
Cheddar is a free real time scheduling framework. Cheddar is designed for checking task temporal constraints of a real time application/system. It can also help you for quick prototyping of real time schedulers. Finally, it can be used for educational purpose. Cheddar is a free software, and you are welcome to redistribute it under certain conditions; See the GNU General Public License for details. The Cheddar project was started in 2002 by the LISyC Team, University of Western Britanny. Since 2008, Ellidiss technologies also contributes to the development of Cheddar and provides industrial support.
WARNING : this user's guide supposes that you have a minimum background on real time applications/systems and real time scheduling. If it's not your case, take a look on this link which includes some very basic articles or book references. This link also provides a description of the analytical methods implemented into Cheddar and gives some publications that show how to use Cheddar.
In this chapter, you find a description of the most important scheduling and feasibility services provided by Cheddar in the case of independent tasks.
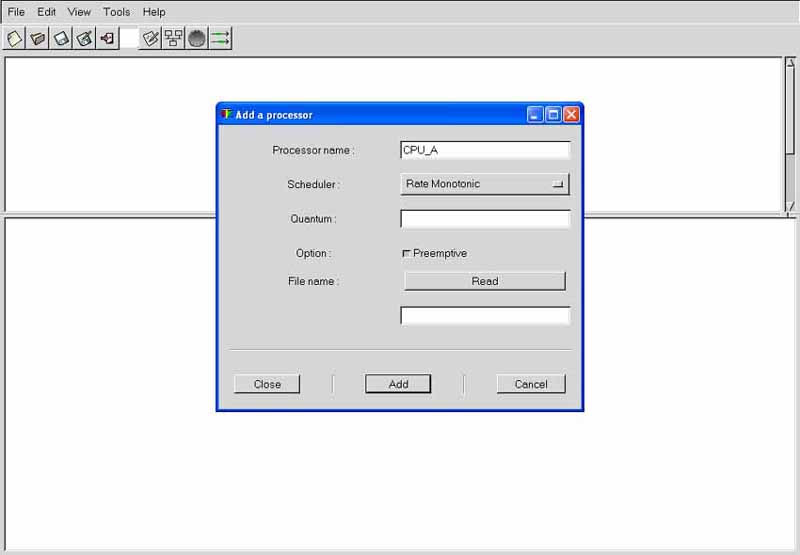
Cheddar provides tools to check temporal constraints of real time tasks. These tools are based on classical results from real time scheduling theory. Before calling such tools, you have to define a system which is mainly composed of several processors and tasks. To define a processor, choose the "Edit/Update processors" submenu. The window below is then displayed :
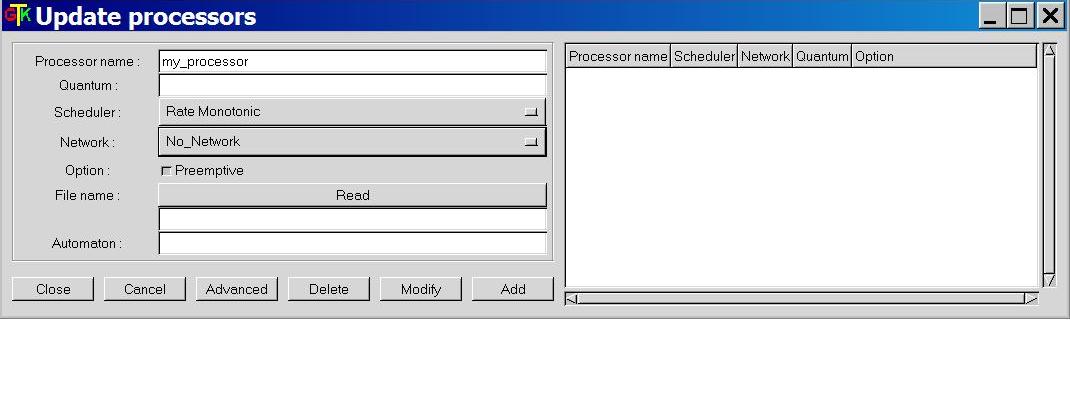
A processor is defined by the following fields (see Figure 1.1) :
Let see now, how to define a task, the last feature required to perform
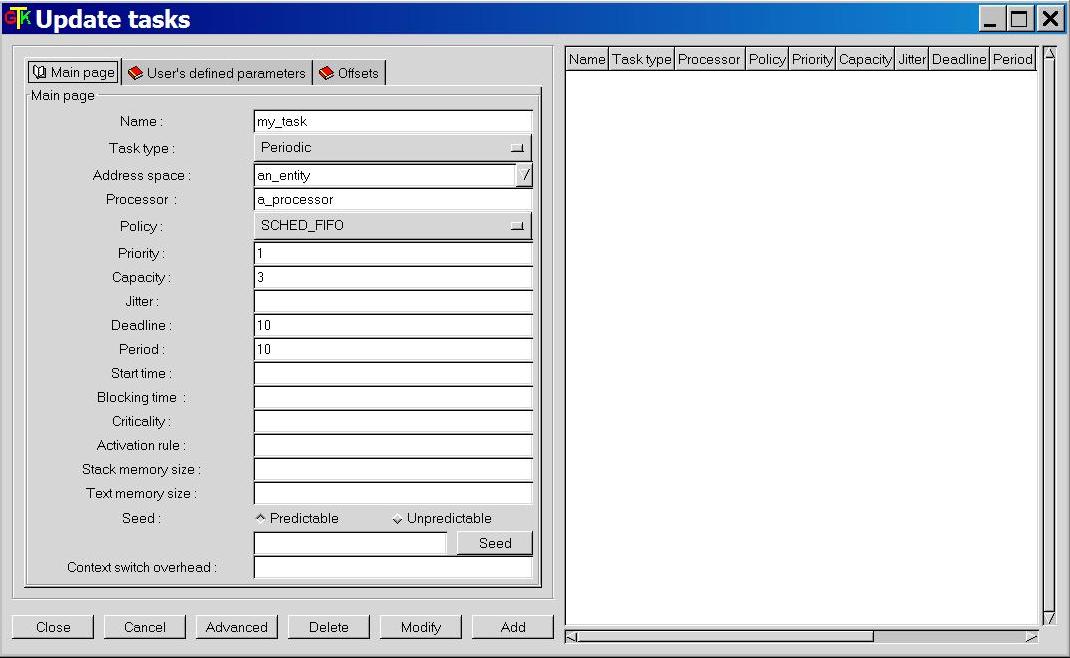
the most simpliest performance analysis. Choose the "Edit/Update tasks" submenu.
