
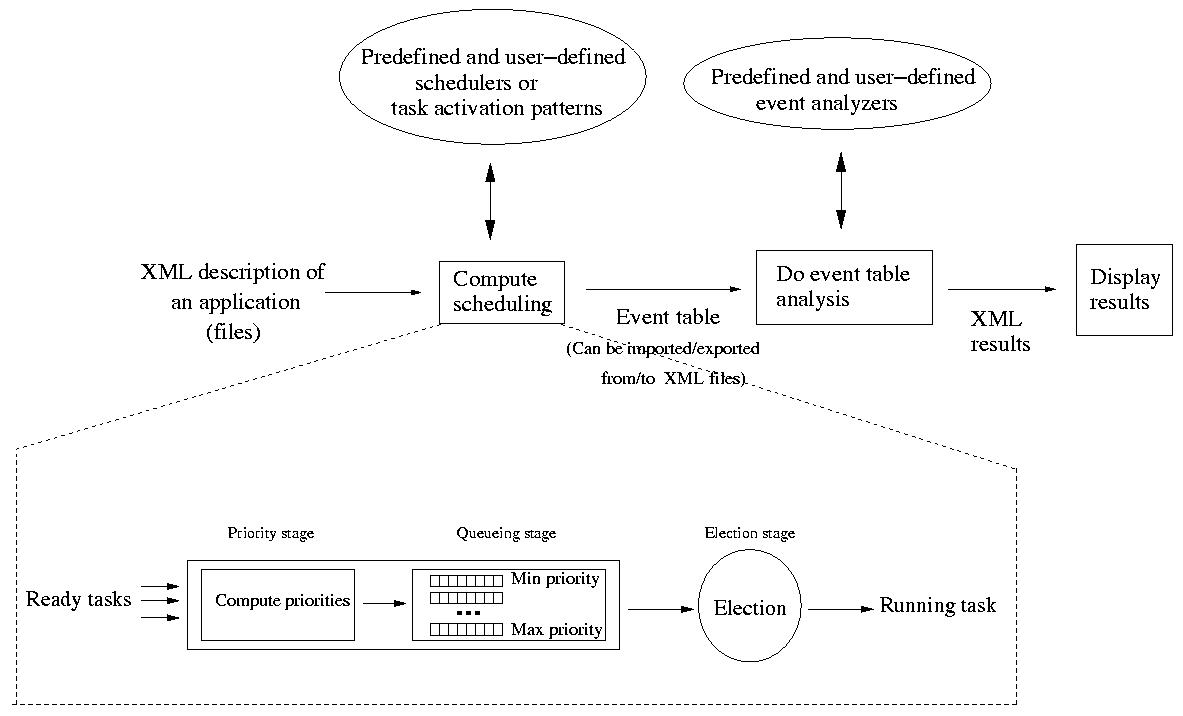
Now, let's see how user-defined schedulers
or task activation patterns can
be added into the framework.
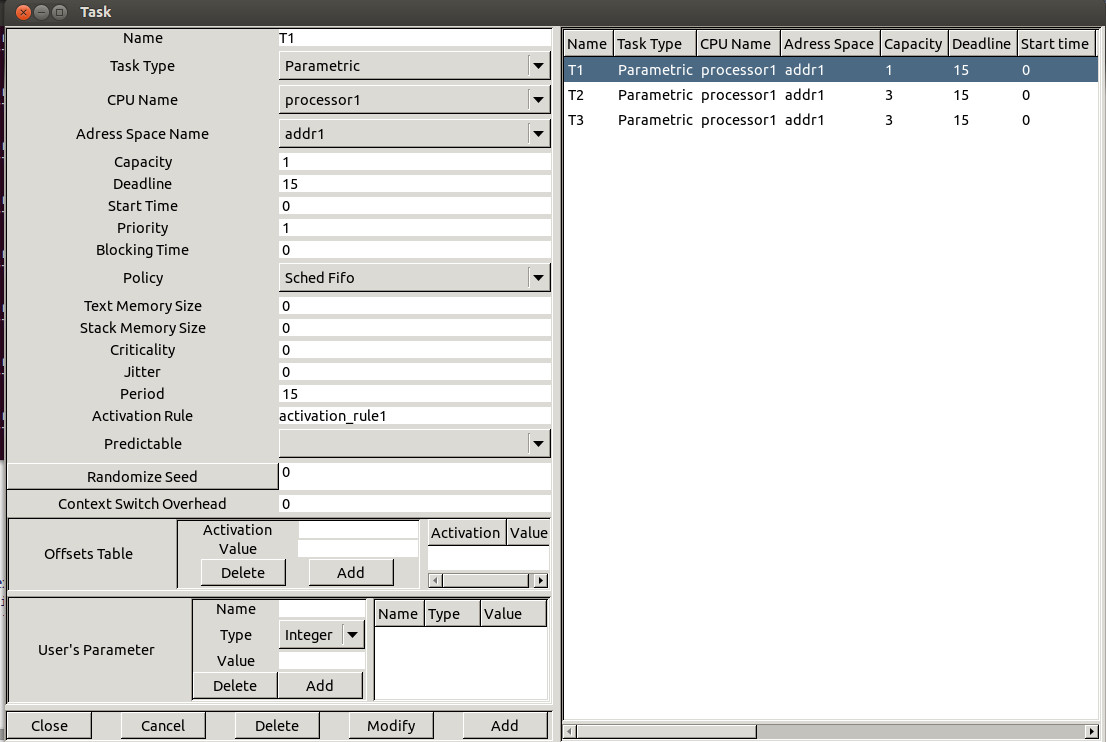
Basically, all tasks are stored in a set of arrays.
Each array stores a given information for all tasks (ex : deadline, capacity,
start time, ...).
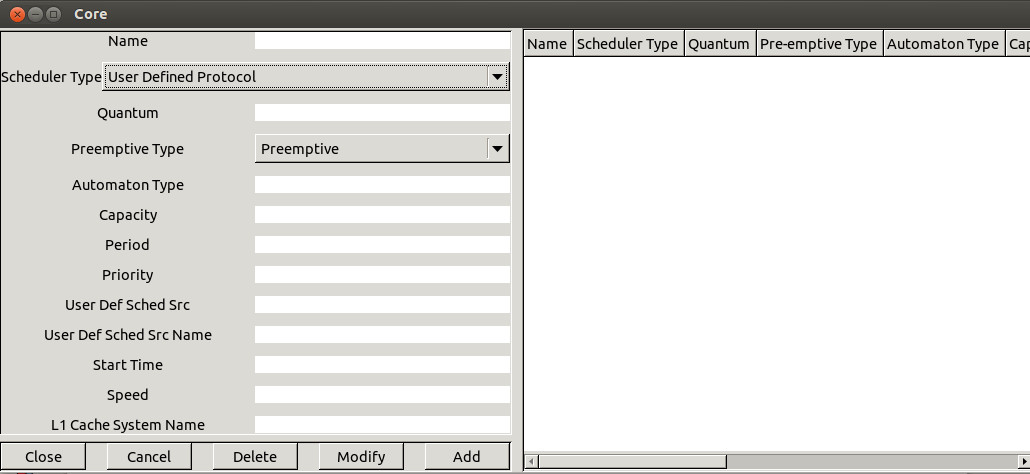
The job of a scheduler is to find a task
to run from a set of ready tasks. To achieve this job, Cheddar models a
scheduler with a 3 stages pipe-line which is similar to the POSIX 1003.1b scheduler (see [GAL 95]). These 3 stages are
:
election_section: |
1 start_section: |
start_section: |
election_section: |
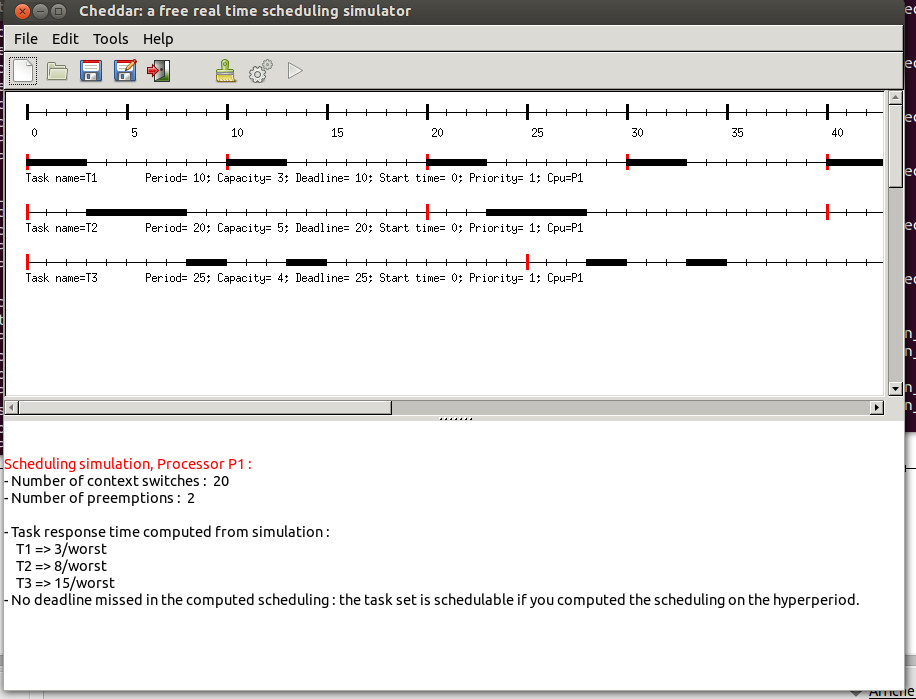
