~/bin
- Les autres distributions de Cheddar sont également disponibles en téléchargement ici
./cheddar
~/bin
./cheddar
Dans cette partie, vous allez construire votre premier modèle Cheddar en suivant les consignes ci-dessous.
Pour effectuer une analyse d'ordonnancement, il est dans un premier temps nécessaire de décrire le système à analyser avec Cheddar ADL. Cheddar ADL est un langage d'architecture simplifié et dédié à l'analyse d'ordonnancement. Il comporte une description de la partie matérielle et de la partie logicielle du système à analyser. Ces modèles peuvent être rédigés avec n'importe quel éditeur de texte, toutefois, par la suite, nos modèles seront élaborés avec l'éditeur interne de Cheddar de la façon suivante :
processor incluant un ou plusieurs
composants core et éventuellement des composants cache.
Un core est ici une unité de calcul, i.e. une entité qui offre des moyens
pour exécuter une ou plusieurs tâches.
core, utilisez le menu Edit/Hardware/Core
qui permet d'ouvrir la fenêtre de la figure 2 :
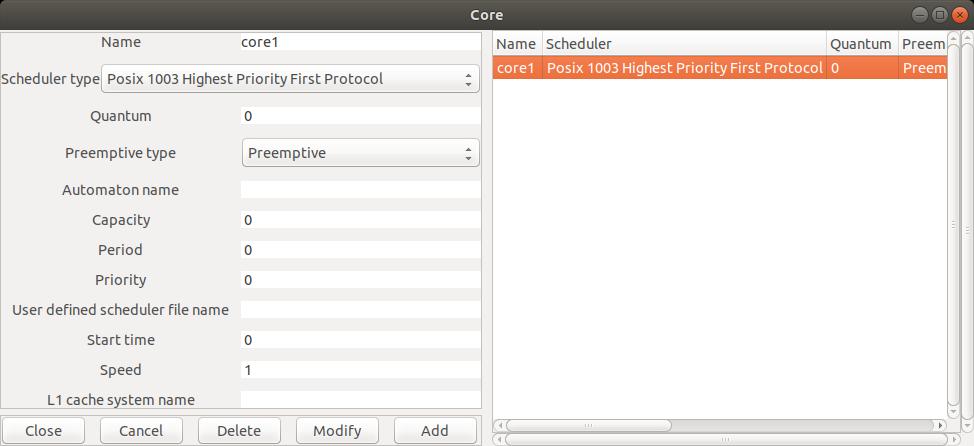
core est défini par les attributs suivants:
Name : le nom unique du composant, ici, core1. Scheduler type : la méthode d'ordonnancement qui sera appliquée par le composant.
Dans la fenêtre ci-dessus, nous avons défini un
core hébergeant un ordonnanceur à priorité fixe conforme au standard POSIX 1003
(valeur POSIX_1003_Highest_Priority_First_Protocol pour l'attribut
Scheduler type).
Dans Cheddar, avec cet ordonnanceur, les priorités fixes peuvent varier
de 0 à 255 (255 étant la priorité la plus forte).
Les priorités de 1 à 255 sont réservées
aux politiques POSIX SCHED_RR
et SCHED_FIFO. Le niveau de priorité 0 est réservé à la politique
SCHED_OTHER uniquement. Ces politiques POSIX permettent de déterminer
l'ordonnancement d'un ensemble de tâches dont la priorité fixe est identique. Notez que cette configuration de
priorité et de politique est celle implantée dans Linux.
Preemptive type : permet de spécifier si l'ordonnanceur doit être
préemptif ou non.
Add : il permet d'ajouter un nouveau composant.Delete :
il permet de supprimer un composant existant après l'avoir
sélectionné en cliquant sur la liste des composants dans la partie
droite de la fenêtre.
Modify :
il permet de modifier un composant existant après l'avoir
sélectionné en cliquant sur la liste des composants dans la partie
droite de la fenêtre et après avoir modifié la valeur de ses attributs.
Close : il permet de valider l'ensemble des modifications effectuées
depuis l'ouverture de la fenêtre.