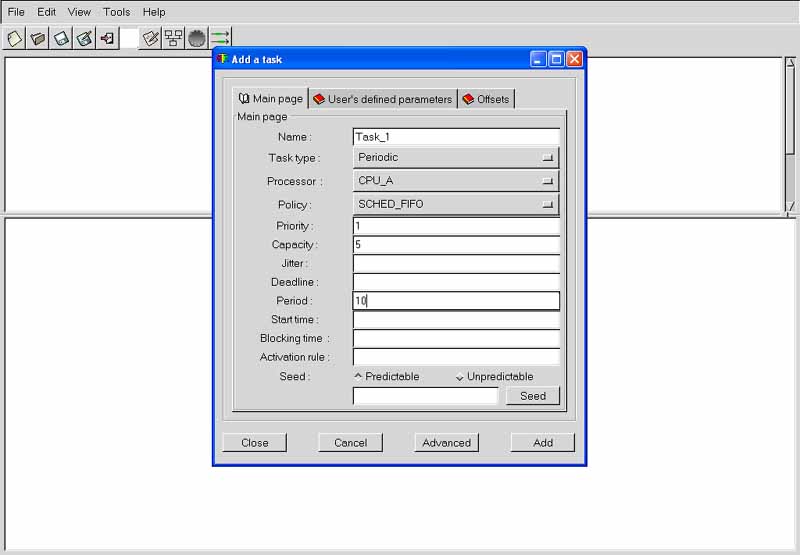
The window of Figure 1.3 is then displayed.
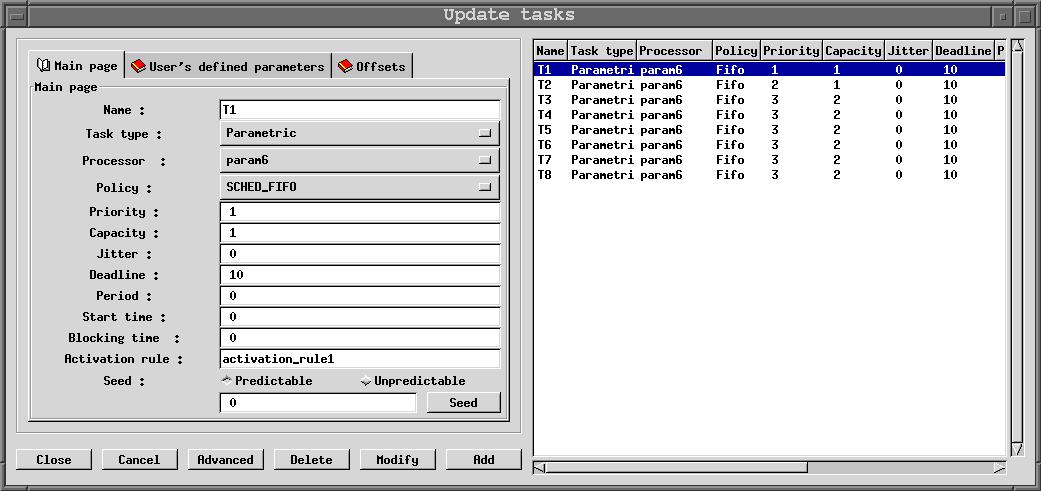
This window is composed of 3 sub-windows : the "main page", the "offset page"
and the "user's defined parameters page". The main page contains the following
information :
Finally, the third page (the "User's defined parameters" page) contains task parameters (similar to the deadline, the period, the capacity ...) used by user-defined schedulers. With this page, a user can define new task parameters. A user-defined task parameter has a value, a name and a type. The types currently available to defined user-defined task parameters are : string, integer boolean and double.
Warning : when you create tasks, in most of cases, Cheddar does not check if your task parameters are erronous according to the scheduler you previously selected : these checks are done at task analysis/scheduling. Of course, you can always change task and processor parameters with "Edit/Update and "Edit/Duplicate" menus.
