. Nana
A partir des machines Linux standards lancées via VirtualBox, pour accéder au compilateur GNAT,
ouvrez simplement un shell sur la machine Linux une fois lancée.
Vous diposez
ici d'un livre complet sur le langage Ada
.
Exercice 1 : Hello world
Récupérez le fichier
hello.adb.
Compilez le programme grâce à la commande :
gnatmake -g hello
Quels sont les fichiers générés par gnatmake ?
Exercice 2 : les entrées sorties
- Récupérez, compilez et testez le programme
lire.adb.
- Modifiez le programme lire.adb afin
de saisir et afficher un type dérivé (nommé angle_degre) du type entier dont les valeurs
sont comprises entre 0 et +360.
- Dans ce programme modifié, si vous saisissez une chaîne de caractères
à la place d'un angle_degre, que se passe t il ?
- Ecrire un package Ada angles qui encapsule
le code nécessaire à la saisie/affichage des
types angle_degre et angle_radian.
angle_radian est un type dérivé de float dont les valeurs sont
comprises entre 0.0 et +2.0*PI ou PI est une constante fixée à la valeur 3.1456.
La spécification de ce paquetage doit contenir le prototype des méthodes Get
et Put alors que le corps du paquetage doit contenir leur mise
en oeuvre grâce à text_io. Modifiez le
programme écrit dans la question 3 afin qu'il utilise
le package angles.
Exercice 3 : moyenne d'une suite de nombres
Ecrire un programme Ada qui :
- Permet de saisir une liste de notes dont les valeurs vont de 0 à +20.
Le type à saisir doit être dérivé des flottants.
- Lorsque le nombre 0.0 est saisi par
l'utilisateur, le programme calcule puis affiche la moyenne, le plus
grand et le plus petit des nombres précédemment
saisis.
- Vous n'avez pas besoin d'utiliser de tableau ici.
Exercice 4 : paquetage générique : la calculatrice polonaise
Soient les fichiers :
piles.ads,
piles.adb,
et test_pile.adb.
Ces fichiers implantent une calculatrice polonaise.
- Etudiez et testez les trois fichiers ci-dessus.
- Ajoutez deux fonctionnalités : la première implante
l'opération de division, la deuxième permet d'inverser
le contenu de la pile.
- Ajoutez une procédure permettant d'afficher le
contenu de la pile.
- Dans la correction, quel est le sens de private. Avec la VERSION 1,
comment peut on déclarer deux piles ?
Avec la VERSION 2,
comment peut on déclarer deux piles ? Quelles sont les différences sur ce point
entre les deux versions ?
Exercice 5 : tâches anonymes
Ecrire un programme Ada constitué de deux tâches : les tâches tic et tac.
Chaque tâche utilise un compteur commun (variable globale à la procédure
principale de type entière) et effectue les traitements suivants :
- Incrémentation du compteur.
- Affichage de la valeur du compteur et, soit de "tic", soit de "tac".
- Attente d'un délai d'une seconde.
La procédure principale contient une seule instruction qui consiste
à initialiser le compteur à zéro.
- Combien de tâches ce programme contient il ?
- Quand les tâches commencent elles leur exécution ?
- Quand la procédure principale se termine-t-elle ?
- Quel problème classique pose ce programme ?
Exercice 6 : notion de rendez-vous
On souhaite modifier le programme précédent en lui ajoutant une troisième
tâche que l'on nommera mutex.
L'interface de cette tâche comporte deux entrées : P et V (entrées sans paramètre).
- Donnez le code de cette tâche de sorte que l'invocation des entrées de la tâche
mutex permette d'assurer un accès exclusif à une ressource quelconque.
- Modifiez le programme tic-tac de sorte que le compteur soit
consulté/modifié correctement par toutes les tâches.
Exercice 7 : types tâches, allocation statique et dynamique
Question 1 :
Ecrire un programme Ada qui :
- définit un type tâche element.
- déclare statiquement 10 tâches de type element.
- Le corps du type tâche element doit afficher un message quelconque
à l'écran toutes les secondes.
Question 2 :
Modifier votre programme précédent de sorte que les tâches soient toutes allouées dynamiquement.
En dehors de l'allocation mémoire de la tâche, le comportement du programme de la question 2 est
différent du programme de la question 1 : expliquez.
Exercice 8 : rendez-vous avec paramètres, l'instruction select
On souhaite écrire une tâche qui gère une mémoire de calculatrice.
Cette mémoire est un entier initialisé à zéro. Les autres tâches consultent et
modifient cette mémoire grâce à l'interface suivante:
task type memoire is
entry ajouter(num : in integer);
entry soustraire(num : in integer);
entry consulter(num : out integer);
end memoire;
L'entrée ajouter (resp. soustraire) permet d'ajouter (resp. de retrancher)
un entier à la mémoire. L'entrée consulter permet
de connaître la valeur courante de la mémoire.
- Ecrire le corps de la tâche mémoire. Pour simplifier, dans un premier temps, on suppose
que la tâche mémoire accepte les rendez vous dans
cet ordre : ajouter, soustraire, consulter,
et ainsi de suite.
- Donner une procédure principale illustrant l'utilisation de la tâche mémoire
avec une seule tâche de ce type.
- Modifier le corps de la tâche afin qu'elle puisse
accepter les rendez-vous dans un ordre quelconque.
- Modifier le programme précédent en déclarant un tableau de cases mémoire.
Exercice 9 : types protégés, producteur consommateur
On cherche dans cet exercice à implanter un producteurs/consommateurs.
Producteurs et consommateurs échangent des données via un tampon.
Le tampon peut mémoriser quatre entiers maximum.
Un producteur insère les données entier par entier. Un consommateur retire
les données entier par entier. Le tampon est géré de façon FIFO. Avec Ada,
un tel tampon est implanté par
un tableau d'entiers.
- Dans un premier temps, on vous demande de proposer un programme Ada qui implante cette synchronisation
pour un seul producteur et un seul consommateur. Pour ce faire :
- Modifier votre programme
de sorte que plusieurs consommateurs et plusieurs producteurs puissent manipuler le tampon.
On suppose toujours que le producteur insère les données entier par entier et que
le consommateur retire les données entier
par entier.
Le tampon est toujours géré de façon FIFO.
- Une autre façon d'implanter un producteur-consommateur consiste à
directement implanter le tableau au sein du type protégé. Proposez un dernier programme utilisant
un type protégé qui offre un accès synchronisé à un tampon.
La signature du type protégé est la suivante :
Taille_Buffer : constant Integer :=4;
type Buffer_Type is array (1..Taille_Buffer) of Integer;
protected type Buffer is
entry Produire(Val : in Integer);
entry Consommer(Val : in out Integer);
private
-- Les donnees du tampon
Data : Buffer_Type;
-- Indices de production et consommation
Index_Cons : Integer :=1;
Index_Prod : Integer :=1;
-- Nombre d'element dans le tampon
Nb_Element : Integer:=0;
end Buffer;
Le type protégé doit donc :
- offrir dans sa partie publique deux entrées permettant de lire et d'écrire un entier dans/depuis le tampon
déclaré au sein du type protégé.
- stocker dans sa partie privée le tableau d'entier ainsi que les indices permettant aux
producteurs et consommateurs d'accéder à leurs données.
Dans l'exercice 10, la compilation croisée d'un programme Ada pour une cible RTEMS/Leon est présentée.
Par la suite, dans les exercices 11 et 12, on regarde comment implanter une application temps réel
avec Ada.
Exercice 10 : compilation-croisée
Dans cet exercice, on va comparer les Runtimes "Linux/Intel 386" et "RTEMS/Leon".
Soit
les fichiers suivants. Récupérez ces fichiers et stockez les dans un répertoire unique.
- Compilez le programme hello.adb avec la commande gnatmake -g hello.adb.
- Lancez la commande file hello : que signifit les différentes informations affichées ?
- Lancez le programme et vérifiez que le programme réalise effectivement la sortie écran attendue.
- On utilise maintenant une autre runtime pour exécuter ce programme simple : une runtime destinée
à exécuter des programmes Ada sur un processor Leon hébergeant le système d'exploitation temps réel RTEMS.
