We now try to write a C program that is running this periodic thread set.
For such a purpose, we must fill the
init.c
file in order to schedule this thread set according to Rate Monotonic.
The sourcecode you have to fill is shown by several stars.
Furthermore, before compiling, do not forget to fill up the system.h configuration file to allow resource
allocations.
Each thread T1 and T2 must run the function
periodic_task. The period is sent to each thread throught
the thread argument.
In this exercise, you have three issues to solve:
- Assign and set threads priorities according to Rate Monotonic.
- Ensure that thread T1 and T2 will start synchronously : T1 and T2 must be activated for
their first activation at the same time.
The
critical_instant variable stores the first release time for T1 and T2.
To reach this critical instant, the initialization thread (thread running POSIX_init
function) must not be preempted
before its completion (when it reaches its pthread_exit() statement).
To be sure that the initialization thread is completed without being preempted, you must
assign a higher priority level to the thread running POSIX_init.
- Implement periodic release times.
To implement that threads are released periodically, we need to use the nanosleep
and the clock_gettime functions.
Arithmetic operations on timespec structs can be made with
C functions of
files ts.h and
ts.c. clock_gettime functions will allow to measure when a thread
is completing its activation while nanosleep can be used to blocked the thread
until it reaches its next periodic release.
Question 1:
During this question, we experiment the synchronization tools provided by RTEMS.
First, download and save
the following file and put it in a directory called EXO3.
This program contains two threads reading a text stored in a shared
memory. The text is read character by character and is written to a second memory area.
- Compile and test the program. What can you see? Explain this behavior.
- Modify this program to correct this wrong behavior. For such a purpose, you can
use the pthread_mutex_lock and pthread_mutex_unlock functions
or the sem_wait and sem_post functions.
Question 2:
For this second question,
download and save
this new file and put it in the EXO3 directory.
This program implements a producer/consumer
synchronization.
The buffer stores only one character.
Producers write data in the buffer character by character.
Consumers read data from the buffer character by character.
The buffer is built with two counting semaphores
called
number_of_full_positions and number_of_empty_positions
(respectively initialized
with the values 0 and 1).
Those semaphores model/store the number of busy and empty positions into the buffer.
These semaphores allow you to block producers when no empty locations exist in the buffer and
respectively to block consumers when no full locations exist in the buffer.
The algorithm of a producer is :
while(1)
{
P(number_of_empty_positions);
Produce and put a character into the buffer;
V(number_of_full_positions);
}
The algorithm of a consumer is :
while(1)
{
P(number_of_full_positions);
Read and display a character from the buffer;
V(number_of_empty_positions);
}
- Implement and test the synchronization for a buffer of 1 character.
You have code to write at each location
where you can find the string 'XXX'.
Furthermore, do not forget
to fill up the system.h configuration file to allow resource
allocations.
- Change the program in order to define a buffer that is able to store upto
4 characters (e.g. a buffer composed of 4 positions).
The buffer must be a FIFO buffer.
- Change your program in order to allow several producers and several consumers
to handle your 4 positions buffer.
A monitor is a software component which is responsible for the allocation
and deallocation of resources by threads/processes/tasks.
Basically, a monitor provides to the threads an API composed of, at
least, two functions: one function to allocate the resources according to thread
requests, and a second function to release the resources.
To illustrate the use and the implementation of a monitor, we
follow an example of a streaming system composed of a set of threads.
This streaming system allows each thread to allocate buffers
and disks for the streaming of a given movie.
To get a high quality streaming (respectively low quality), a thread
must request a higher (resp. lower) number of disks and buffers.
In the sequel, we assume 3 threads:
- Thread A needs and requests 2 disks and 1 buffer.
- Thread B needs and requests 1 disk and 2 buffers.
- Thread C needs and requests 2 disks and 2 buffers.
The overall streaming system has 3 buffers and 3 disks.