When tasks and processors are defined, we can start the task
analysis. Cheddar provides two kind of analysis tools :
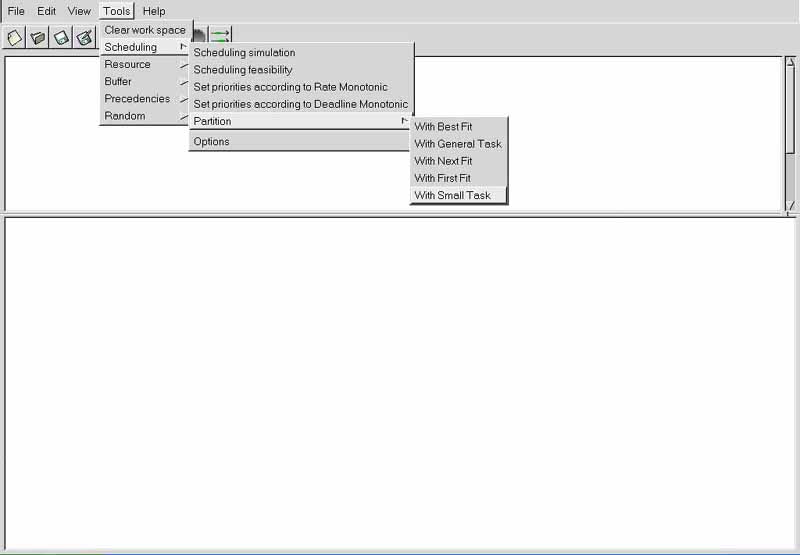
All these tools can be called from the "Tools"
Menu and from some toolbar Buttons :
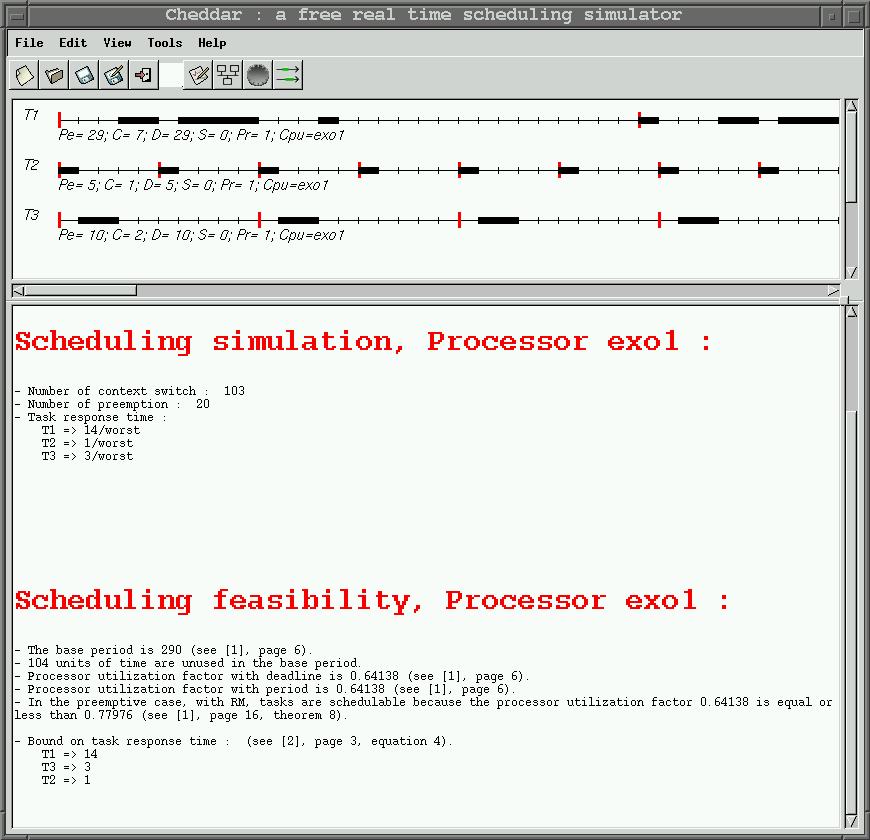
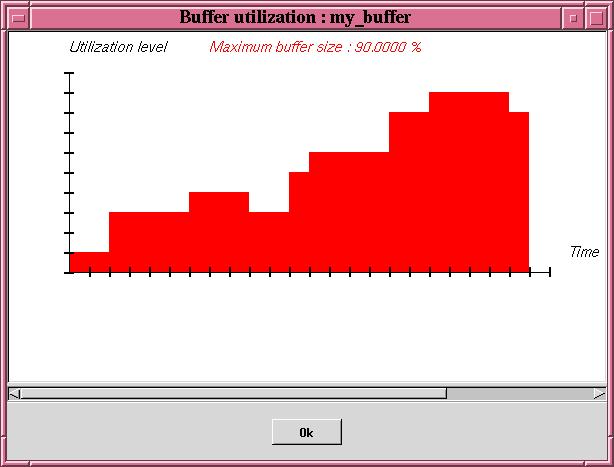
In the top part of this window, each resource, buffer, message and task is shown by a
time line :
The scheduling result can also be saved in XML file. This is particulary
usefull if you do not want to use the Cheddar Machine-Man-Interface.
For example, the computed scheduling as an event table. The event table
is the data structur used by the simulator engine to perform analysis on scheduling.
The event produced by the simulator are :
Start_Of_Task_Capacity,
End_Of_Task_Capacity,
Write_To_Buffer,
Read_From_Buffer,
Running_Task,
Task_Activation,
Send_Message,
Receive_Message,
Allocate_Resource,
Release_Resource and
Wait_For_Resource.
In a XML event table file, an event
Each event is exported with the time the event occurs. For each event, some extra data related to the event can also be exported :
To get a summary of the tools provided by Cheddar, see
section VI .
In the same way, Cheddar provides a set of built-in task arrival patterns. The built-in task arrival patterns are :
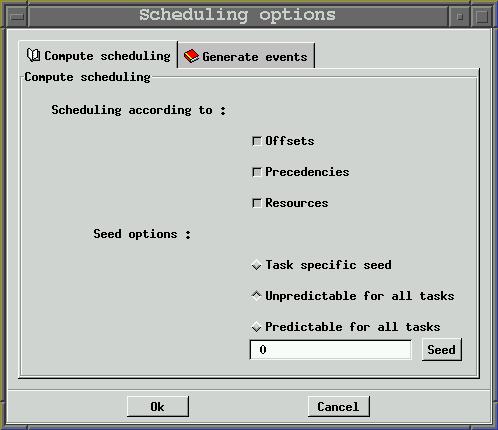
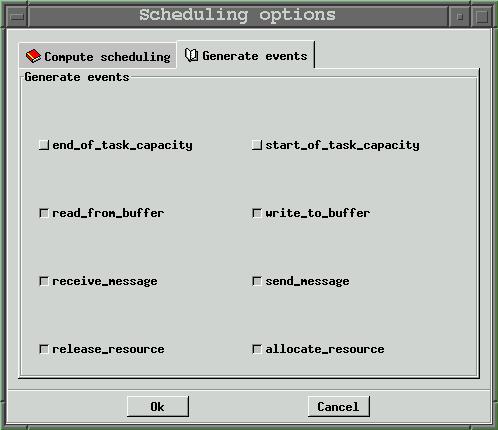
Options related to which information the engine has to compute when the scheduling sequence is built are :
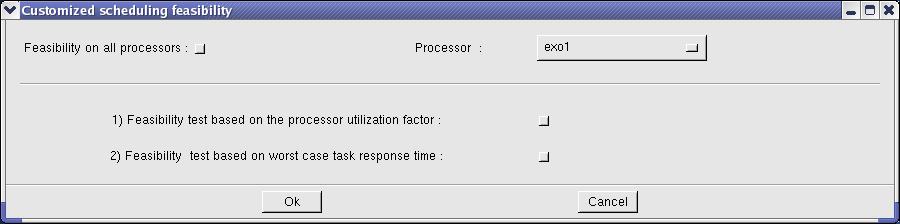
Options related to which information the feasibility tests will compute are :
Information stored during a simulation can be saved into project
files. A project file is a XML file defined by this DTD. By the way, you do not need
a deep understanding of the layout of cheddar project files except if
you want to edit project files by hand. If so, you should check if your
project files are correctly structured by the tool xml2xml (xml2xml
just reads, parses and displays the content of a XML Cheddar
project file on the screen ).