Pour ce faire:
- Récupérez
le fichier
rtems.bash
- Tapez la commande source rtems.bash. Vous avez maintenant
accès à un environnement Ada pour processor Leon3.
- Compilez à nouveau le programme hello.adb mais avec cette nouvelle commande:
make clean
make
- Cette nouvelle compilation produit un exécutable nommé hello.obj.
- Lancez la commande file hello.obj. Que signifit les différentes informations affichées ?
- Lancez le programme hello.obj dans le shell courant. Que se passe t il ? Pourquoi ?
- Pour être exécuté, ce programme doit être lancé sur une carte Leon/RTEMS.
Pour ce TP, nous n'allons pas utiliser une carte mais
le simulateur tsim
(logiciel de la société Gaisler Research,
http://www.gaisler.com) :
- Lancer le simulateur grâce à la commande tsim:
$tsim
tsim>
- Chargez le binaire sur la "carte électronique" par la commande load :
tsim>load hello.obj
- Puis, lancez finalement le programme par la commande run :
tsim>run
Hello world
- Et constatez l'affichage produit par le programme Ada.
Exercice 11 : ordonnancement à priorité fixe
Attention : pour cet exercice, vous devez utiliser le compilateur Ada pour Leon/RTEMS ainsi que le
simulateur tsim.
Dans cet exercice, nous allons manipuler l'ordonnancement à priorité fixe avec Ada.
Récupérez ces fichiers et stockez les dans un répertoire unique nommé EXO11.
- Regardez le fichier gnat.adc. Quelle est la signification
des divers pragmas spécifiés dans ce fichier ?
- Dans le programme scheduling.adb, affectez la priorité
12 à la tâche Tache_A, la priorité 11 à la tâche Tache_B et la priorité 13
à la procédure principale.
- Compilez le programme scheduling.adb avec la commande make.
- Observez l'ordonnancement de ces tâches grâce à tsim.
- Changez les priorités des tâches en affectant un niveau de priorité identique pour toutes
les tâches, puis,
en inversant les niveaux
de priorités. A chaque fois, exécutez le programme et regardez les différents ordonnancements générés.
- Ajouter dans la boucle de chaque tâche l'instruction delay 1.0. A quoi sert cette instruction ?
Exécutez à nouveau le programme : que constatez vous concernant l'ordonnancement des tâches ?
Exercice 12 : mise en oeuvre d'un jeu de tâches périodiques
Attention : pour cet exercice, vous devez utiliser le compilateur Ada pour Leon/RTEMS ainsi que le
simulateur tsim.
- Soient trois tâches périodiques dont les paramètres sont :
- T1 : période=1 second, capacité=10 milli-seconde. Echéance égale à la période.
- T2 : période=500 milli-seconde, capacité=10 milli-seconde. Echéance égale à la période.
- T3 : période=250 milli-seconde, capacité=10 milli-seconde. Echéance égale à la période.
- Donner le chronogramme d'ordonnancement de ces tâches sur la période d'étude.
On suppose ici un ordonnancement à priorité fixe préemptif avec une affectation des priorités
selon Rate Monotonic.
-
Récupérez ces fichiers et stockez les dans un répertoire unique nommé EXO12.
- On vous demande de compléter ces programmes afin de créer les tâches périodiques ordonnancées
selon la méthode Rate Monotonic.
On vous demande de compléter la procédure principale (fichier periodiques.adb)
ainsi que le fichier generic_periodic_task.adb.
Les zones à compléter sont signalées par des étoiles.
Le travail à faire concernant la procédure principale est le suivant :
- Les trois tâches doivent démarrer au même instant : pour ce faire votre procédure principale devra
être ordonnancée avec le niveau de priorité le plus élevé.
- Les procédures Programme_T1, Programme_T2 et Programme_T3 constituent
le code exécuté par chaque
tâche. Ainsi, la tâche T1 doit exécuter Programme_T1 à chacun de ses réveils périodiques.
- Dans le fichier periodique.adb, on vous demande d'instancier trois tâches périodiques.
La variable First_Release_Time stocke la date de premier réveil des tâches
périodiques et doit être passé en argument au paquetage générique generic_periodic_task.
Il en est de même pour la période, la priorité et le code de chaque tâche.
Le travail à faire concernant generic_periodic_task.adb est le suivant :
- On vous demande de proposer une implantation pour le corps de la tâche periodic_task.
- Plus particulièrement, il vous est demandé de réveiller la tâche périodiquement.
- A chaque réveil périodique, la tâche doit exécuter son code, puis calculer la date de son prochain
réveil et enfin attendre que cette date soit atteinte.
- La tâche périodique doit se terminer après avoir effectué 5 réveils périodiques.
- Vous testerez l'application avec tsim.
Exercice 13 : les exceptions Ada
On souhaite expérimenter, dans cet exercice,
les exceptions Ada.
On vous demande d'écrire un programme qui permet à l'utilisateur de saisir des commandes
à envoyer vers un robot.
Les commandes sont définies de la façon suivante :
type commandes is (a_droite, a_gauche, avancer, reculer);
Le programme doit :
- Permettre la saisie d'une commande grâce au package text_io.enumeration_io.
L'exception standard DATA_ERROR est automatiquement levée lorsque l'utilisateur
saisie une information qui n'est pas compatible avec le
type énuméré. Lorsque
l'exception DATA_ERROR est levée, vous devez récupérer cette exception et
afficher un message indiquant l'erreur de saisie, puis, inviter l'utilisateur à
saisir une autre commande.
- Lorsque le programme a comptabilisé plus de 5 DATA_ERROR, une exception
utilisateur COMMANDE_INCORRECTE doit être levée et le programme doit être
terminé (une exception non récupérée termine le programme principal).
Exercice 14 : tableaux non contraints
- Soit le
programme tab.adb qui
résume les principaux attributs concernant les tableaux contraints
ou non. Qu'affichera ce programme à l'écran ? Expliquer le rôle de chaque attribut utilisé ?
- Soit un paquetage qui permet de multiplier des matrices.
La spécification de ce package est contenue dans le fichier
matrices.ads.
Ecrire l'implémentation du package matrice.adb.
- Testez le package matrices.ads
avec
ce programme.
Exercice 15 : table de hachage
Soit la spécification Ada du package hashs.ads :
with Ada.Strings.Unbounded;
use Ada.Strings.Unbounded;
generic
Size : Positive := 100;
type Data_Type is private;
with function Compute_Hash (
Key : in Unbounded_String )
return Natural;
with procedure Put (
D : Data_Type );
package Hashs is
type Hash is private;
procedure Initialize (
H : in out Hash );
procedure Add (
H : in out Hash;
Key : in Unbounded_String;
D : in Data_Type );
function Consult (
H : in Hash;
Key : in Unbounded_String )
return Data_Type;
procedure Put (
H : in Hash );
-- Exception levee par "Consult" si la clef
-- n'est pas trouve dans la table
--
Data_Not_Found : exception;
private
type Cell;
type Link is access Cell;
type Cell is
record
Next : Link;
Key : Unbounded_String;
A_Data : Data_Type;
end record;
type Hash is array (1 .. Size) of Link;
end Hashs;
Fonctionnement de l'application :
On souhaite mettre en oeuvre un paquetage générique implantant une table de hash. Ce
paquetage est utilisé par un programme qui stocke un dictionnaire.
Une table de hash est une structure de donnée permettant d'accéder rapidement a des
données. Ici, il s'agit d'un tableau de taille fixe. Une liste
chaînée est associée à chaque entrée de ce tableau (cf. figure ci-dessous).

Figure 1. Une table de hachage utilisant une liste pour la gestion des collisions
L'information a mémoriser est constituée d'une clef associée à une information.
Ainsi, dans l'exemple du dictionnaire, le clef constitue le mot à
mémoriser et l'information constitue la définition de ce mot.
On suppose dans cet exercice que la clef est une chaîne de caractères.
A partir de la clef, on calcule un indice dans le tableau.
La fonction qui calcule l'indice est appelée "fonction de hachage".
Lorsque l'application de la fonction de hachage sur deux clefs différentes
implique le stockage de deux informations sur le même indice du tableau, on utilise
une liste chaînée pour stocker les informations au même indice
du tableau : on parle alors de "collision".