Questions:
- Download and save
this new file and put it in the EXO4 directory.
This program is a first solution to this synchronization problem.
In this solution, we use counting semaphores to manage allocation/deallocation
of the disk and buffer resources. To avoid deadlock, each resource is allocated in the same order by
any threads.
-
Before compiling, fill up the system.h configuration file to allow resource
allocations.
Run, compile and study this solution. What can you say about scalability of such solution?
-
We now explore a solution with the private semaphore design pattern.
Update monitor.c by applying the private semaphore design pattern.
The objective of this exercise is to experiment an implementation
of the active redundancy design pattern for the POSIX interface/RTEMS.
Active redundancy is a process consisting of
a caller which invokes
several implementations of a function producing a result.
As calling several implementations means
producing several results,
a voting step
decides the actual value that
has to be returned to the caller.
The
file redundancy.h provides an implementation
of such service. Several redundant threads
run several implementations of a function and apply a vote
to decide the actual result.
This file contains:
-
The constant CONFIGURE_REDUNDANCY_MAXIMUM_VOTING defines
the maximal number of redundant threads run during a vote.
The actual number of threads is set by the
size attribute
(see pthread_redundancy_attr_t).
- All redundant threads run programs
that have the same signature defined
by voter_type. Redundant threads also
have the same scheduling parameters
such as priority.
- pthread_redundancy_attr_t defines the attributes
assigned to the redundant threads. There are 2 attributes:
size (for the number of redundant threads) and
priority (scheduling priority of the redundant threads).
-
The functions pthread_redundancy_attr_set/get/destroy/init allow to
initialize, set, get or destroy an attribute.
-
The function pthread_redundancy_init initializes a
pthread_redundancy_t struct and creates the number
of expected redundant threads. At completion of this function, the
redundant threads must wait for a vote request.
-
The function pthread_redundancy_vote sends a
vote request by waking up
the redundant threads. After beeing released, the
redundant threads run their program to compute their result.
When all redundant threads have produced their result,
a vote is made and the function returns the result to the caller.
pthread_redundancy_t contains the synchronizations and variables
required for a vote.
It defines variables to synchronize the redundant threads and to exchange the needed
data between them. You may extent this struct if needed, but
it contains at least:
- waitfor_barrier is a private semaphore to each
redundant thread to block it upto pthread_redundancy_vote
is called.
This semaphore is initialized with 0.
- completion_barrier is a private semaphore
to each redundant thread to block the caller
of pthread_redundancy_vote until
all redundant threads have completed their work.
This semaphore is also initialized with 0.
- results stores the result
produced by each redundant thread during a vote.
- voters is a table of function pointers storing
the programs run by each redundant thread during a vote.
- arg is an optional argument given to the voter
subprograms.
- attr is the attribute for the pthread_redundancy_t
struct.
-
The function pthread_redundancy_destroy releases resources
and stops the redundant threads.
Questions:
- Download, save
this file in a directory called EXO7.
- Read and analyze init.c. When the program will be fully implemented, it should produce this result:
TSIM3 LEON3 SPARC simulator, version 3.1.7 (evaluation version)
Copyright (C) 2022, Cobham Gaisler - all rights reserved.
This software may only be used with a valid license.
For latest updates, go to https://www.gaisler.com/
Comments or bug-reports to support@gaisler.com
This TSIM evaluation version will expire 2023-03-08
Number of CPUs: 2
system frequency: 50.000 MHz
icache: 1 * 4 KiB, 16 bytes/line (4 KiB total)
dcache: 1 * 4 KiB, 16 bytes/line (4 KiB total)
Allocated 8192 KiB SRAM memory, in 1 bank at 0x40000000
Allocated 32 MiB SDRAM memory, in 1 bank at 0x60000000
Allocated 8192 KiB ROM memory at 0x00000000
section: .text, addr: 0x40000000, size: 113984 bytes
section: .data, addr: 0x4001bd40, size: 3648 bytes
section: .jcr, addr: 0x4001cb80, size: 4 bytes
read 1216 symbols
tsim> run
Initializing and starting from 0x40000000
Call sensor1
Call sensor2
Call sensor3
my_result = 100 and diff = 1
Call sensor1
Call sensor2
Call sensor3
my_result = 100 and diff = 0
Explain what the program should do.