All Cheddar XML files can be displayed with an Internet Browser if you
put the following XSLT file and the following.CSS file in the directory hosting your XML Cheddar files.
To do so, you should use a recent
release of Internet Explorer (version 6.0 or later), Netscape (version
7.0 or later) or Mozilla (version 1.0 or later).
From Cheddar, there are two ways to load a project file :
my_shell$cheddar my_project.xml
Saving a project can be done with the same "File"
menu.
Cheddar can also import AADL specification [SAE 04]. This service can be accessed through the submenu "File/AADL/Import AADL". In the same way, an XML project can be exported towards an AADL specification (see the "File/AADL/Export AADL" sub-menu). As with XML files, you can launch Cheddar with an AADL file given from the command line. To launch Cheddar and automatically read the foo.aadl AADL specification file, do :
my_shell$cheddar -a foo.aadl
Finally, XML or AADL files can be loaded from any directory and a project can be saved in several project files. For example, to load a project saved in two AADL files called bar1.aadl and bar2.aadl, which are stored in the directory /home/foo, you must use the following command-line :
my_shell$cheddar -I/home/foo -a bar1.aadl bar2.aadl
my_shell$cheddar [switches] foo1 foo2 ...
where foo1 foo2 can be an unique XML file
or one or several AADL files.
Switches can be :
This chapter describes services provided by Cheddar when the system you want to study has task dependencies. By task dependencies, we mean resources shared by several tasks (ex : semaphores) or precedency relationships between several tasks (due to buffer access or message exchange or also constraints between the end of a task and the start of another one).
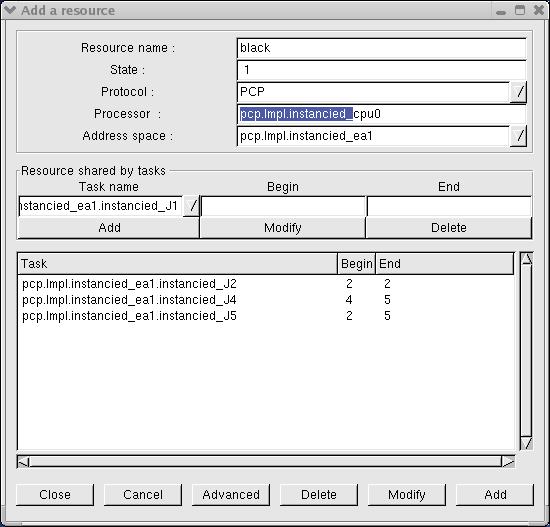
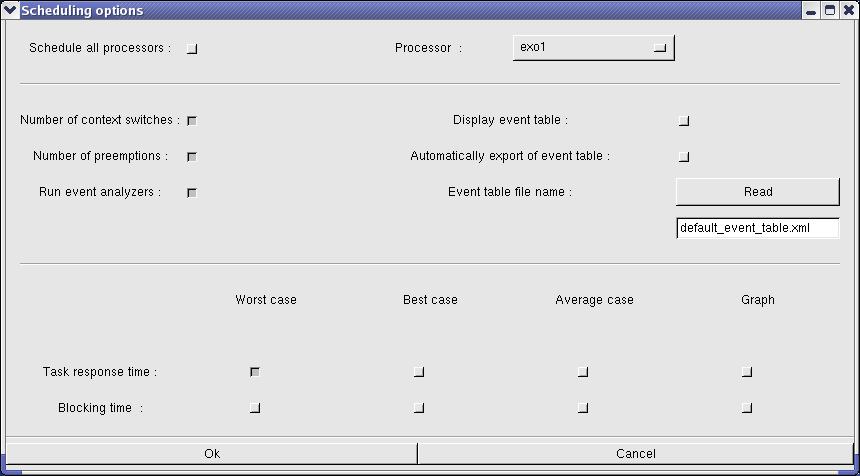
By default, shared resources analysis tools are not included in the scheduling simulation engine of Cheddar. See "Tools/Scheduling/Options" if you want to take care of shared resources during scheduling simulation and if you want to display shared resources time line. Blocking time on shared resources can be computed from scheduling simulation analysis if scheduling simulation is invoked from the sub-menu "Tools/Scheduling/Scheduling Simulation".
Finally, from the "Tools/Resources/Blocking time" sub-menu, you will find services to compute bounds on blocking time of each tasks. These bounds are computed without assumption on the scheduling actually generated for the analyzed system. To compute blocking time bound, shared resources have to used PCP or PIP protocols.