Les chaines de caractères manipulées ici sont des Unbounded_Strings
dont le programme
ustr.adb
vous montre comment les utiliser.
Ainsi dans l'exemple de la Figure 1, la fonction de hachage utilisée
appliquée à la clef "Zone"
renvoit l'indice 4, à la clef "Sigle" renvoit 5, "Décalé" renvoit 6, ...
La paquetage
Ada que nous cherchons à écrire
peut utiliser n'importe quelle fonction de hachage grâce au paramètre
compute_hash.
En outre, le paquetage peut mémoriser n'importe quel type de données et
autorise la modification de la taille de la table lors de l'instanciation du paquetage.
Travail à faire:
- Récupérez le fichier
test_hashs.adb.
et hashs.ads.
test_hashs.adb
est un exemple d'utilisation du paquetage générique.
La fonction de hachage utilisée ici est basée sur
la taille de la clef.
- Ecrire l'implantation du package hashs.adb. Les procédures/fonctions à écrire
sont les suivantes :
- Add : ajoute dans la table H l'information D
avec le clef Key.
- Consult : retourne l'information associée à la clef Key dans la table H .
- Initialize : vide la table H (initialise chaque entrée de la table à null )
- Put : sortie à l'écran du contenu de la table (clef et donnée associées).
- Testez votre paquetage avec la procédure principale test_hashs.adb.
- Modifiez ces unités de programme de sorte que le paquetage hashs.ads/adb
puisse utiliser des clefs de n'importe quel type, et non pas seulement des chaines de caractères.
Exercice 16, synchronisation par rendez-vous : le pipe-line
On souhaite écrire un programme Ada qui convertit un nombre de la base 10 à la base 2.
Cette conversion est effectuée grâce à un pipe-line de 8 étages.
Chage
étage est une tâche Ada. L'interface d'un étage
est la
suivante :
type Etage;
type Etage_Ptr is access Etage;
task type Etage is
entry Etage_Suivant (
Tache : in Etage_Ptr );
entry Divise (
Valeur : in Natural );
end Etage;
Chaque étage/tâche contient deux entrées :
- L'entrée Etage_Suivant. Cette entrée permet à l'étage n de
mémoriser un pointeur sur l'étage n+1.
Cette entrée est uniquement utilisée lors de la construction du pipe-line ; c'est à
dire à l'initialisation du programme.
- L'entrée Divise.
Cette entrée d'un étage n est invoquée par un étage n-1. Cette entrée réalise les opérations
suivantes :
- Elle divise par 2 l'entier Valeur et affiche le reste (0 ou 1).
- Si le résultat de la division est non nul,
elle invoque l'entrée divise de l'étage suivant avec le dividende.
- Si le résultat de la division est non nul est que l'étage est le dernier du pipe-line, un message d'erreur
est affiché.
Ecrire le corps de la tâche Etage ainsi qu'une procédure principale qui
- Alloue dynamiquement et initialise un pipe-line de 8 étages.
- Permet la saisie d'un nombre entier en base 10 et envoie ce nombre au premier étage du pipe-line
afin de le convertir.
Exercice 17 : statistiques
On vous demande d'écrire un programme permettant à un opérateur de mémoriser le nombre d'homme et
de femme qui rentrent dans un centre commercial.
Le programme Ada est constitué de trois tâches : d'une tâche nommée horloge, d'une tâche nommée
moyenne
et de la procédure principale.
La tâche moyenne contient trois entrées :
- L'entrée un_homme permet à la procédure principale d'indiquer à la tâche moyenne qu'un
homme vient d'entrer dans le centre commercial.
- L'entrée une_femme permet à la procédure principale d'indiquer à la tâche moyenne qu'une
femme vient d'entrer dans le centre commercial.
- L'entrée seconde permet à la tâche moyenne de mesurer le temps qui s'écoule
depuis le début de la mesure.
La tâche horloge invoque approximativement toutes les secondes l'entrée seconde de la
tâche moyenne afin d'avertir cette derniere qu'un seconde vient de s'écouler.
A chaque fois que les entrées un_homme et une_femme sont invoquées, la tâche
moyenne doit afficher le nombre moyen, par seconde, d'homme et de femme entrés dans le centre commercial.
Enfin, la procédure principale permet à l'opérateur de saisir l'arrivée d'un homme, ou d'une femme.
Exercice 18 : simulation de stations
On souhaite écrire
un programme qui simule, par des tâches
Ada, des machines (ou stations) qui échangent des messages.
Le programme est constitué d'une procédure principale qui saisit des entiers et envoie chaque
entier à l'ensemble des stations.
Les stations sont simulées par des tâches dont l'interface est la suivante :
task type Station is
entry Numero (
Num : in Integer );
entry Recevoir_Message (
Msg : in Integer );
end Station;
Votre programme doit fonctionner de la façon suivante :
- L'entrée Numero permet à la
procédure principale
de donner un
numéro unique permettant d'identifier chaque tâche.
Vous affecterez les identifiants aux tâches avant
de démarrer l'échange de message.
- L'entrée Recevoir_Message permet d'envoyer un message à chaque tâche.
Chaque message est un entier.
- A chaque fois qu'une tâche reçoit un message, elle doit l'afficher à l'écran accompagné de
son numéro de station.
- On suppose que le programme comporte 3 stations.
- Enfin,la procédure principale doit fonctionner de la façon suivante :
- Elle commence par envoyer à chaque station son numéro unique.
- Puis dans une boucle, elle attend la saisie d'un entier (le message) au clavier et le
transmet à chaque tâche avant d'attendre la saisie de l'entier suivant.
Exercice 19 : Tri concurrent d'un tableau
Première partie : paquetage générique
Dans cet exercice, on se propose d'étudier un paquetage permettant de manipuler
des tableaux.
On considère un paquetage défini par l'interface suivante :
package tables is
size : constant natural := 10;
type table_range is range 1..size;
type table is array (table_range) of integer;
procedure initialize(tab : in out table, val : in integer);
procedure put(tab : in table);
procedure sort(tab : in out table);
end tables;
Le paquetage décrit un type tableau sur lequel trois opérations peuvent
être effectuées : initialisation, affichage et tri.
La procédure initialize affecte à chaque
élément du tableau la valeur val.
La procédure put effectue l'affichage du tableau sur
la sortie standard.
Enfin, la procédure sort trie dans
l'ordre croissant les éléments du tableau.
La méthode
de tri fonctionne de la façon suivante :
- On compare deux éléments adjacents du
tableau et on échange leur contenu
s'ils ne sont pas correctement ordonnés.
- L'opération(1)
est effectuée séquentiellement
sur tous les
éléments du tableau.
- On recommence l'opération (2) lorsqu'au moins une permutation a été
effectuée à l'itération précédente.
Question 1.1 :
Donnez l'implantation du paquetage ci-dessus.
On souhaite construire un nouveau paquetage tables
qui fonctionne pour tous les types
(scalaire ou non, numérique ou non).
Ce paquetage générique doit
offrir
les mêmes fonctionnalités que le paquetage tables
initial et doit être
paramétré par
la taille du tableau.
Question 1.2 :
Donnez la spécification et l'implantation du paquetage générique.
Deuxième partie : tri parallèle version 1
L'algorithme de tri choisi étant peu efficace,
on souhaite modifier le paquetage
tables afin de bénéficier d'une éventuelle machine d'exécution multi-processeurs.
Pour ce faire, le tri va être réalisé par plusieurs tâches Ada.
On divise un tableau en N partitions (N étant un paramètre supplémentaire
du paquetage générique).
Pour simplifier, on suppose que la taille du tableau
est multiple de N.
Chaque partition est triée par une tâche selon
l'algorithme décrit dans la première partie.
Lorsque toutes les tâches ont terminé
de trier leur partition,
la procédure sort effectue un interclassement
des partitions triées afin d'obtenir
finalement le tableau trié.
Question 2.1 :
Ecrire la procedure sort_partitions, dont la signature est :
procedure sort_partitions(tab : in out table; from, to : table_range);
La procédure sort_partitions trie les éléments du tableau tab compris entre les éléments
from et to (from et to sont inclus dans le tri).