Cancel : il permet d'annuler toutes les modifications effectuées
depuis l'ouverture de la fenêtre.
core1 défini, il est possible de décrire le processor qui utilisera
core1 avec le menu
Edit/Hardware/Processor, qui affiche la fenêtre ci-dessous:
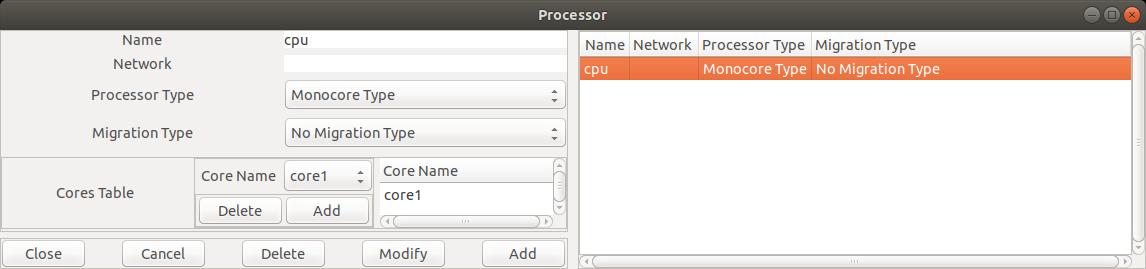
cpu1 comportant uniquement le core
core1.
L'ajout et la suppression d'un core pour un processeur s'effectue par les boutons
Add et Delete dans la partie Cores Table. Puisque nous nous limitons
ici à un processor comportant
un seul core, Cheddar requiert alors les
valeurs Monocore Type et
No Migration Type pour les attributs respectifs Processor Type et
Migration Type.
task) mais aussi des ressources partagées
entre les tâches (composant resource). Cheddar requiert par ailleurs
la modélisation des entités mémoires regroupant tâches et ressources, c'est le rôle
des composants Address Space.
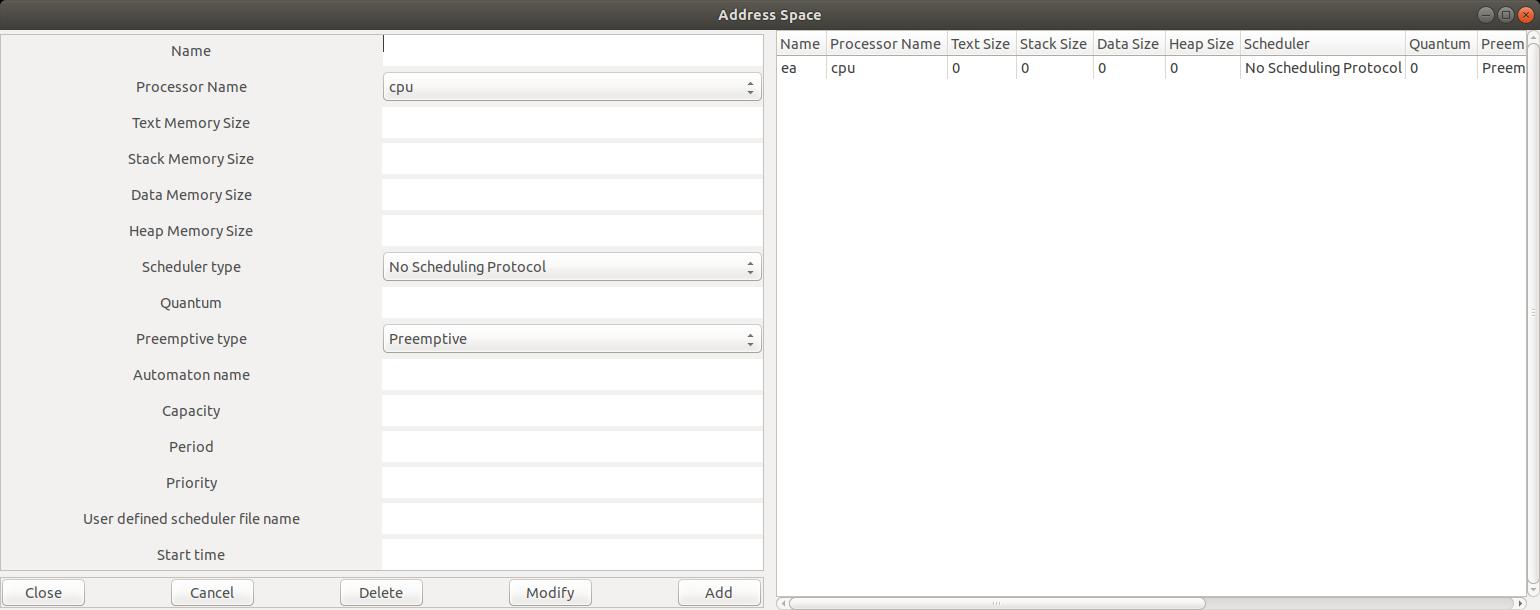
Edit/Software/Address space)
montre la définition d'un composant Address Space pour
notre exemple. Seuls
les champs Name et Cpu Name doivent être renseignés ici.