- Implement the missing C functions of
the redundancy.c file.
according to the design pattern
and test them with the provided init.c file.
The objective of this exercise is to implement the design pattern
thread pool.
This design pattern allows the programmer to create an array of threads that run
various requests.
Usually, a thread pool initially contains a given number of thread ; such number may or may
not change during the execution time of the application.
In the sequel, we assume that the number of thread cannot be changed during execution time: it is
set at the system initialization and cannot be changed later. This static thread pool is better
suited for critical real-time systems.
The file
pool.h is a the interface of this service. It contains the
following definitions:
-
CONFIGURE_MAXIMUM_POOL_SIZE is the maximum size of the pool.
The actual/real pool size is set with the
pthread_pool_attr_t attribute.
-
When a request is sent to the pool by a client, the request contains the function the thread is
supposed to run.
All functions run by the threads must comply with the
request_func_t type.
- All threads are run according to the scheduling parameters stored in
pthread_pool_attr_t.
pthread_pool_attr_t
has 2 parameters:
size (which is the fixed number of thread in the pool)
and
priority (which the priority used byb the threads
of the pool).
-
Functions pthread_pool_attr_set/get/destroy/init
allow to set/read/destroy and respectively initilize an attribute.
-
pthread_pool_init initializes the
pthread_pool_t struct and creates all the threads of the pool.
pthread_pool_init must be called after the attributes are set, .i.e when
pthread_pool_init is called, attribute changes do not change the pool be havior.
When initialized, the threads can handle the requests.
-
pthread_pool_request is called by the clients of the pool service.
pthread_pool_request sends a request to the pool : it
looks for an available thread and assign the request to it.
When the request is assigned, pthread_pool_request returns to
the client a request identifier. This identifier allows the client
to ask for the status of its request, i.e. if the request is completed or not.
A request identifier is implemented by the type
pthread_pool_request_t.
In the mean time, the assigned thread runs the request, i.e. it run the
function given by pthread_pool_request by the func argument.
At the worst case, no more than
size requests can be run simultaneously.
If pthread_pool_request is called when
size request are already running, then the function return
-1 and the value EBUSY is assigned to the variable errno.
- Function
pthread_pool_response allows the client to know if
the request identified by a pthread_pool_request_t
value is completed.
If the request is completed then
pthread_pool_response returns the value calculed by the thread.
If the request is not completed, then
pthread_pool_response waits for the request completion and sends back the result
to the callee.
In case of error
pthread_pool_response
returns NULL.
- pthread_pool_request_status returns 0 if the request is completed, -1 otherwise.
Contrary to pthread_pool_response, pthread_pool_request_status
does not block the client and returns immediatly.
- To synchronize the threads of the pool and the clients, we may use 2 counting
semaphores: one to allow an
idle thread to wait for a request and a second to block the client until the request is completed.
-
pthread_pool_destroy releases any resources allocated in the
pool and stops all the threads.
-
pthread_pool_t should contain any data or synchronization tool that
are required to implement the above semantics.
Question:
- Save
this file
in a specific folder.
- Read and analyze the file init.c.
- Implement pool.c to provide the services described above.
Test your implementation with init.c.
You may extend init.c if more tests have to be made.
Dans cet exercice, on souhaite implanter un moniteur permettant de gérer les
ressources partagées d'un contrôleur d'automate industriel.
Le contrôleur pilote 3 automates industriels. Le contrôleur est un programme
RTEMS composé d'une tâche par automate industriel, soit 3 tâches.