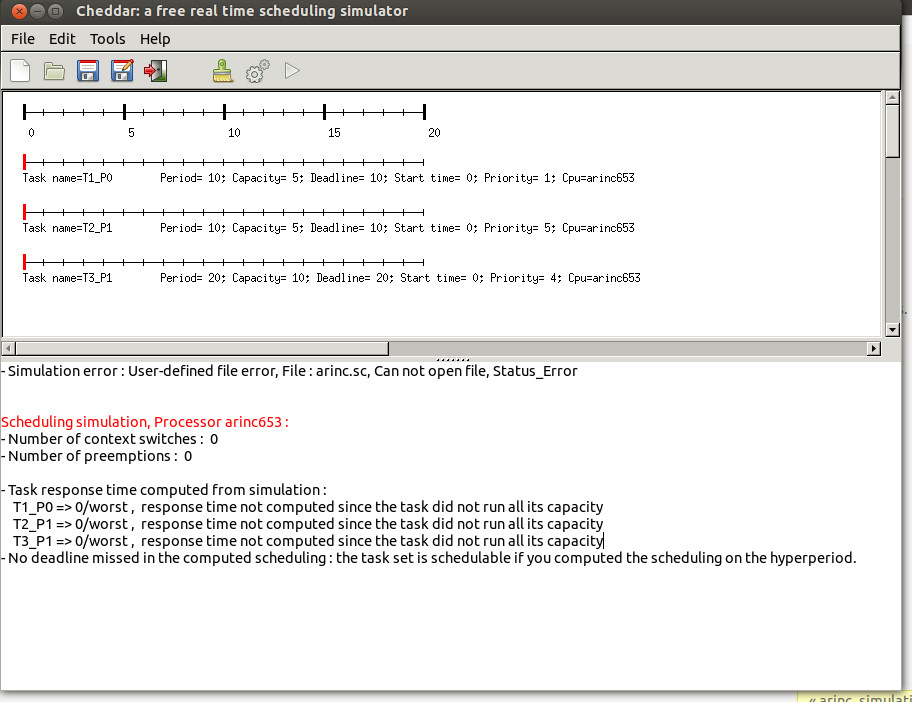
start_section: |
start_section: |
--!TRACE |
start_section: |
| Name | Type | Is updated by the simulator engine | Can be changed by user code | Meaning |
| Variables related to processors | ||||
| nb_processors |
integer |
no |
no |
Gives the number of processors of the current analyzed system. |
| processors.speed |
integer |
yes |
yes |
Gives the speed of the processor hosting the scheduler. |
| Variables related to tasks | ||||
| tasks.period |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.name |
array (tasks_range) of string |
no |
no |
Name of the task |
| tasks.type |
array (tasks_range) of string |
no |
no |
Type of the task (periodic, aperiodic, sporadic, poisson_process or userd_defined) |
| tasks.processor_name |
array (tasks_range) of string |
no |
no |
Stores the processor name of the cpu hosting the corresponding task. |
| tasks.blocking_time |
array (tasks_range) of integer |
no |
yes |
Stores the sum of the bounded times the task has to wait on shared resource accesses. |
| tasks.deadline |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.capacity |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.start_time |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.used_cpu |
array (tasks_range) of integer |
yes |
no |
Stores the amount of processor time
wasted by the associated task. |
| tasks.activation_number |
array (tasks_range) of integer |
yes |
no |
Stores the activation number of the associated task.