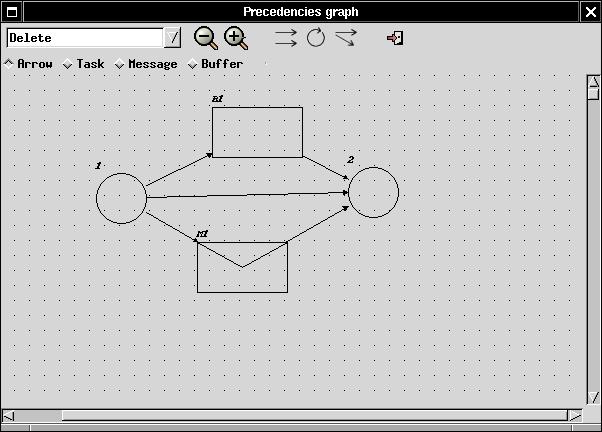
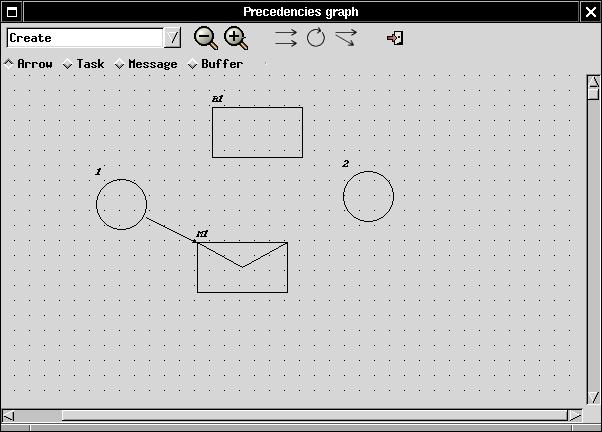
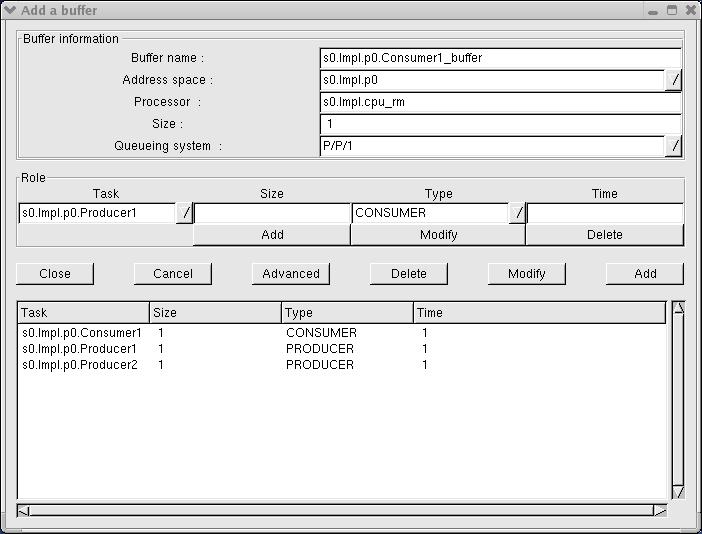
To create a dependency, you may open the "Precedencies Graph" window by clicking on the appropriate icon on the main Cheddar window. By the way, all Cheddar objects are imported in this window. All items are represented by geometrical forms :
If there is no item on the canvas, it means that you have not created any dependency before... So you can create one by entering in "Create" mode (on the top left corner) and selecting "Task" on the radio button. After that, create a task by clicking on the canvas, then a popup appears asking you to create a new or import one task from Cheddar (cf section I). It's the same succession of operations to create other types of items (buffers and messages).
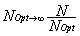 .
.
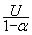 , a = max Ui, i = 1,…,K and U is
utilization of all tasks. Tasks are sorted in increasing Si. Si =
log2(Ti). The main idea of RMST is to minimize the value of
b for each processor. ß = max Si – min Si, 1= i =K.
, a = max Ui, i = 1,…,K and U is
utilization of all tasks. Tasks are sorted in increasing Si. Si =
log2(Ti). The main idea of RMST is to minimize the value of
b for each processor. ß = max Si – min Si, 1= i =K.
Now, let's see how user-defined schedulers
or task activation patterns can
be added into the framework.
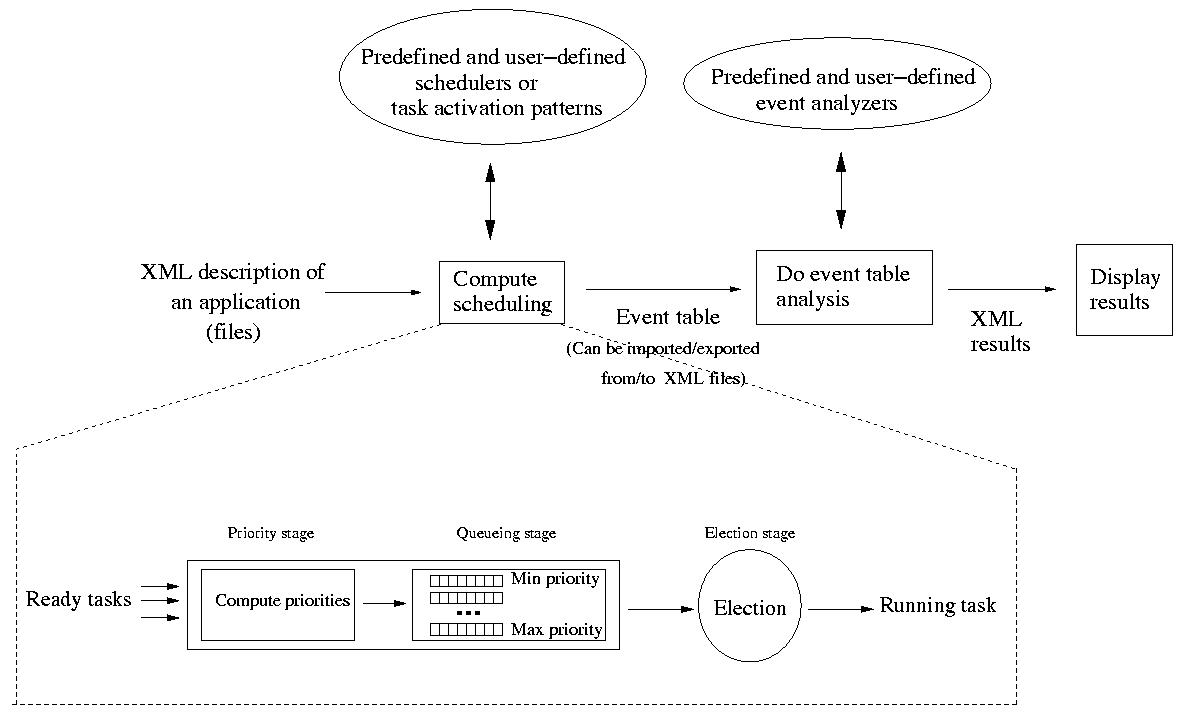
Basically, all tasks are stored in a set of arrays.