Lors des exercices de ce tutoriel, nous devrons définir un composant
Address Space pour chaque processeur.
La plupart des attributs de ce composant est utilisée pour
l'analyses d'ordonnancements hiérarchiques
comme ceux rencontrés dans les systèmes ARINC 653.
Ainsi, les autres champs de cette fenêtre n'ont pas besoin d'être renseignés pour ce tutoriel.
Edit/Software/Task :
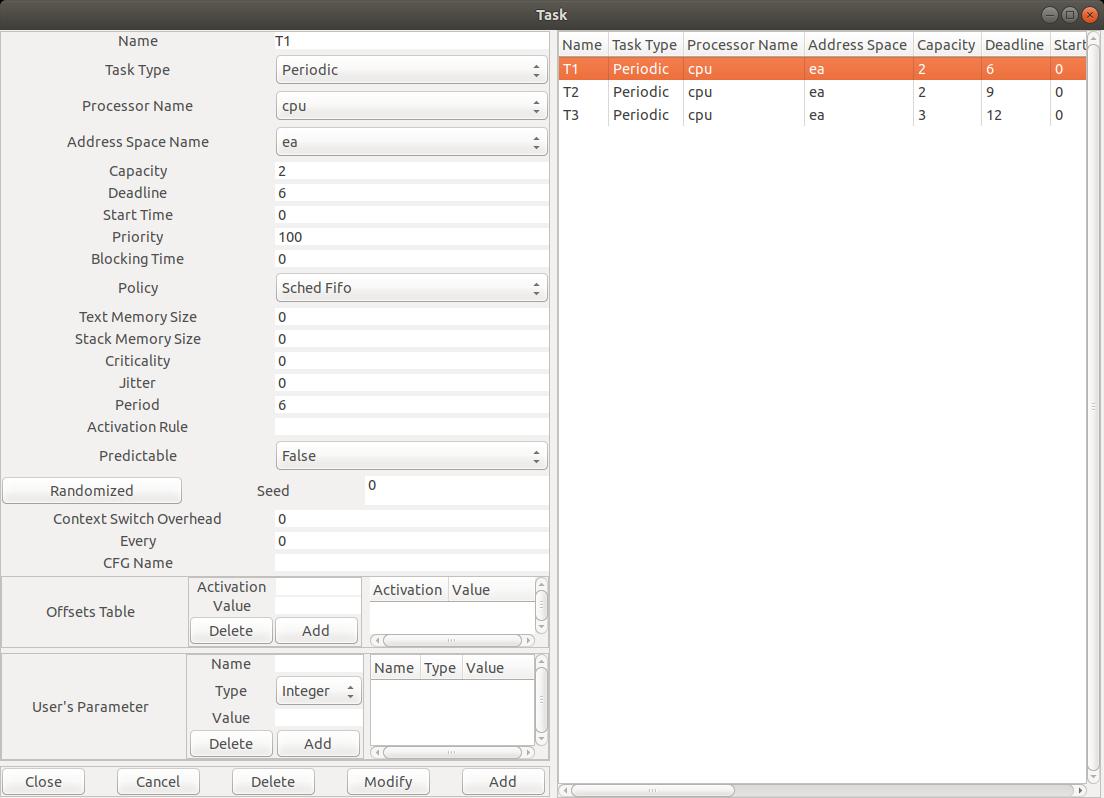
Name : le nom (unique) du composant.
Task type : le type de tâche qui
spécifie les instants de réveil
de la tâche (ex : périodique, sporadique, aléatoire selon un processus
de poisson, ...).
Capacity : le WCET de la tâche.
Period : le délai entre deux réveils successifs de la tâche, notamment la
période lorsque la tâche est périodique.
Deadline : l'échéance à respecter par la tâche. Il s'agit ici d'une
échéance relative à la date de réveil de la tâche.
Address space name et CPU name qui indique sur
quels composants Address space et Processor
la tâche est placée.
Priority : : la priorité fixe associée à la tâche.