Of course, using this variable is meaningless for aperiodic tasks. |
| tasks.jitter |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.priority |
array (tasks_range) of integer |
yes |
yes |
Stores the value of the parameter given
at task definition time. For the meaning of this variable, see section
I. |
| tasks.used_capacity |
array (tasks_range) of integer |
yes |
no |
This variable stores the umount of time unit the task had consumed since its
last activation. When tasks.used_capacity reaches tasks.capacity, the task stops
to run and waits its next activation |
| tasks.rest_of_capacity |
array (tasks_range) of integer |
yes |
no |
For each task activation, this variable
is initialized to the task capacity each time the task starts a new activation. If rest_of_capacity
is equal to zero, the task has over its its current activation and then task is blocked upto its next activation. |
| tasks.suspended |
array (tasks_range) of integer |
yes |
yes |
This variable can be used by scheduler programmers to block a task : remove a task from schedulable tasks. |
| nb_tasks |
integer |
no |
no |
Gives the number of tasks of the current
analyzed system. |
| tasks.ready |
array (tasks_range) of boolean |
yes |
no |
Stores the state of the task : this
boolean is true if the task is ready ; it means the task has a capacity
to run, does not wait for a shared resource, does not wait for a delay,
does not wait for a offset constraint and does not wait for a precedency
constraint. |
| Variables related to messages | ||||
| nb_messages |
integer |
no |
no |
Gives the number of messages of the current analyzed system. |
| messages.name |
array (messages_range) of string |
no |
no |
Gives the names of each message. |
| messages.jitter |
array (messages_range) of integer |
no |
no |
Jitter on the time the periodic message becomes ready to be sent. |
| messages.period |
array (messages_range) of integer |
no |
no |
Gives the sending period if the message is a periodic one. |
| messages.delay |
array (messages_range) of integer |
no |
no |
time needed by a message to go from the sendrer to the receiver node. |
| messages.deadline |
array (messages_range) of integer |
no |
no |
Stores the deadline if the message has to meet one. |
| messages.size |
array (messages_range) of integer |
no |
no |
Stores the size of the message. |
| messages.users.time |
array (messages_range) of integer |
no |
no |
Stores the time when the task should send or receive the message. |
| messages.users.task_name |
array (messages_range) of string |
no |
no |
Stores the task name that sends/receives the message. |
| messages.users.type |
array (messages_range) of string |
no |
no |
Stores sender if the corresponding task sends the message or stores receiver if the task receives it. |
| Variables related to buffers | ||||
| nb_buffers |
integer |
no |
no |
Gives the number of buffers of the current analyzed system. |
| buffers.max_size |
array (buffers_range) of integer |
no |
no |
The maximum size of a given buffer. |
| buffers.processor_name |
array (buffers_range) of string |
no |
no |
Gives the processor name that owns the buffer. |
| buffers.name |
array (buffers_range) of string |
no |
no |
Unique name of the buffer. |
| buffers.users.time |
array (buffers_range) of integer |
no |
no |
Stores the time a given task consumes/produces a message from/into a buffer. |
| buffers.users.size |
array (buffers_range) of integer |
no |
no |
Stores the size of the message produced/consumed into/from a buffer by a given task. |
| buffers.users.task_name |
array (buffers_range) of string |
no |
no |
Stores the task name that procudes/consumes messages into/from a given buffer. |
| buffers.users.type |
array (buffers_range) of string |
no |
no |
Stores consumer if the corresponding task consumes messages from the buffer or stores producer if the task produces messages. |
| Variables related to shared resources | ||||
| nb_resources |
integer |
no |
no |
Gives the number of shared resources of the current analyzed system. |
| resources.initial_state |
array (resources_range) of integer |
no |
no |
Stores
the state of the resource when the simulation is started. If this
integer is equal of less than zero, the first allocation request will
block the requesting task. |
| resources.current_state |
array (resources_range) of integer |
no |
no |
Stores
the current state of the resource.