Each array stores a given information for all tasks (ex : deadline, capacity,
start time, ...).
The job of a scheduler is to find a task
to run from a set of ready tasks. To achieve this job, Cheddar models a
scheduler with a 3 stages pipe-line which is similar to the POSIX 1003.1b scheduler (see [GAL 95]). These 3 stages are
:
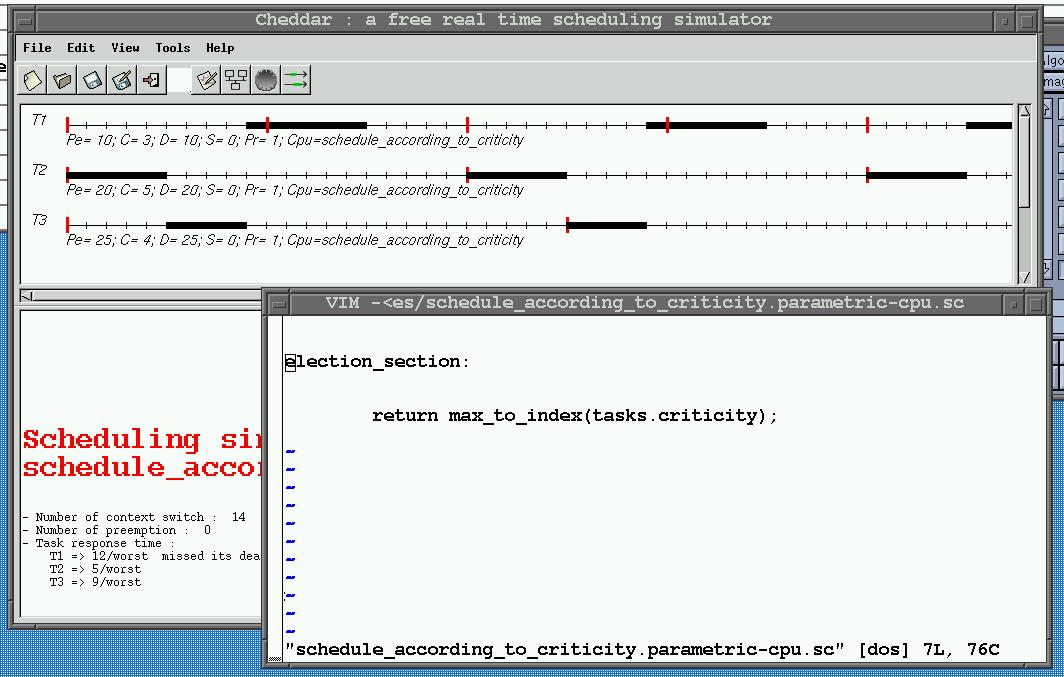
election_section:
return min_to_index(tasks.period);
end section;
|
1 start_section: 2 dynamic_priority : array (tasks_range) of integer; 3 end section; 4 5 priority_section: 6 dynamic_priority := tasks.start_time + tasks.deadline 7 + ((tasks.activation_number-1)*tasks.period); 8 end section; 9 10 election_section: 11 return min_to_index(dynamic_priority); 12 end section; |
start_section:
to_run : integer;
current_priority : integer;
priority_section:
current_priority:=0;
for i in tasks_range loop
if (tasks.ready(i) = true) and (tasks.priority(i)>current_priority)
then to_run:=i;
current_priority:=tasks.priority(i);
end if;
end loop;
end section;
election_section:
return to_run;
end section;
|
election_section: return max_to_index(tasks.priority); end section; |
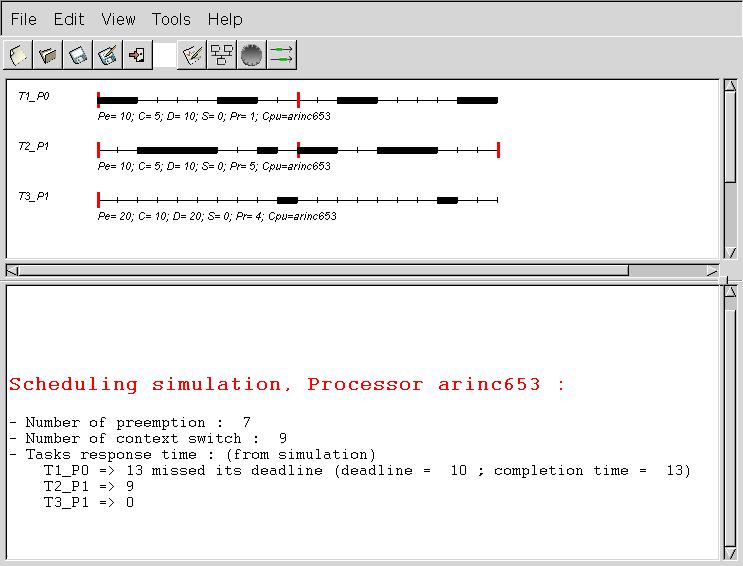
start_section: partition_duration : array (tasks_range) of integer; dynamic_priority : array (tasks_range) of integer; number_of_partition : integer :=2; current_partition : integer :=0; time_partition : integer :=0; i : integer; partition_duration(0):=2; partition_duration(1):=4; time_partition:=partition_duration(current_partition); end section; priority_section: if time_partition=0 then current_partition:=(current_partition+1) mod number_of_partition; time_partition:=partition_duration(current_partition); end if; for i in tasks_range loop if tasks.task_partition(i)=current_partition then dynamic_priority(i]:=priority(i); else dynamic_priority(i):=0; tasks.ready(i):=false; end if; end loop; time_partition:=time_partition-1; end section; election_section: return max_to_index(dynamic_priority); end section; |
start_section:
gen1 : random;
gen2 : random;
exponential(gen1, 200);
uniform(gen2, 0, 100);
end section;
election_section:
return max_to_index(tasks.priority);
end section;
task_activation_section:
set activation_rule1 10;
set activation_rule2 2*tasks.capacity;
set activation_rule3 gen1*20;
set activation_rule4 gen2;