Question 2.2 :
On suppose que la procédure d'interclassement des partitions triées est donnée. Sa signature
est la suivante :
procedure merge_partitions(sorted_table : in out table; sorted_partitions : in table);
merge_partitions prend en entrée un tableau sorted_partitions
contenant des partitions triées et renvoit dans sorted_table un tableau complètement trié.
Proposer une nouvelle implantation de la procédure sort afin d'effectuer
le tri comme il est décrit ci-dessus.
Vous n'utiliserez pas d'objet ou de type protégé.
Troisième partie : tri parallèle version 2
La technique de tri précédente est pénalisée par le temps
nécessaire
à l'interclassement des partitions. En effet, cette dernière
opération reste
séquentielle et l'on souhaite augmenter encore
le parallélisme de la procedure sort.
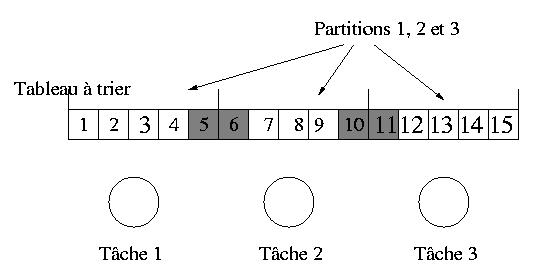 On découpe toujours le tableau en N partitions.
Chaque partition continue a être triée
par une tâche.
On découpe toujours le tableau en N partitions.
Chaque partition continue a être triée
par une tâche.
Toutefois, dans cette nouvelle version, les extrémités de chaque partition
sont partagées entre les tâches adjacentes. Ainsi :
- La tâche 1 trie les cases 1,2,3,4,5 et 6.
- La tâche 2 trie les cases 5,6,7,8,9,10 et 11.
- Enfin la tâche 3 trie les cases 10,11,12,13,14 et 15.
Les cases 5,6,10 et 11 sont donc partagées par plusieurs
tâches (cf. figure ci-dessus).
Avec cette nouvelle méthode, la procédure sort n'a plus
besoin d'interclasser les différentes partitions.
Question 3.1
Donnez une implantation de la procédure sort afin
d'effectuer le tri comme il est décrit ci-dessus.
Vous n'utiliserez pas d'objet ou de type protégé.
Exercice 20 : Arbre binaire et paquetages génériques
Dans cet exercice, nous explorons les arbres binaires en Ada.
- Récupérer,
compiler et tester ces unités de compilation.
Les fichiers arbres.ads et arbres.adb
implantent un arbre binaire en Ada.
- Un noeud de l'arbre est un pointeur de cellule.
Chaque cellule mémorise une information de type integer ainsi que
deux noeuds fils : un noeud droit dont le pointeur est mémorisé par
la variable droit et un noeud gauche dont le pointeur est mémorisé par
la variable gauche.
- La fonction somme vous montre comment parcourir cet arbre et effectuer la somme
des valeurs mémorisées dans ses noeuds: à partir d'un noeud, il
est nécessaire de parcourir les noeuds fils gauche et droit si ceux ci existent.
Un noeud ne comporte pas de noeud fils gauche (respectivement droit)
lorsque son pointeur de cellule gauche (respectivement droit) a la valeur
null.
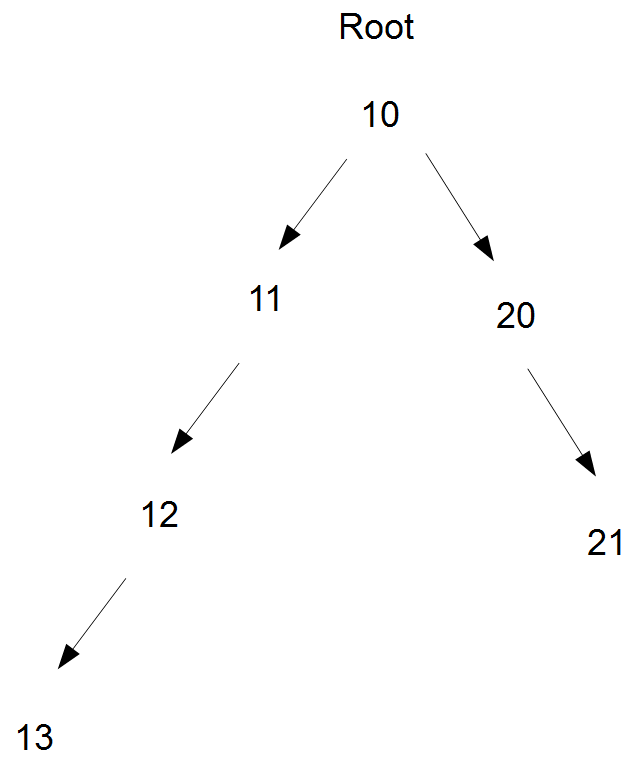
- Le fichier marbre.adb montre un exemple d'arbre calculant la somme des
informations d'un arbre construit à l'aide des méthodes ajouter_gauche et ajouter_droit.
La figure ci-dessus représente cet arbre et la
variable root mémorise sa racine.
Question 1 :
Ajouter dans le paquetage arbre.ads une
procédure put qui affiche les informations de tous les noeuds d'un arbre.
Le procédure put doit parcourir l'arbre binaire de façon similaire à la fonction somme.
Vous donnerez une procédure principale permettant de tester votre procédure.
Question 2 :
Le paquetage arbre.ads de cet exercice permet de mémoriser des informations
de type integer uniquement.
Proposez une version générique de ce paquetage permettant
d'étendre son utilisation à d'autres
types de données pour lesquels les opérations d'affectation et de comparaison sont possibles (entiers, réels, ....).
Le paquetage a fournir pour cette question doit contenir la procédure Put et la fonction somme.
Vous donnerez une procédure principale permettant de tester votre paquetage générique sur un
arbre dont les noeuds mémorisent des valeurs de type réel.
Notez que la fonction somme utilise l'opérateur + qui n'est
disponible que pour quelques types susceptibles d'être utilisés pour
l'instanciation (integer, float, ...) et qui devra être remplacé par un paramètre du générique.
Exercice 21 : Parallélisation d'un programme Ada
Dans cet exercice, nous regardons comment transformer un programme séquentiel en un ensemble de tâches Ada
afin d'améliorer les performances du programme.
Récupérer
puis compiler et tester ce programme
Ce programme fait la somme de deux matrices A
et B, puis, mémorise le résultat de cette opération dans la matrice C avant
de l'afficher à l'écran.
Dans ce programme, une matrice est un tableau à deux dimmensions
comportant 3 lignes et 3 colonnes. Notez comment en Ada nous accédons à un élément dans
un tableau à deux dimmensions : A(i,j) permet de récupérer
l'élément en ligne i et en colonne j du tableau A.
Enfin, la procédure add_ligne permet d'ajouter une ligne donnée de deux
matrices Operande1 et Operande2, puis, de mémoriser le résultat dans une matrice Resultat.
On vous demande de modifier ce programme afin d'exécuter l'addition de chaque ligne des matrices
par une tâche Ada différente.
Ceci doit permettre d'accélerer les calculs lorsque la matrice est grande. Pour ce faire,
on vous demande d'implanter le
fonctionnement ci-dessous.
La procédure principale doit appliquer l'algorithme suivant :
- La procédure principale lance l'exécution de 3 tâches : chaque tâche effectue les calculs
d'une ligne de la matrice.
- Chacune des 3 tâches doit recevoir grâce à un rendez vous avec la
procédure principale le numéro de ligne dont elle doit faire les calculs.
- Notez que chaque tâche utilise une ligne différente des matrices
A, B et C : il n'y a donc pas de donnée manipulées par plus d'une tâche.
- Une fois que les 3 tâches ont démarré leur calcul, la procédure principale attend
successivement la terminaison des 3 tâches par un second rendez-vous, puis, affiche la matrice C.
Exercice 22 : mise en oeuvre d'une FIFO
La spécification ci-dessous décrit un type abstrait
générique implantant une file
d'attente de type FIFO. On rappelle que dans une FIFO,
les éléments à insérer le sont en queue de la FIFO et
les éléments à retirer le sont
en tête de la FIFO.