Capacity = 2, Deadline = 6, Period = 6 Capacity = 2, Deadline = 9, Period = 9 Capacity = 3, Deadline = 12, Period = 12 Priority) ont été affectées selon Rate Monotonic dans la plage
de
priorité autorisée
(de 1 à 255).
Deadline
est égale à celle de l'attribut Period.
Start time est égal à 0 pour
toutes les tâches.
File/Save XML Project : un système modélisé en Cheddar peut être exporté dans un fichier XML
respectant le format Cheddar ADL.
File/Open XML Project: un modèle peut être chargé dans Cheddar pour être analysé.
Dans ce tutoriel, pour certains exercices, les modèles sont disponibles en
téléchargement.
Dans cette partie, nous allons analyser le modèle ultérieurement élaboré.
A partir d'un tel modèle, nous pouvons appliquer trois types d'analyse, toutes disponibles
à partir du menu Tools :
Sous les menus, quelques boutons offrent des raccourcies pour
certaines analyses fréquemment employées.
Ainsi, le bouton ![]() déclenche le calcul et l'affichage d'une simulation
alors que le bouton
déclenche le calcul et l'affichage d'une simulation
alors que le bouton
![]() provoque l'application de tests de faisabilités classiques
sur le modèle. Il s'agit principalement du calcul des pires temps de réponse pour
des modèles de tâches périodiques selon une méthode similaire à celle de Joseph et Pandia [JOS 86].
Pour des tests de faisabilité plus spécifiques (ex: transaction),
ou une configuration des simulations, il est nécessaire d'utiliser les outils
proposés par le menu
provoque l'application de tests de faisabilités classiques
sur le modèle. Il s'agit principalement du calcul des pires temps de réponse pour
des modèles de tâches périodiques selon une méthode similaire à celle de Joseph et Pandia [JOS 86].
Pour des tests de faisabilité plus spécifiques (ex: transaction),
ou une configuration des simulations, il est nécessaire d'utiliser les outils
proposés par le menu Tools.
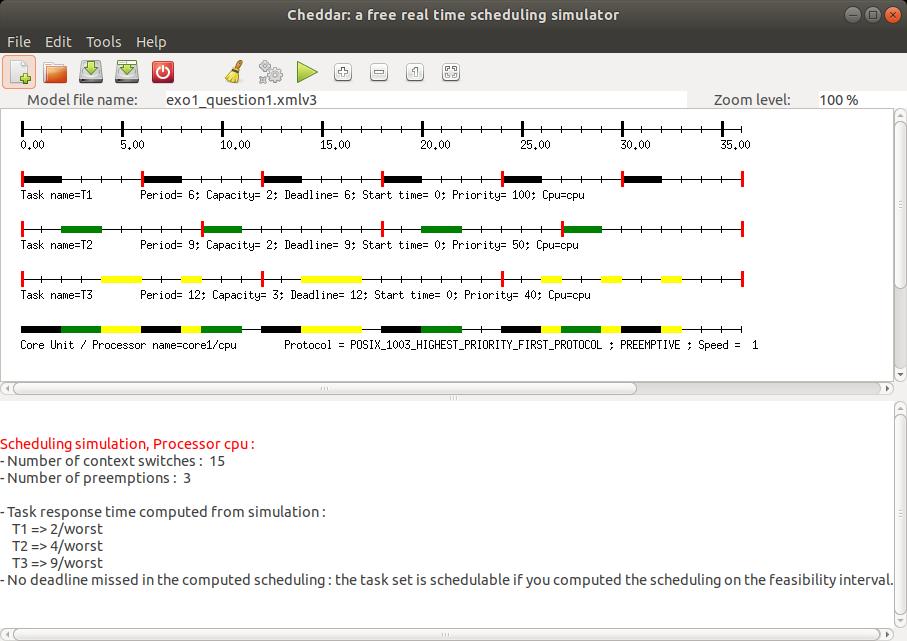
Les figures 6 et 7 présentent une copie d'écran, pour le modèle édité dans la partie
I.2 après la pression des boutons
![]() et
et
![]() . On y constate que les pires temps de réponse
calculés par le test de faisabilité
de Joseph et Pandia [JOS 86] ainsi que la simulation sur l'intervalle de faisabilité nous indiquent
que toutes les tâches respectent leurs échéances.