end section;
|
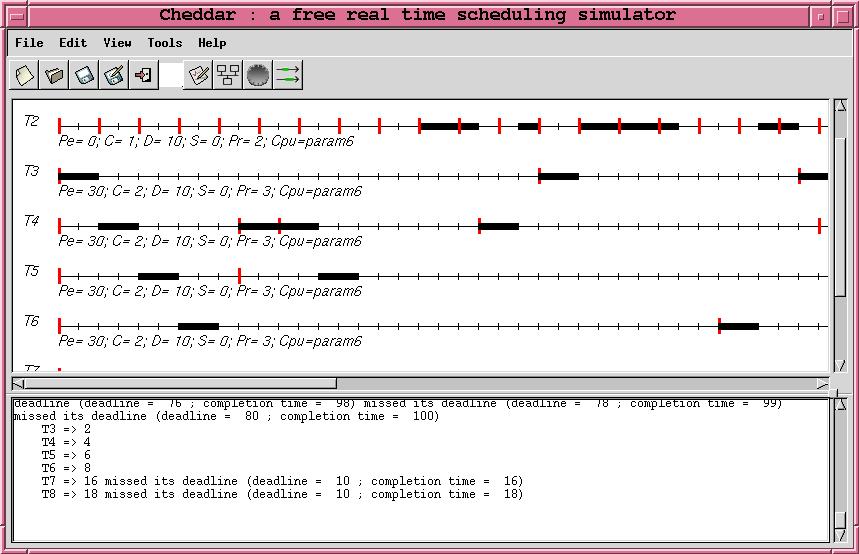
--!TRACE |
start_section:
i : integer;
nb_T2 : integer;
nb_T1 : integer;
bound_on_jitter : integer;
max_delay : integer;
min_delay : integer;
tmp : integer;
T1_end_time : array (time_units_range) of integer;
T2_end_time : array (time_units_range) of integer;
min_delay:=integer'last;
max_delay:=integer'first;
i:=0;
nb_T1:=0; nb_T2:=0;
end section;
gather_event_analyzer_section:
if (events.type = "end_of_task_capacity")
then
if (events.task_name = "T1")
then
T1_end_time(nb_T1):=events.time;
nb_T1:=nb_T1+1;
end if;
if (events.task_name = "T2")
then
T2_end_time(nb_T2):=events.time;
nb_T2:=nb_T2+1;
end if;
end if;
end section;
display_event_analyzer_section:
while (i < nb_T1) and (i < nb_T2) loop
tmp:=abs(T1_end_time(i)-T2_end_time(i));
min_delay:=min(tmp, min_delay);
max_delay:=max(tmp, max_delay);
i:=i+1;
end loop;
bound_on_jitter:=abs(max_delay-min_delay);
put(min_delay);
put(max_delay);
put(bound_on_jitter);
end section;
|
| Name | Type | Is updated by the simulator engine | Can be changed by user code | Meaning |
| Variables related to processors | ||||
| nb_processors |
integer |
no |
no |
Gives the number of processors of the current analyzed system. |
| Variables related to tasks | ||||
| tasks.period |
array (tasks_range) of integer |
yes | yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.name |
array (tasks_range) of string |
no |
no |
Name of the task |
| tasks.type |
array (tasks_range) of string |
no |
no |
Type of the task (periodic, aperiodic, sporadic, poisson_process or userd_defined) |
| tasks.processor_name |
array (tasks_range) of string |
no |
no |
Stores the processor name of the cpu hosting the corresponding task. |
| tasks.blocking_time |
array (tasks_range) of integer |
no |
yes |
Stores the sum of the bounded times the task has to wait on shared resource accesses. |
| tasks.deadline |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.capacity |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.start_time |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.used_cpu |
array (tasks_range) of integer |
yes |
no |
Stores the amount of processor time
wasted by the associated task. |
| tasks.activation_number |
array (tasks_range) of integer |
yes |
no |
Stores the activation number of the associated task.