L'interface ci-dessous est paramétrée par deux informations : la taille maximale de la FIFO
qui est par défaut de 10000 éléments et le type des éléments stockés dans la FIFO.
generic
type element is private;
size : natural := 10000;
**** à eventuellement compléter ****
package fifo is
procedure inserer_en_queue(e : in element);
procedure retirer_en_tete(e : out element);
procedure put;
procedure clean;
end fifo;
Question 1 :
- Donner une implantation du paquetage FIFO de sorte que :
- Pour cet exercice, la seule partie pouvant être modifiée dans la
spécification du paquetage est la liste des paramètres du générique.
- La procédure inserer_en_queue doit afficher une erreur lorsqu'elle est
invoquée alors que la FIFO est pleine.
- La procédure retirer_en_tete doit afficher une erreur lorsqu'elle
est invoquée alors que la FIFO est vide.
- La procédure put permet d'afficher à l'écran le contenu de la FIFO.
- La procédure clean permet de vider la FIFO, i.e. supprimer l'ensemble des
éléments stockés dans la FIFO.
- Vous donnerez également une procédure principale permettant de tester son bon fonctionnement.
-
On vous demande ici une implantation qui puisse être utilisée sans tâche Ada, en dehors de la
procédure principale.
Question 2 :
Le paquetage ci-dessus a été concu pour être utilisé sans tâche Ada, en dehors de la procédure principale.
Quels problèmes classiques posent l'accès direct à une instance
du paquetage fifo par plusieurs tâches ? Vous décrirez
un scénario d'ordonnancement qui illustre ces problèmes.
Question 3 :
Proposez un nouveau programme Ada utilisant une nouvelle version du paquetage ci-dessus et constitué de 5 tâches :
- Les deux premières tâches insèrent dans la FIFO des éléments de type flottant.
- Les trois dernières tâches retirent les flottants, puis, les affichent.
- La procédure inserer_en_queue doit bloquer une tâche invoquant la procédure
lorsque la FIFO est pleine.
- La procédure retirer_en_tete doit bloquer une tâche invoquant la procédure
lorsque la FIFO est vide.
-
Vous expliquerez en quoi ce nouveau programme règle les problèmes soulevés dans la question 2.
L'objectif du projet est d'implanter un logiciel pour simuler l'ordonnancement d'un jeu
de tâches périodiques manipulant des resources partagées.
On vous donne une première version de ce logiciel. Ce logiciel est constitué de plusieurs
paquetages et permet d'ordonnancer un ensemble de tâches périodiques selon Rate Monotonic.
Le logiciel
est disponible ici.
Pour compiler et exécuter ce programme, vous devez utiliser le compilateur sur Linux
qui est accessible par la commande suivante :
source ada.csh.
Ce programme est composé des paquetages suivants:
- Paquetage tasks qui définit et implante le concept
de tâche périodique manipulé par le simulateur.
- Paquetage schedulers, qui implante l'ordonnanceur à proprement dit.
Dans la version de paquetage donnée, seul Rate Monotonic est implanté.
La procédure principale
main
est un exemple d'utilisation de ces paquetages. Ce programme définit 3 tâches
pour lesquelles l'ordonnancement va être calculé.
Travail à faire:
Pour ce projet:
- Vous pouvez travailler en groupe de 2 étudiants (pas plus).
- Votre travail sera livré le 19 janvier 2016 dernier délai par email à singhoff@univ-brest.fr
- Vous devez livrer à la fois le code de votre solution, mais aussi
un petit rapport expliquant votre travail.
- Vous serez aussi évalué lors d'une démonstration organisée
le 19 janvier après midi.
- Enfin, il est strictement interdit d'intégrer un morceau de code que vous n'avez
pas écrit.
Question 1 : test du simulateur
- On suppose un jeu de tâches périodiques
défini par les paramètres suivants: S1=S2=S3=0, P1=5, C1=1, P2=10,
C2=3, P3=30 et C3=8.
Calculer manuellement l'ordonnancement selon
un algorithme preemptif Rate Monotonic. Le jeu de tâches
est il ordonnançable ?
- Modifiez main.adb afin d'exécuter
le jeu de tâches ci-dessus, compilez et testez ce programme.
Vérifiez que l'ordonnancement généré par ce programme est identique à celui
que vous aviez calculé à la main lors de la question précédente.
- Dans la procédure principale main.adb et le fichier scheduler.adb,
trouvez :
-
Où et comment les tâches de ce système sont initialisées.
- Où et comment les réveils périodiques des tâches sont implantés.
Question 2 : implanter la prise en compte de ressource partagée avec des sémaphores
Modifier le programme afin d'implanter
le concept de sémaphore.
On cherche ici à simuler un ensemble de tâches périodiques accédant à une ressource critique
protégée par un sémaphore.
Chaque sémaphore doit permettre d'établir une section critique.
On suppose dans cette question que les sémaphores n'implante pas d'héritage de priorité.
Vous expliquerez votre mise en oeuvre dans votre rapport.
Par ailleurs, vous testerez votre programme avec au moins trois jeux de tâches
dont un au moins qui conduit à une inversion de priorité.
Vous décrirez ces jeux de tâches et leur ordonnancement
dans votre rapport.
Pour chaque ordonnancement calculé, l'outil doit aussi indiqué les instants où
les ressources partagées sont allouées et libérées ; c-à-d quand le sémaphore est
alloué, libéré et quand une tâche est bloquée sur un sémaphore modélisant une ressource
déjà allouée.
Pour rappel : le cours d'ordonnancement ainsi que le TD associé contient un exemple de
jeu de tâche conduisant à une inversion de priorité.
Question 3 : implantation de PIP et de PCP
Pour cette dernière question, on vous demande d'implanter les protocoles
PIP et PCP dans le simulateur.
Ces protocoles sont décrits dans ce document.
Vous pouvez lire ce document afin d'étudier ces deux protocoles avant de les implanter dans votre simulateur. Par ailleurs,
pour rappel, le cours d'ordonnancement ainsi que le TD associé contient un exemple
d'ordonnancement PIP (exercice 9) ainsi qu'un exemple avec PCP (exercice 12).
Vous avez le droit d'utiliser toute ressource documentaire afin de comprendre comment fonctionne PIP et PCP.
Pour cette dernière question, on vous demande d'ajouter dans votre rapport:
- Une comparaison des protocoles PCP et PIP
tant du point de vue de leur fonctionnement que de leurs propriétés.
- L'ordonnancement généré par votre programme pour un minimum de trois jeux de tâches.
Vous décrirez également les jeux de tâches utilisés.
L'objectif du projet est d'implanter un logiciel pour simuler l'ordonnancement d'un jeu
de tâches apériodiques grâce à divers serveurs de tâches apériodiques.
On vous donne une première version de ce logiciel. Ce logiciel est constitué de plusieurs
paquetages et permet d'ordonnancer un ensemble de tâches périodiques.
Le logiciel
est disponible ici.
Pour compiler et exécuter ce programme, vous devez utiliser le compilateur sur Linux
qui est accessible par la commande suivante :
source ada.csh.
Ce programme doit être exécuté sur Linux.
Ce programme est composé des paquetages suivants:
- Paquetage tasks qui définit et implante le concept
de tâche manipulé par le simulateur.
- Paquetage schedulers, qui implante l'ordonnanceur à proprement dit.
Dans la version de paquetage donnée, seul Rate Monotonic est implanté.
La procédure principale
main
est un exemple d'utilisation de ces paquetages. Ce programme définit 3 tâches
ordonnancées selon
Rate Monotonic.
Travail à faire:
Pour ce projet:
- Vous pouvez travailler en groupe de 2 étudiants (pas plus).
- Votre travail sera livré avant le 17 janvier 2014 par email à singhoff@univ-brest.fr
- Vous devez livrer à la fois le code de votre solution, mais aussi
un petit rapport expliquant votre travail.
- Vous serez aussi évalué lors d'une démonstration organisée début janvier.
- Enfin, il est strictement interdit d'intégrer un morceau de code que vous n'avez
pas écrit.