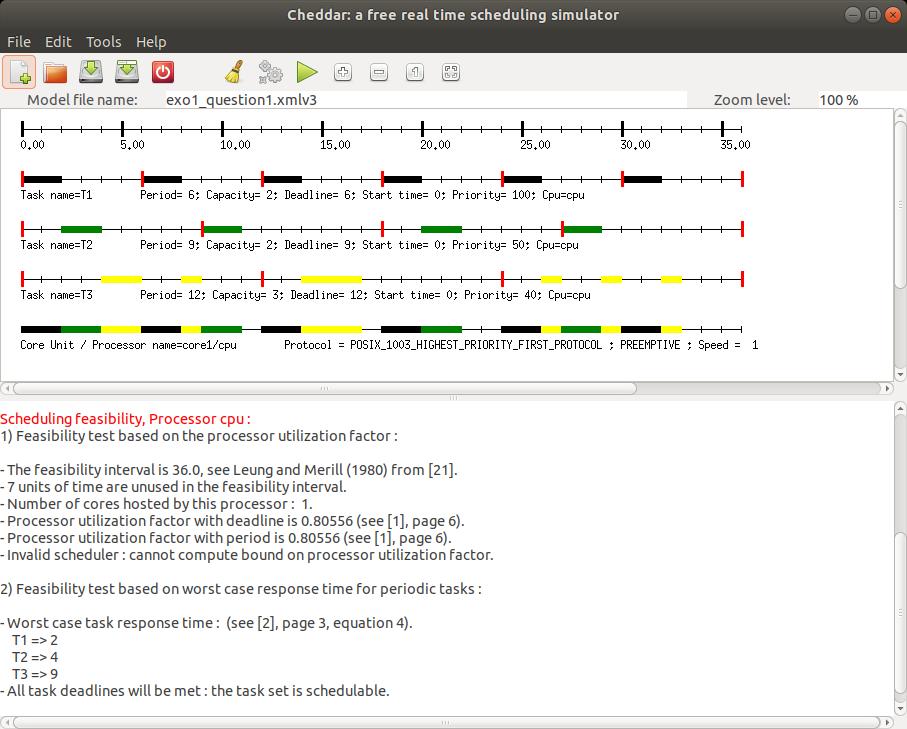
Le test de faisabilité sur le taux d'occupation du processeur n'est pas appliqué ici car l'outil
ne peut déterminer comment les priorités ont été affectées ; pour ce faire,
il aurait été nécessaire
de choisir un ordonnanceur différent lors de
l'édition de
. On y constate que les pires temps de réponse
calculés par le test de faisabilité
de Joseph et Pandia [JOS 86] ainsi que la simulation sur l'intervalle de faisabilité nous indiquent
que toutes les tâches respectent leurs échéances.
Le test de faisabilité sur le taux d'occupation du processeur n'est pas appliqué ici car l'outil
ne peut déterminer comment les priorités ont été affectées ; pour ce faire,
il aurait été nécessaire
de choisir un ordonnanceur différent lors de
l'édition de core1 : l'ordonnanceur (e.g. Rate Monotonic Protocol).
Notez que dans les chronogrammes, les rectangles rouges verticaux représentent les instants
de réveil des tâches alors que les rectangles horizontaux représentent les moments où les tâches
s'exécutent. De nombreux paramètres d'affichage ou de simulation peuvent
être modifiés via le menu Tools/Scheduling/Scheduling Options.
Capacity = 2, Deadline = Period = 6,
Start time = 0
Capacity = 8, Deadline = Period = 24,
Start time = 0
Capacity = 4, Deadline = Period = 12,
Start time = 0
Dans les exercices suivants, nous allons expérimenter et comparer 3 algorithmes d'ordonnancement temps réel classiques.
Capacity = 4, Deadline = Period = 8,
Start time = 0
Capacity = 5, Deadline = Period = 10,
Start time = 0
Earliest_Deadline_First_Protocol pour l'attribut Scheduler type).
cette fois,
puis refaire les questions 2 et 3.
Task Type (cf. figure 5).
Period=Deadline=8, Capacity=4, Start time = 0
Period=Deadline=16, Capacity=8, Start time = 0
Deadline=15, Capacity=4, Start time = 0
Period=Deadline=9, Capacity=4, Start time = 0
Period=Deadline=8, Capacity=3, Start time = 0
Li(t)
d'une tâche i à l'instant t s'évalue
par Li(t)= Deadline - reste(t) où reste(t) est le
reliquat de capacité à exécuter à l'instant t.