Chaque automate requiert deux types de ressources pour produire une pièce: des tapis roulants
et une certaine puissance électrique:
- L'automate 1 requiert 2 tapis et 4000 Watt.
- L'automate 2 requiert 1 tapis et 8000 Watt.
- L'automate 3 requiert 2 tapis et 5000 Watt.
On suppose que le contrôleur dispose de 3 tapis roulants et d'une puissance
électrique totale de 10000 Watt.
On vous demande d'implanter le controleur afin de gérer l'allocation
et la libération de ces ressources.
On suppose que chaque tâche controlant un des automates est construit de
la façon suivante:
void* tache_automate_1(...
{
allocate(1, 2, 4000);
printf("L'automate numéro 1 dispose des ressources nécessaires et travaille ...\n");
release(1, 2, 4000);
}
Dans cet exemple, les 3 paramètres des méthodes allocate et release sont
respectivement l'identifiant de la tâche, le nombre de tapis nécessaire et la
puissance électrique nécessaire.
On vous demande principalement d'implanter les méthodes
allocate et release.
Questions:
- Vous travaillez seul ou à deux. Tous les supports sont autorisés. La communication
entre groupes est par contre interdite. Une fois le travail terminé, vous devez
l'envoyer par email à singhoff@univ-brest.fr et attendre la réception
de l'email
avant de quitter la salle.
- Récupérer
ce fichier et sauvegarder le dans le répertoire EXO5.
-
Compléter ce programme (fichiers init.c et moniteur.c)
afin d'implanter le contrôleur d'automate industriel
décrit ci-dessus.
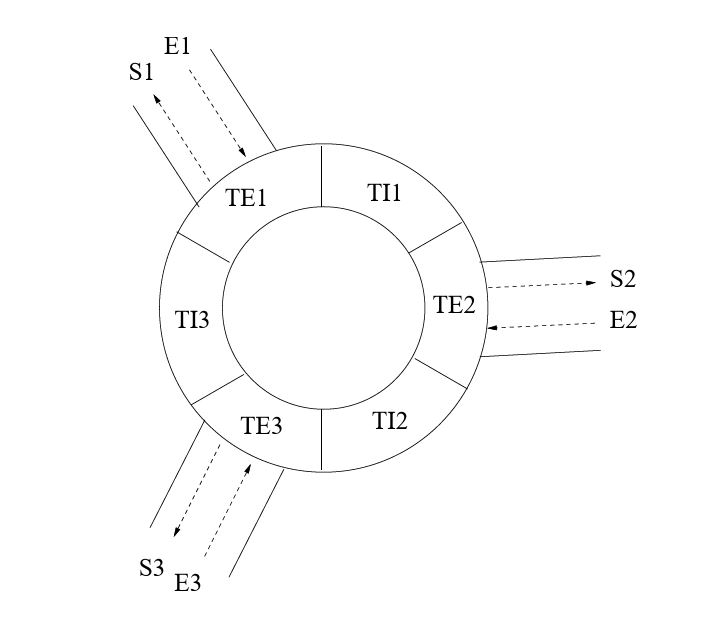
On considère un rond-point avec 3 voies entrantes E_1, E_2, E_3
et 3 voies sortantes
S_1, S_2, S_3.
Le rond-point comprend 3 tronçons d'échange (notés TE_1, TE_2 et TE_3)
pour l'entrée et la
sortie des voitures
et 3 tronçons internes (TI_1, TI_2 et TI_3) par lesquels
transitent les voitures
à l'intérieur
du carrefour. Au tronçon d'échange TE_i correspond l'entrée E_i et la sortie
S_i.
La figure ci-dessus résume la structure du rond-point.
Une voiture circule dans le rond-point jusqu'à
atteindre le tronçon d'échange correspondant à la sortie désirée.
D'un tronçon interne, une voiture passe au tronçon d'échange suivant.