Question 1 : test du simulateur
- On suppose un jeu de tâches périodiques
défini par les paramètres suivants: S1=S2=S3=0, P1=5, C1=1, P2=10,
C2=3, P3=30 et C3=8.
Calculer l'ordonnancement selon
un algorithme preemptif Rate Monotonic. Le jeu de tâches
est il ordonnançable ?
- Modifiez main.adb afin d'exécuter
le jeu de tâches ci-dessus, compilez et testez ce programme.
Vérifiez que l'ordonnancement généré par ce programme est identique à celui
que vous aviez calculé à la main lors de la question précédente.
- Dans la procédure principale main.adb et le fichier scheduler.adb,
trouvez :
-
Où et comment les tâches de ce système sont initialisées.
- Où et comment les réveils périodiques des tâches sont implantés.
Question 2 : implanter le serveur à scrutation
Modifier le programme afin d'implanter le serveur à scrutation (ou "polling server").
On rappelle que le serveur à scrutation ordonnance des tâches apériodiques
de la façon suivante (cf page 20 du cours sur l'ordonancement temps réel):
- Le serveur exécute les tâches apériodiques arrivées avant le reveil
du serveur.
- Si au réveil du serveur, aucune tâche apériodique n'est présente, alors le serveur
ne consomme aucune unité de temps.
- A chacun de ses réveils, le serveur ne peut consommer plus que sa capacité, et ce
quelque soit le nombre de tâches apériodiques présentes dans le système.
Vous expliquerez votre mise en oeuvre dans votre rapport.
Par ailleurs, vous testerez votre programme avec au moins trois jeux de tâches.
Vous décrirez ces jeux de tâches et leur ordonnancement
dans votre rapport.
Question 3 : implanter un nouveau serveur apériodique
Pour cette dernière question, on vous demande d'implanter un autre serveur
de tâches apériodiques.
Il existe plusieurs autres serveurs décrits dans
ce document.
On vous demande de lire ce document, de choisir un
serveur de tâches apériodiques, de le comprendre et de l'implanter dans ce logiciel.
Cet article présente plusieurs serveurs apériodiques:
le "polling server" (ou serveur à scrutation),
le "priority exchange server" et le "deferrable server".
Vous pouvez choisir d'implanter soit le "priority exchange server"
soit le "deferrable server".
Pour cette dernière question, on vous demande:
- D'expliquer dans le rapport comment fonctionne le serveur de tâches apériodiques
que vous avez sélectionné.
- De tester votre programme avec au minimum trois jeux de tâches. Vous décrirez ces jeux de tâches et leur ordonnancement
dans votre rapport.
L'objectif de ce projet est de réviser les parties Réseaux de Petri et Ada de l'UE STR.
Pour ce faire, on vous demande de réaliser un outil d'analyse des Réseaux de Petri.
Objectif de l'outil à réaliser
Le logiciel à réaliser doit offrir les fonctionnalités permettant:
- De lire, à partir d'un
fichier, la description d'un réseau de Petri ordinaire.
- De construire le graphe des marquages accessibles, ou à défaut
son arbre de couverture.
- D'effectuer une analyse du graphe de marquages afin d'en déduire
des propriétés du réseau de Petri à analyser.
Les propriétés à rechercher sont les suivantes : calcul de bornes du Rdp,
test de la vivacité et test de la quasi-vivacité.
Structure d'un fichier stockant un Rdp
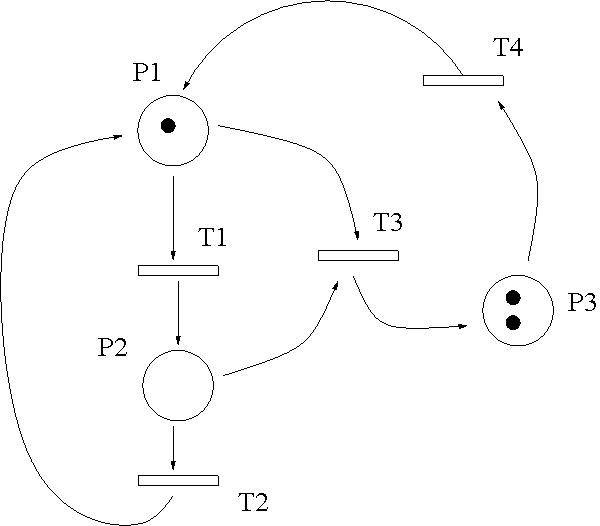
Figure 2. Exemple de réseau de Petri
On suppose que les réseaux de Petri à analyser sont stockés dans
des fichiers XML ayant la structure suivante :
- La description d'un Rdp est délimitée par le couple de balises
<petrinet> </petrinet>.
- La description d'un Rdp est constituée d'une liste de places, de transitions
et d'arcs.
- La définition d'une place est délimitée par le couple de balises <place> </place>.
On stocke entre ces balises le nom de la place ainsi que son marquage initial.
- La définition d'une transition est délimitée par le couple de balises
<transition> </transition>.
On stocke entre ces balises le nom de la transition.
- La définition d'un arc entre une place et une
transition est délimitée par le couple de balises
<arrow> </arrow>.
On stocke entre ces balises la place/transition de départ et la place/transition d'arrivée.
Ainsi, le Rdp de la figure 2 sera décrit par un fichier contenant la description
suivante :
<petrinet>
<place> P1 1 </place>
<place> P2 0 </place>
<place> P3 2 </place>
<transition> T1 </transition>
<transition> T2 </transition>
<transition> T3 </transition>
<transition> T4 </transition>
<arrow> P1 T1 </arrow>
<arrow> T1 P2 </arrow>
<arrow> P2 T2 </arrow>
<arrow> T2 P1 </arrow>
<arrow> P1 T3 </arrow>
<arrow> P2 T3 </arrow>
<arrow> T3 P3 </arrow>
<arrow> P3 T4 </arrow>
<arrow> T4 P1 </arrow>
</petrinet>
Matériel disponible
Pour réaliser votre projet, vous disposez des ressources suivantes :
- D'un mini livre sur Ada en ligne ainsi que des livres
- D'exemples de programmes Ada. Vous devez regarder en particulier les
programmes suivants :
- Le programme unbounded_strings.adb qui utilise
le paquetage Ada.Strings.Unbounded : ce programme vous montre comment manipuler des chaînes de caractères de taille
quelconque avec Ada. Vous aurez nécessairement besoin de ces chaînes de caractères pour ce projet. En effet,
les chaînes Ada classiques sont très contraignantes.
- Les programmes gestionsfichiers.adb, gestionsfichiers2.adb
et gestionsfichiers3.adb : programmes qui vous montrent comment lire des fichiers
avec Ada. Ces programmes utilisent les paquetages GNAT.Directory_Operations, Ada.Sequential_IO
et Ada.IO_Exceptions.
- Le programme find.adb : qui permet de découper une chaîne de caractères afin d'y extraire une
sous-chaîne donnée.
- Du Web .... beaucoup de ressources sur Ada y sont disponibles.
Vous trouverez toutes ces informations à partir de l'URL :
http://beru.univ-brest.fr/~singhoff/DOC/LANG/ADA/
Organisation et évaluation du travail
Vous travaillerez en groupe de 4 étudiants.
Chaque étudiant est responsable d'une partie du projet. Ainsi:
- Un premier étudiant sera responsable du jeu de tests. Chaque test doit
pouvoir tester le logiciel pour un Rdp donné et doit être stocké dans un fichier XML.
- Un second sera responsable de la lecture des fichiers XML.
- Un troisième sera responsable de la construction du graphe de marquages accessibles.
- Un quatrième sera responsable des algorithmes d'analyse du graphe de marquage.
Une démonstration sera organisée début février. La date sera communiquée après
l'élaboration des emplois du temps du semestre 8.
Le jour de la démonstration, chaque groupe devra
livrer :
- Le logiciel à proprement dit (collection de paquetages Ada).
- Un jeu d'essais (ensemble de fichiers XML décrivant un ensemble de Rdp
utilisé pour valider le logiciel).
- Un mini rapport
décrivant :
- L'état d'avancement de l'outil (fonctionnalités offertes
par l'outil réalisé).