Dans les exercices précédents, nous supposions les tâches indépendantes. Par la suite, nous allons illustrer les dépendances de tâches avec une dépendance classique : le partage de ressources.
Period=Deadline=6, Capacity=2, Start time = 0
Period=Deadline=8, Capacity=2, Start time = 0
Period=Deadline=12, Capacity=5, Start time = 0
On utilise un algorithme à priorité fixe préemptif pour ordonnancer les tâches. Les priorités sont affectées selon Rate Monotonic.
Les tâches T1 et T3 se partagent une ressource dont le nom est S. T1 et T3 accèdent à S en exclusion mutuelle.
Edit/Software/Resource qui affiche la
fenêtre
suivante :
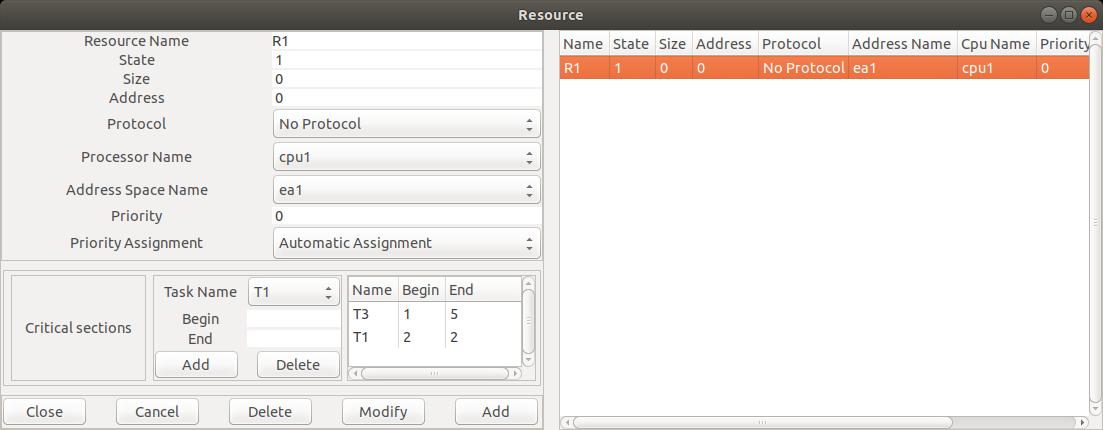
Name : le nom unique de la ressource.
CPU Name et Address space name : comme pour les tâches, ces attributs
indiquent le placement de la ressource.
State : l'état de la ressource. Une ressource fonctionne ici comme un sémaphore à
compteur.
Une ressource possède
un compteur entier.
Si ce compteur est inférieur ou égal à zéro, une tâche qui demande l'allocation de la ressource
sera bloquée. Si une tâche libère la ressource, le compteur est incrémenté. Si une tâche alloue la
ressource, le compteur est décrémenté. Pour nos exercices, State doit être positionné à
1.
Protocol : le protocole à appliquer lors des accès à la ressource.
La valeur No Protocol indique que le simulateur n'effectuera aucun
changement de priorité lors des accès à la ressource : un sémaphore FIFO est alors utilisé.
Dans cet exercice et le suivant, nous utiliserons aussi
les valeurs Priority Inheritance Protocol (ou PIP) et
Priority Ceiling Protocol (ou PCP).
Pour l'instant, positionner la valeur No Protocol pour la ressource S.
Priority assignment : qui indique s'il faut manuellement calculer
la priorité plafond d'une ressource ou non. Pour nos exercices, il est nécessaire
de laisser cet attribut à la valeur Automatic Assignment.
Begin indique le début d'une section critique et
End
la fin d'une
section critique. Les boutons Add et Delete permettent d'ajouter ou de
supprimer
une section critique associée
à la ressource. Ainsi, dans la figure 8, il est spécifié que T1 alloue/requiert la ressource
au début de la seconde
unité de temps de sa capacité et la libère à la fin de cette même unité de temps
alors que T3 requiert la ressource avant d'exécuter la 1ère unité de temps de sa capacité et libère
la
ressource après la cinquième unité de temps.

Priority Inheritance Protocol (ou PIP), puis, calculer à nouveau l'ordonnancement.
Avec PIP,
une tâche qui bloque une autre plus prioritaire qu'elle, exécute la section
critique avec la priorité de la tâche bloquée.
Period=Deadline=31, Capacity=8, Start time = 0
Period=Deadline=30, Capacity=8, Start time = 2
Start time) .