If this integer is equal of less than zero, the first allocation
request will block the requesting task. After an allocation of the
resource, this counter is
decremented. After the task has released the resource, this counter is
incremented. |
| resources.processor_name |
array (resources_range) of string |
no |
no |
Stores the name of the processors hosting the shared resource. |
| resources.protocol |
array (resources_range) of string |
no |
no |
Contains
the protocol name used to manage the resource allocation request. Could
be either no_protocol, priority_ceiling_protocol or
priority_inheritance_protocol |
| resources.name |
array (resources_range) of integer |
no |
no |
Unique name of the shared resource |
| resources.users.task_name |
array (resources_range) of string |
no |
no |
Gives the name of a task that can access the shared resource. |
| resources.users.start_time |
array (resources_range) of integer |
no |
no |
Gives the time the task starts accessing the shared resource during its capacity. |
| resources.users.end_time |
array (resources_range) of integer |
no |
no |
Gives the time the task ends accessing the shared resource during its capacity. |
| Variables related to the scheduling simulation | ||||
| previously_elected |
integer |
yes |
no |
At the time the user-defined scheduler
runs, this variable stores the TCB index of the task elected at the previous simulation time |
| simulation_time |
integer |
yes |
no |
Stores the current simulation time . |
| Variables related to the event table | ||||
| events.type |
string |
no |
no |
Type of event on the current index table. Can be task_activation, running_task, write_to_buffer, read_from_buffer, send_message, receive_message, start_of_task_capacity, end_of_task_capacity, allocate_resource, release_resource, wait_for_resource. |
| events.time |
integer |
no |
no |
The time when the event occurs. |
| events.processor_name |
string |
no |
no |
The processor name hosting the task/resource/buffer related to the current event. |
| events.task_name |
string |
no |
no |
The task name related to the current event. |
| events.message_name |
string |
no |
no |
The message name related to the current event. |
| events.buffer_name |
string |
no |
no |
The buffer name related to the current event. |
| events.resource_name |
string |
no |
no |
The resource name related to the current event. |
| entry := start_rule priority_rule election_rule
task_activation_rule gather_event_analyzer display_event_analyzer declare_rule := "start_section:" statements priority_rule := "priority_section:" statements election_rule := "election_section:" statements task_activation_rule := "task_activation_section" statements gather_event_analyzer := "gather_event_analyzer_section" statements display_event_analyzer:= "display_event_analyzer_section" statements statements := statement {statement} statement := "put" "(" identifier [, integer] [, integer]")" ";" | identifier ":" data_type [ ":=" expression ] ";" | identifier ":=" expression ";" | "if" expression "then" statements [ "else" statements ] "end" "if" ";" | "return" expr ";" | "for" identifier "in" ranges "loop" statements "end" "loop" ";" | "while" expression "loop" statements "end" "loop" ";" | "set" identifier expression ";" | "uniform" "(" identifier "," expression "," expression ")" ";" | "exponential" "(" identifier "," expression ")" ";" data_type := scalar_data_type | "array" "(" ranges ")" "of" scalar_data_type ranges := "tasks_range" | "buffers_range" | "messages_range" | "resources_range" | "processors_range" | "time_units_range" scalar_data_type := "double" | "integer" | "boolean" | "string" | "random" operator := "and" | "or" | "mod" | "<" | ">" | "<=" | ">=" | "/=" | "=" | "+" | "/" | "-" | "*" | "**" expression := expression operator expression | "(" expression ")" | "not" expression | "-" expression | "max_to_index" "(" expression ")" | "min_to_index" "(" expression ")" | "max" "(" expression "," expression ")" | "min" "(" expression "," expression ")" | "lcm" "(" expression "," expression ")" | "abs" "(" expression ")" | identifier "[" expression "]" | identifier | integer_value | double_value | boolean_value |