Of course, using this variable is meaningless for aperiodic tasks. |
| tasks.jitter |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.priority |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.used_capacity |
array (tasks_range) of integer |
yes |
no |
This variable stores the umount of time unit the task had consumed since its
last activation. When tasks.used_capacity reaches tasks.capacity, the task stops
to run and waits its next activation |
| tasks.rest_of_capacity |
array (tasks_range) of integer |
yes |
no |
For each task activation, this variable
is initialized to the task capacity each time the task starts a new activation. If rest_of_capacity
is equal to zero, the task has over its its current activation and then task is blocked upto its next activation. |
| tasks.suspended |
array (tasks_range) of integer |
yes |
yes |
This variable can be used by scheduler programmers to block a task : remove a task from schedulable tasks. |
| nb_tasks |
integer |
no |
no |
Gives the number of tasks of the current
analyzed system. |
| tasks.ready |
array (tasks_range) of boolean |
yes |
no |
Stores the state of the task : this
boolean is true if the task is ready ; it means the task has a capacity
to run, does not wait for a shared resource, does not wait for a delay,
does not wait for a offset constraint and does not wait for a precedency
constraint. |
| Variables related to messages | ||||
| nb_messages |
integer |
no |
no |
Gives the number of messages of the current analyzed system. |
| messages.name |
array (messages_range) of string |
no |
no |
Gives the names of each message. |
| messages.jitter |
array (messages_range) of integer |
no |
no |
Jitter on the time the periodic message becomes ready to be sent. |
| messages.period |
array (messages_range) of integer |
no |
no |
Gives the sending period if the message is a periodic one. |
| messages.delay |
array (messages_range) of integer |
no |
no |
time needed by a message to go from the sendrer to the receiver node. |
| messages.deadline |
array (messages_range) of integer |
no |
no |
Stores the deadline if the message has to meet one. |
| messages.size |
array (messages_range) of integer |
no |
no |
Stores the size of the message. |
| messages.users.time |
array (messages_range) of integer |
no |
no |
Stores the time when the task should send or receive the message. |
| messages.users.task_name |
array (messages_range) of string |
no |
no |
Stores the task name that sends/receives the message. |
| messages.users.type |
array (messages_range) of string |
no |
no |
Stores sender if the corresponding task sends the message or stores receiver if the task receives it. |
| Variables related to buffers | ||||
| nb_buffers |
integer |
no |
no |
Gives the number of buffers of the current analyzed system. |
| buffers.max_size |
array (buffers_range) of integer |
no |
no |
The maximum size of a given buffer. |
| buffers.processor_name |
array (buffers_range) of string |
no |
no |
Gives the processor name that owns the buffer. |
| buffers.name |
array (buffers_range) of string |
no |
no |
Unique name of the buffer. |
| buffers.users.time |
array (buffers_range) of integer |
no |
no |
Stores the time a given task consumes/produces a message from/into a buffer. |
| buffers.users.size |
array (buffers_range) of integer |
no |
no |
Stores the size of the message produced/consumed into/from a buffer by a given task. |
| buffers.users.task_name |
array (buffers_range) of string |
no |
no |
Stores the task name that procudes/consumes messages into/from a given buffer. |
| buffers.users.type |
array (buffers_range) of string |
no |
no |
Stores consumer if the corresponding task consumes messages from the buffer or stores producer if the task produces messages. |
| Variables related to shared resources | ||||
| nb_resources |
integer |
no |
no |
Gives the number of shared resources of the current analyzed system. |
| resources.initial_state |
array (resources_range) of integer |
no |
no |
Stores the state of the resource when the simulation is started. If this integer is equal of less than zero, the first allocation request will block the requesting task. |
| resources.current_state |
array (resources_range) of integer |
no |
no |
Stores the current state of the resource.
If this integer is equal of less than zero, the first allocation request will block the requesting task. After an allocation of the resource, this counter is
decremented. After the task has released the resource, this counter is incremented. |
| resources.processor_name |
array (resources_range) of string |
no |
no |
Stores the name of the processors hosting the shared resource. |
| resources.protocol |
array (resources_range) of string |
no |
no |
Contains the protocol name used to manage the resource allocation request. Could be either no_protocol, priority_ceiling_protocol or priority_inheritance_protocol |
| resources.name |
array (resources_range) of integer |
no |
no |
Unique name of the shared resource |
| resources.users.task_name |
array (resources_range) of string |
no |
no |
Gives the name of a task that can access the shared resource. |
| resources.users.start_time |
array (resources_range) of integer |
no |
no |
Gives the time the task starts accessing the shared resource during its capacity. |
| resources.users.end_time |
array (resources_range) of integer |
no |
no |
Gives the time the task ends accessing the shared resource during its capacity. |
| Variables related to the scheduling simulation | ||||
| previously_elected |
integer |
yes |
no |
At the time the user-defined scheduler
runs, this variable stores the TCB index of the task elected at the previous simulation time |
| simulation_time |
integer |
yes |
no |
Stores the current simulation time . |
| Variables related to the event table | ||||
| events.type |
string |
no |
no |
Type of event on the current index table. Can be task_activation, running_task, write_to_buffer, read_from_buffer, send_message, receive_message, start_of_task_capacity, end_of_task_capacity, allocate_resource, release_resource, wait_for_resource. |
| events.time |
integer |
no |
no |
The time when the event occurs. |
| events.processor_name |
string |
no |
no |
The processor name hosting the task/resource/buffer related to the current event. |
| events.task_name |
string |
no |
no |
The task name related to the current event. |
| events.message_name |
string |
no |
no |
The message name related to the current event. |
| events.buffer_name |
string |
no |
no |
The buffer name related to the current event. |
| events.resource_name |
string |
no |
no |
The resource name related to the current event. |
| entry := start_rule priority_rule election_rule
task_activation_rule gather_event_analyzer display_event_analyzer declare_rule := "start_section:" statements priority_rule := "priority_section:" statements election_rule := "election_section:" statements task_activation_rule := "task_activation_section" statements gather_event_analyzer := "gather_event_analyzer_section" statements display_event_analyzer:= "display_event_analyzer_section" statements statements := statement {statement} statement := "put" "(" identifier [, integer] [, integer]")" ";" | identifier ":" data_type [ ":=" expression ] ";" | identifier ":=" expression ";" | "if" expression "then" statements [ "else" statements ] "end" "if" ";" | "return" expr ";" | "for" identifier "in" ranges "loop" statements "end" "loop" ";" | "while" expression "loop" statements "end" "loop" ";" | "set" identifier expression ";" | "uniform" "(" identifier "," expression "," expression ")" ";" | "exponential" "(" identifier "," expression ")" ";" data_type := scalar_data_type | "array" "(" ranges ")" "of" scalar_data_type ranges := "tasks_range" | "buffers_range" | "messages_range" | "resources_range" | "processors_range" | "time_units_range" scalar_data_type := "double" | "integer" | "boolean" | "string" | "random" operator := "and" | "or" | "mod" | "<" | ">" | "<=" | ">=" | "/=" | "=" | "+" | "/" | "-" | "*" | "**" expression := expression operator expression | "(" expression ")" | "not" expression | "-" expression | "max_to_index" "(" expression ")" | "min_to_index" "(" expression ")" | "max" "(" expression "," expression ")" | "min" "(" expression "," expression ")" | "lcm" "(" expression "," expression ")" | "abs" "(" expression ")" | identifier "[" expression "]" | identifier | integer_value | double_value | boolean_value |
All Cheddar analysis tools are called from the "Tools"
menu. This section gives a short description of them. Some
of them compute
tasks parameters, and then are composed of two submenus
: "Compute and update tasks set"
and "Compute and display".
Menus and Sub-menus of the Cheddar's editor :