On utilise un algorithme à priorité fixe préemptif pour ordonnancer ces tâches.
Les tâches T1 et T2 accèdent à 2 ressources partagées, les ressources R1 et R2 :
PIP (Priority Inheritance Protocol).
Priority Ceiling Protocol dans la
fenêtre de la figure 8). Il faudra modifier la
définition des ressources R1 et R2 pour ce faire. PCP fonctionne
de la façon suivante :
On étudie dans cet exercice un système de visualisation intégré dans un véhicule automobile. Ce système est constitué d'un ensemble de tâches dont on souhaite étudier le respect de leurs contraintes temporelles.
Cette application est constituée de 5 tâches périodiques :
On suppose que toutes les tâches démarrent à un instant identique. Enfin, on souhaite que les tâches terminent une activation donnée avant le début de leur activation suivante.
Le système utilisé propose un ordonnanceur préemptif à priorité fixe comprenant 32 niveaux de priorité (de 0 à 31). 0 est le niveau de priorité le plus faible. Le système ne permet pas l'affectation d'une priorité identique à plusieurs tâches. Le système comporte un processeur avec un coeur uniquement.
Question 1 :
Question 2 :
A partir des priorités déterminées dans la question précédente,
calculer avec Cheddar les pires temps de réponse des tâches
CAPTEUR_1, CAPTEUR_2,
et CAPTEUR_3 avec la méthode de Joseph et Pandia.
Question 3 :
En fait, les tâches
CAPTEUR_1,
CAPTEUR_2,
et CAPTEUR_3
partagent une zone
de mémoire accédée en exclusion mutuelle.
CAPTEUR_1 et CAPTEUR_2 accèdent à cette ressource pendant toute leur
capacité.
CAPTEUR_3 accède à la ressource pendant les deux premières millisecondes de sa
capacité. Le sémaphore qui protège la zone de mémoire partagée
applique le protocole PIP.
Expliquer pourquoi les temps de réponse calculés
dans la question précédente
ne constituent plus des pires cas.
Question 4 :
Avec Cheddar, calculer le chronogramme décrivant l'ordonnancement
des tâches pendant les 60 premières milli-secondes.
Vous signalerez les instants où la ressource est allouée et libérée,
les éventuelles inversions de priorité ainsi que les instants où une
tâche hérite d'une priorité.
Question 5 :
Pour les questions 5 et 6,
nous supposons maintenant que les tâches ne partagent plus
de ressource : les tâches sont donc indépendantes.
Afin d'activer les tâches plus fréquemment,
on souhaite tester une configuration
où les tâches sont placées sur deux processeurs
(les processeurs a et b).
Chaque processeur comporte un coeur uniquement : il n'y a donc pas de migration des tâches
d'un coeur à un autre.
Les tâches sont maintenant définies par les paramètres suivants :
Capacity = 4,
Period=Deadline= 6
Capacity = 2,
Period=Deadline= 20
Capacity = 2,
Period=Deadline= 3
Capacity = 2, Period=Deadline= 5
Capacity = 2, Period=Deadline= 5
Les tâches sont toujours ordonnancées selon un algorithme
à priorité fixe. De plus, les priorités
sont affectées selon l'algorithme Rate Monotonic.
Montrer, sans simuler l'ordonnancement de ce système, qu'il existe au moins une
des tâches qui ne
respecte pas
ses contraintes temporelles.
Question 6 :
En fait, l'affectation des tâches aux
processeurs a et b a été réalisée au hasard.
En effet, toutes les tâches
peuvent à la fois s'exécuter sur le processeur a
ou sur le processeur b.
Les processeurs diffèrent uniquement par leur
vitesse d'exécution : le processeur b est
2 fois plus rapide que le processeur a.
Affecter les tâches aux
processeurs a et b de sorte que les
contraintes temporelles de toutes les tâches
soient respectées.
Justifiez vos choix.
| Nom des tâches | Priorités | Périodes/Echéances | Temps d'exécution |
|---|---|---|---|
| ORDO_BUS | 1 | 125 ms | 25 ms |
| DONNEES | 2 | 125 ms | 25 ms |
| PILOTAGE | 3 | 250 ms | 25 ms |
| RADIO | 4 | 250 ms | 25 ms |
| CAMERA | 5 | 250 ms | 25 ms |
| MESURE | 6 | 5000 ms | 50 ms |
| METEO | 7 | 5000 ms | 50 ms ou 75 ms |