- Un mode d'emploi succinct de l'outil (comment le compiler et l'utiliser).
-
La façon dont le travail en groupe aura été effectué (description
des rôles/contributions/responsabilités de chaque étudiant).
Vous serez évalué selon les critères suivants (dans le désordre) :
- Réponse aux questions posées pendant la démonstration.
- Fonctionnalités de l'outil réalisé.
- Qualité de la conception détaillée (utilisation de génériques
pour les types abstraits de données, utilisation de design-patterns,
découpage du logiciel en paquetages ...).
- Propreté du logiciel.
- Qualité du jeu d'essai.
- Robustesse du logiciel.
L'objectif de ce travail est de développer un logiciel permettant de simuler des algorithmes
d'ordonnancement temps réel.
Ce logiciel est composé de plusieurs paquetages disponibles
dans le répertoire.
Pour compiler ce programme, vous pouvez utiliser gnatmake ou GPS par exemple.
Si vous ne disposez pas de compilateur Ada sur votre machine,
vous en trouverez ici pour Windows et Linux.
Ce logiciel est composé des unités de programmes suivantes:
- Le paquetage user_level_tasks définit et implante les tâches
qui sont manipulées par le simulateur. Ces tâches
interagissent avec le simulateur via deux méthodes :
- Par rendez-vous afin de simuler l'exécution
des unités de temps. L'entrée wait_for_processor
indique au simulateur
que la tâche est prête et qu'elle attend pour simuler
l'exécution d'une unité de temps.
L'entrée
release_processor est invoquée par la tâche en
cours de simulation afin d'avertir l'ordonnanceur
que la simulation
d'une unité de temps est terminée.
L'entrée release_processor indique donc au simulateur que le processeur
doit être ré-alloué selon la méthode d'ordonnancement choisie.
- Par objet protégé. L'objet protégé user_level_scheduler
stocke les données manipulées par le simulateur. Ces données
sont protégées afin de permettre aux différentes tâches
et à l'ordonnanceur de les consulter et
de les modifier de façon concurrente. Notez qu'avec l'exemple donné
ici, cette protection par objet protégé
n'est pas nécessaire. Elle est requise lorsque plusieurs ordonnanceurs doivent cohabiter
(cas d'un ordonnancement multiprocesseurs). Les données
protégées sont la liste des tâches (variables
tcbs et
number_of_tasks), l'heure courante de simulation (variable current_time), ...
- Le paquetage user_level_schedulers définit et implante
le simulateur. La version fournie implante une seule
méthode d'ordonnancement : un ordonnancement Rate Monotonic.
La procédure principale example et le paquetage my_subprograms
constitue un exemple d'utilisation de ce simulateur:
- Le paquetage my_subprograms contient le code de chaque tâche
périodique. Ce code
est exécuté pour simuler une unité de temps. Il s'agit ici
d'un simple affichage.
- La procédure principale example
définit trois tâches périodiques ordonnancées par Rate Monotonic.
Travail à faire:
La note de ce projet constituera la note de CC de l'UE STR.
Vous pouvez travailler seul ou en binôme.
Vous devez envoyer votre travail par email à singhoff@univ-brest.fr et
nana@univ-brest.fr
au plus tard pour le lundi 4 mai.
Vous serez évalués selon les critères suivants :
- La conception détaillée : c'est à dire la structure
du logiciel et votre capacité à identifier et réutiliser des unités
de programme.
- Le niveau fonctionnel atteint (les algorithmes d'ordonnancement
effectivement implantés).
- Le présence de jeux de tests pertinents pour chaque
fonction implantée.
- La qualité du code
(propreté, fiabilité) ainsi que la documentation.
La présence d'un rapport, même succint, comportant un manuel
d'utilisation sera appréciée.
Question 1 : prise en main du simulateur
- Soit le jeu de tâches défini par S1=S2=S3=0, P1=5, C1=1, P2=10,
C2=3, P3=30 et C3=8. Dessiner le chronogramme
de l'ordonnancement de ces trois tâches
selon Rate Monotonic en mode préemptif.
Ce jeu de tâche est il ordonnançable ?
- Compiler et exécuter le programme example.adb.
Comparer le résultat
de la simulation avec votre chronogramme dessiné dans la question
précédente.
- Dans le programme example.adb, identifier
où et comment sont initialisées les tâches du système à simuler, où et comment est
sélectionnée
la tâche à exécuter, où et comment les réveils périodiques des tâches sont
implantés.
Question 2 : implantation de l'algorithme EDF
Ajouter une procédure au simulateur afin de calculer un ordonnancement
EDF. Vous donnerez obligatoirement un jeu de tests (c'est à dire des
jeux
de tâches avec l'ordonnancement attendu sous la forme d'un chronogramme
ainsi que l'ordonnancement obtenu par le simulateur).
Votre simulateur devra supporter des tâches périodiques,
apériodiques et sporadiques.
Une tâche apériodique est une tâche qui n'est réveillée qu'une seule fois:
elle arrive dans le système à un instant donné, effectue un
traitement, puis disparait. Une tâche sporadique a un
comportement similaire à une tâche
périodique. Comme une tâche périodique, une tâche sporadique est réveillée plusieurs
fois. Toutefois, son délai entre
deux réveils successifs n'est pas spécifié par une période.
Dans le cas d'une tâche sporadique, seul un délai minimum
entre deux réveils de la tâche est spécifié. Lors de l'exécution
(ou de la simulation) d'une tâche sporadique,
deux réveils successifs d'une tâche peuvent être
éloignés d'un délai plus grand que ce délai minimum.
Question 3 : implantation d'un nouvel algorithme d'ordonnancement
On vous demande d'implanter un nouvel algorithme dans
cet environnement de simulation.
L'algorithme à implanter est l'algorithme MUF.
Cet algorithme est décrit dans
l'article de Stewart et Khosla.
On vous demande de lire cet article, d'étudier le fonctionnement
de MUF
puis de l'implanter dans l'environnement de simulation.
Comme pour EDF, vous joindrez à votre solution un jeu de tests.
Soit le programme Ada
test_gdb.adb :
- Compiler avec les options de mise au point :
gnatmake -g -O0 test_gdb
- Lancer gdb (le code source de votre programme doit etre dqns le répertoire
de votre exécutable) :
gdb test_gdb
GNU gdb 4.17.gnat.3.13p -1
Copyright 1998 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "sparc-sun-solaris2.5.1"...
(gdb)
- Positionner un point d'arret :
(gdb) break b~test_gdb.adb:test_gdb
Breakpoint 1 at 0x1c0bc: file test_gdb.adb, line 8.
- Lancer le programme :
(gdb) run
Starting program: /home/enseignants/singhoff/test_gdb
[New LWP 2 ]
[New LWP 3 ]
Breakpoint 1, test_gdb () at test_gdb.adb:8
8 procedure test_gdb is
- Afficher le programme :
(gdb) list
3
4 with text_io;
5 use text_io;
6
7
8 procedure test_gdb is
9
10 i : integer :=100;
11
12 procedure inc(j : in out integer) is
- Executer une instruction avec next ou step :
(gdb) next
10 i : integer :=100;
(gdb) next
19 put(integer'image(i));
(gdb) next
10020 new_line;
- Visionner des donnees avec display ou print :
(gdb) print i
$1 = 100
(gdb) display i
1: i = 100
(gdb) next
21 inc(i);
1: i = 100
(gdb) next
22 put(integer'image(i));
1: i = 101
(gdb)
Soit la spécification du paquetage donnees ci-dessous :
package donnees is
taille_donnees : constant integer := 10;
task affiche;
procedure ajouter_donnees(une_donnee : in integer);
procedure vider_donnees;
procedure lire_resultats(plusgrand : out integer; pluspetit : out integer; moyenne : out integer);
end donnees;
Ce paquetage permet de stocker un ensemble des données de type integer ainsi
que de calculer la plus grande valeur, la plus petite valeur et la valeur moyenne.
Le comportement de ce paquetage doit être le suivant :
- Le paquetage permet de stocker au maximum taille_donnees données de type integer. Au démarrage du programme, aucune donnée n'est mémorisée dans le paquetage.