D'un tronçon d'échange, une voiture peut soit sortir du rond-point, soit passer au tronçon interne
suivant.
Une voiture qui désire sortir par le tronçon d'échange par lequel elle est entrée doit faire
un tour complet.
Au plus maxe voitures peuvent se trouver dans un tronçon d'échange et au plus
maxi dans un
tronçon interne.
La priorité d'accès à un tronçon
est donnée aux voitures se trouvant sur le carrefour : une voiture qui désire entrer
dans le rond-point par l'entrée E_i ne peut le faire que si
le tronçon d'échange TE_i et le tronçon interne TI_i sont libres.
On souhaite modéliser le fonctionnement d'un tel système par un programme constitué
d'un ensemble de tâches RTEMS. L'accès au rondpoint est géré
par un moniteur dont l'interface est donné dans le fichier moniteur.h.
Le programme de simulation est constitué de plusieurs tâches dont le code est
similaire à celui ci:
/* Exemple d'un vehicule
*/
void un_vehicule (int id) {
/* Rentrer sur le segment TE2 depuis le segment E2 */
rentrer(id, 2);
/* Avancer dans le rond point (de TE2 vers TI1) */
avancer(id);
/* Avancer dans le rond point (de TI1 vers TE1) */
avancer(id);
/* Avancer dans le rond point (de TE1 vers TI3) */
avancer(id);
/* Sortir du rond point par le segment S3 à partir de TE3 */
sortir(id, 3);
}
Travail à faire
- Récupérer
ce fichier et sauvegarder le dans le répertoire EXO6.
-
Proposer une implantation du moniteur (fonctions init_moniteur, avancer,
rentrer et sortir)
afin de garantir les contraintes
d'accès aux ressources décrites ci-dessus.
Vous suivrez le patron de conception des sémaphores privés pour la mise en oeuvre de ce moniteur.
Cet exercice est à rendre sur moodle. Vous pouvez travailler à deux ou seul.
Si vous travaillez à deux, indiquer le nom des 2 étudiants dans vos fichiers.
Tous les documents sont autorisés pour ce TP.
L'objectif de cet exercice est d'implanter un modèle publisher-subscriber.
Le modèle publisher/subscriber est un modèle de communication et de synchronisation
permettant à différentes entités (threads, processus, etc) d'échanger des messages
de façon asynchrone. Ce modèle est construit avec 3 types d'entités :
- Les publishers qui émettent les messages.
- Les subscribers qui reçoivent les messages.
- Un canal dont le rôle est de recevoir
les messages émis par les subscribers, de les mémoriser, puis de les diffuser
auprès des subscribers destinataires. Le canal joue
donc le rôle d'intermédiaire (ou broker en Anglais).
Les principes fondamentaux de ce modèle de communication/synchronisation sont les suivants :
- Couplage faible des publishers et des subscribers. Les publishers émettent
des données vers le canal et ne connaissent pas directement les subscribers (et en
particulier leur nombre). Les subscribers reçoivent les messages depuis le canal et
ne connaissent donc pas directement les publishers (et en particulier leur nombre).
Ainsi, la population des subscribers (resp. publishers) connue par le canal peut évoluer
sans perturber le fonctionnement des publishers (resp. subscribers).
- Les messages sont étiquetés par un topic. Un publisher émet un message
pour un topic donné. Un subscriber demande et reçoit les messages d'un
topic donné ou de tous les topics selon son enregistrement au canal.
Un topic permet donc de sélectionner un sous-ensemble de destinataires.
Dans cet exercice, on se propose d'implanter ce modèle sur RTEMS avec une restitution
périodique des données aux subscribers
afin de rendre les communications utilisables pour les applications temps réels.
L'implantation à réaliser fonctionne de la façon suivante :
- L'application est composée
des fichiers suivants.
- Le canal et l'API permettant d'y accéder
sont implantés par les fichiers psmq.h et psmq.c
- Les messages sont décrits par le type pthread_psmq_message_t et
sont composés d'un champ topic
et d'un champ body qui contient le message à proprement dit.
- Le type pthread_psmq_t représente un canal et pthread_psmq_attr_t
constitue les attributs possibles
d'un canal.
- Plusieurs subscribers et publishers peuvent interagir simultanément avec un canal (en invoquant
simultanément pthread_psmq_publish et pthread_psmq_register_subscriber par exemple).
- Un canal comporte un tampon de taille fixe permettant de mémoriser
un maximum de CONFIGURE_MAXIMUM_MESSAGE_NUMBER messages. Le tampon est géré selon
la politique FIFO.
- L'ajout d'un message dans le canal par un publisher est réalisé par un appel à
pthread_psmq_publish.
Si le tampon
est plein
lors d'un appel à pthread_psmq_publish par
un publisher, alors le
publisher est bloqué
jusqu'au moment où une case devient disponible dans le tampon.
- Un appel à pthread_psmq_init permet d'initialiser un canal.
Lors de cette initialisation, un thread périodique appelé dispatcher est créé.
Ce thread périodique dispatcher consomme 1 message du tampon
à chacun de ses réveils périodiques et le
diffuse vers les subscribers destinataires.
Si à un réveil périodique aucun message n'est mémorisé dans le canal, alors le thread
dispatcher ne réalise
aucun traitement et attend son réveil périodique suivant.
- Si le tampon est plein et que le thread dispatcher libère une case, alors
un publisher en attente d'une case vide doit être reveillé afin d'enregistrer son message.
- Un appel à la fonction pthread_psmq_register_subscriber permet d'enregistrer un
subscriber dans un canal.
Un subscriber est identifié par un nom qui est une chaine de caractères donnée lors de
son enregistrement (paramètre char* subscriber_name
de pthread_psmq_register_subscriber).
Lors de l'enregistrement d'un subscriber, celui-ci fournit également
la fonction qui doit être invoquée par le canal pour livrer un message
(paramètre subscriber_handler_t handler)
ainsi
que le topic (paramètre char* topic) permettant de sélectionner les messages à
recevoir.
Si le paramètre topic est une chaine vide, alors le subscriber reçoit tous les messages
diffusés. Le subscriber reçoit uniquement les messages avec le même topic si ce paramètre n'est pas
une chaine vide.
Une fois inscrit, le subscriber peut recevoir un message au prochain réveil
du thread dispatcher par invocation de son handler par le
dispatcher.
- La fonction pthread_psmq_destroy permet de détruire un canal existant
et en particulier son thread dispatcher.
- Les attributs d'un canal pthread_psmq_attr_t permettent de configurer l'ordonnancement
du thread dispatcher en terme de priorité, politique d'ordonnancement et de période de réveil.
psmq.h/psmq.c permet de lire et de modifier
ces différents attributs.
- L'application est également configurée par les constantes suivantes:
- CONFIGURE_MAXIMUM_PSMQ_BODY_SIZE, qui est la taille maximale d'un champ body
- CONFIGURE_MAXIMUM_PSMQ_TOPIC_SIZE, qui est la taille maximale d'un champ topic
.
Travail à faire:
- Récupérer
ces fichiers et sauvegarder les dans le répertoire EXO9.
-
Proposer une implantation pour psmq.h et psmq.c
respectant le fonctionnement décrit ci-dessus.