- La procedure ajouter_donnee permet de mémoriser une nouvelle donnée (argument une_donnee). Si lors de l'ajout, le nombre de données stockées est égal à taille_donnees, alors ajouter_donnee doit remplacer la plus ancienne donnée par la nouvelle.
- La procédure vide_donnees permet de supprimer toutes les données mémorisées dans le paquetage.
- La procédure lire_resultats calcule et renvoie à partir des données mémorisées la plus petite donnée, la plus grande donnée et la moyenne des données
- Plusieurs tâches peuvent invoquer simultanément les procédures ajouter_donnee, lire_resultats et vider_donnees.
- La tâche affiche est une tâche qui, dans une boucle infinie, affiche le nombre de données à l'écran. Entre deux séquences d'affichage, cette tâche doit attendre 5 secondes.
Travail à faire
- Proposer une mise en ouvre du paquetage de sorte que son comportement soit conforme aux exigences ci-dessus.
Tout choix, en particulier en cas d'imprécision du sujet, doit être justifié.
- Proposer une procédure principale permettant de tester au mieux le paquetage donnees. La qualité des tests sera un élément important lors de la notation.
On vous donne à compléter le programme suivant :
with text_io; use text_io;
procedure maitre is
nb_esclave : constant integer :=3;
type tampon is array (0..599) of integer;
donnees : tampon;
task type esclave is
entry donner_travail(debut : in integer; fin : in integer);
entry donner_somme(resultat : out integer);
end esclave;
begin
.
end maitre;
L'objectif est de faire calculer par 3 tâches esclaves la somme du tableau donnees
de façon concurrente, selon le modèle maitre/esclaves décrit par la figure ci-dessous :
- La procédure principale (qui est la tâche maitre), grâce à l'entrée donner_travail, lance le calcul des 3 tâches. Chaque tâche esclave calcule la somme de 100 éléments du tableau. Les éléments en position 0 à 99 sont additionnés par la première tâche esclave, les élements 100 à 199 par la seconde tâche 2 et les éléments 200 à 299 par la 3ième tâche. Les paramètres début et fin de l'entrée donner_travail permettent à la tâche principale d'indiquer à chaque tâche esclave les indices du tableau qu'elle doit additionner (ex : debut=0 et fin=99 pour la première tâche esclave).
- Quand les 3 tâches ont terminé leur calcul, elles transmettent le résultat avec l'entrée donner_somme à la procédure principale qui peut alors additionner ces 3 résultats intermédiaires. Ceci termine la première itération de calcul.
- Les étapes 1) et 2) sont répétées pour les indices du tableau 300 à 599 ; il s'agit de la seconde itération de calcul.
- Enfin, quand la seconde itération de calcul est terminée, la procédure principale peut alors présenter à l'écran la somme de tous les éléments du tableau en affichant le résultat de l'addition des 6 totaux intermédiaires produits par les 3 esclaves lors des 2 itérations.
Ecrire un programme Ada qui implante l'algorithme décrit ci-dessus.
Ecrire un programme Ada qui contient 10 tâches organisées en anneau comme indiqué dans la figure ci-dessus:
Exercice 36
Soit la spécification de paquetage :
package blackboard is
procedure write_message(message : in integer);
procedure read_message(message : out integer; has_message : out boolean);
procedure display_statut;
procedure reset_message;
end blackboard;
Ce paquetage implante un tableau noir, ou blackboard.
Dans un système embarqué, un blackboard permet de mémoriser un message produit par
des producteurs avant sa lecture par des consommateurs.
Ici le message est de
type integer. Un blackboard fonctionne de la façon suivante :
- Un blackboard peut être accédé simultanément par plusieurs tâches.
- Un blackboard stocke uniquement le dernier message reçu.
Initialement, le blackboard ne contient pas de message.
Lors du premier appel à write_message, le message passé en argument est mémorisé dans le
blackboard. Lors des appels suivants à write_message, le message mémorisé
est remplacé
par la moyenne du message
passé en argument de write_message et de celui précédemment mémorisé dans le
blackboard.
- read_message permet de lire la valeur actuelle du message.
Si un message est présent dans le blackboard, alors
has_message est positioné à true et la valeur du message est retournée.
Quand read_message est appelé alors que le blackboard
ne contient pas encore de message, alors la valeur false est affectée à has_message.
-
Un message peut être lu plusieurs fois avant que sa valeur soit modifiée par
write_message.
- reset_message permet d'effacer le message actuellement mémorisé : le blackboard revient
à son état initial.
- Enfin display_statut permet d'afficher à l'écran l'état du blackboard. Cette procédure
affiche si un message et présent ou non. La valeur du message est également affichée dans le cas
où un message est présent.
Ainsi, la séquence:
val : integer;
ok : boolean;
...
write_message(12);
write_message(10);
read_message (val,ok);
conduit à mémoriser successivement les valeurs 12 puis
11 dans le blackboard et permet donc d'affecter la valeur
11 à la variable val.
Question 1 :
Proposer une implantation de ce paquetage ainsi qu'une procédure
principale permettant de tester son fonctionnement.
Question 2 :
Proposer une version générique de ce paquetage afin :
- De mémoriser n'importe quel type de message (autre que
integer).
-
De choisir lors de l'instanciation du paquetage générique comment
combiner le message stocké et le nouveau message lors d'un appel à
write_message.
En effet, plutôt que de calculer la moyenne entre le message mémorisé et le message à mémoriser,
il peut être utile, par exemple, de prendre la plus grande des 2 valeurs, ou la plus petite valeur, ou
tout autre combinaison de ces 2 informations.
Question 3 :
A partir de la version générique du paquetage, proposer une procédure principale
constituée de 2 blackboards nommés B1 et B2
ainsi que de 9 tâches.
B1 mémorise un entier et B2 mémorise un flottant.
Lors de l'écriture d'un message alors qu'un message est déjà mémorisé dans le blackboard,
B1 calcule et mémorise la moyenne des 2 messages alors que B2 mémorise
la plus grande valeur des deux.
Une des 9 tâches écrit successivement dans une boucle
des données dans B1 puis dans B2.
4 tâches lisent B1 et affichent à l'écran les informations reçues.
Les 4 autres tâches lisent et affichent les informations de B2.
Exercice 27
Dans cet exercice, on vous demande d'écrire un programme concurrent
permettant de calculer si les entiers d'un tableau sont premiers.
On vous donne la fonction suivante:
function is_prime(n : in integer)
return boolean is
i : integer :=2;
begin
if(n <= 1) then
return false;
end if;
while( i < n ) loop
if(n mod i = 0) then
return false;
end if;
i:=i+1;
end loop;
return true;
end is_prime;
La fonction is_prime permet de vérifier si l'entier passé
en argument
est premier et retourne dans ce cas true.
On suppose l'extrait de programme suivant:
type index is new integer range 1..20;
valeurs : array (index'range) of integer := (4 ,6, 19, 765, 321, 766, 324, 124, 4577, 863,
234 ,758, 11249, 76511, 2321, 66, 924, 8924, 45732111, 877);
results : array (index'range) of boolean;
On vous demande d'écrire un programme Ada constitué
de 5 tâches dont le comportement est le suivant:
- La procédure principale doit instancier 4 tâches nommées esclaves par la suite.
- Chaque esclave applique la fonction is_prime pour une partie
des entiers du tableau
valeurs.
Le tableau results permet à ces tâches de stocker pour chaque entier
le résultat de l'appel à la fonction is_prime.
- Les 4 esclaves doivent s'exécuter en parallèle, permettant ainsi d'exploiter
la présence éventuelle de plusieurs coeurs de calcul.
- Chaque tâche utilise un indice i pour faire le calcul sur l'entier valeurs(i) et
stocker le résultat dans results(i).
Le tableau est partagé entre les esclaves comme suit: la tâche 1 utilise les indices
1 à 5 des tableaux valeurs et results, la
tâches 2 utilise les indices 6 à 10, la tâche 3
utilise les indices 11 à 15, et la tâche 4 les indices 16 à 20.
- Lorsque les 4 tâches ont terminé leur calcul, le tableau results
doit être affiché à l'écran
par la procédure principale.
Travail à faire :
Proposer un programme qui implante le fonctionnement ci-dessus.