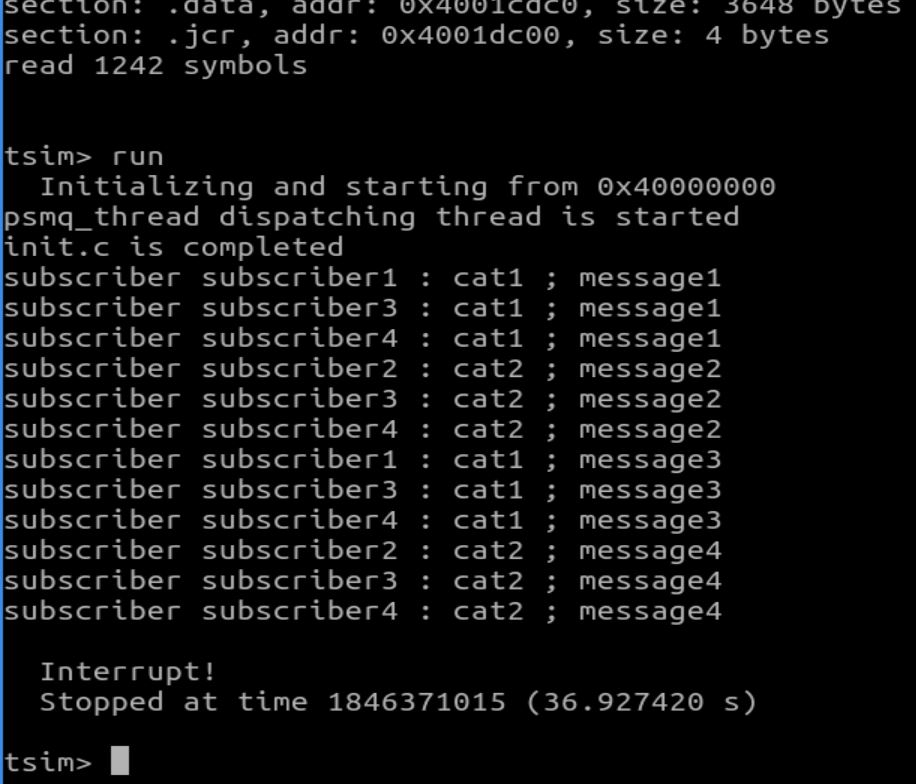
Le programme init.c constitue un exemple d'utilisation de psmq.c/h, et
vous avez ci-dessous
une trace possible de son exécution :
Vous déposerez votre travail
sur ce moodle
Cet exercice est à rendre sur
ce moodle.
Vous pouvez travailler à deux ou seul.
Si vous travaillez à deux, indiquer le nom des 2 étudiants dans votre modèle ou dans le
fichier contenant la réponse aux questions ci-dessous.
Tous les documents sont autorisés pour ce TP.
L'objectif de cet exercice est d'implanter un modèle scatter-gather.
Le modèle scatter-gather est une implantation du modèle de parallélisation SPMD (Single Program
Multiple Data) où le même calcul est fait sur un grand nombre de données par un
ensemble de tâches.
Dans ce modèle, un calcul est réalisé en 3 phases :
- Scatter. Les données sur lesquelles le calcul doit être effectué (le tableau data_input par la suite)
est découpé en n parties, n étant le nombre de tâches qui seront
utilisées pour le calcul.
- Calcul. Chaque tâche effectue le calcul sur une des n parties du tableau
data_input.
Chaque tâche produit à cette étape une donnée de sortie sous la forme
d'un tableau nommé data_output.
- Gather. Lorsque toutes les tâches ont terminé leur calcul, alors les n
tableaux data_output sont regroupés pour un éventuel calcul final.
On vous demande d'implanter ce patron de conception en respectant les exigences suivantes:
Question 1 :
- Récupérer
ces fichiers et sauvegarder les dans le répertoire EXO10.
-
Proposer une implantation pour spmd.h et spmd.c
respectant le fonctionnement décrit ci-dessus.
Le programme init.c constitue un exemple d'utilisation
de spmd.h/.c. Dans cet exemple, une opération
de scatter permet de répartir un tableau vers 3 threads.
Chaque thread recherche l'entier maximal. Après l'opération gather,
l'initiateur du calcul recherche la valeur maximale parmi les résultats
de chaque thread.
Question 2 :
Proposez un ensemble de tests unitaires pour ce patron de conception.
