
Critical systems such as real-time control-command can be implemented as a set of tasks
running concurrently on a processor. When tasks have to communicate, it can be
achieved by shared memory areas that have to be accessed in mutual exclusion.
We assume a uniprocessor execution platform.
A typical AADL solution for such systems is composed of thread, data, process
components for the software part.
The hardware part is modeled by a single processor component.
You can download here an example
of the recipe shown below:
package multiple_tasks_interacting_with_shared_memory
public
data counter
end counter;
data implementation counter.Impl
properties
Concurrency_Control_Protocol => Priority_Ceiling;
end counter.Impl;
thread a_task
features
fe : requires data access counter.Impl;
end a_task;
thread implementation a_task.Impl
properties
Dispatch_Protocol => Periodic;
end a_task.Impl;
process Application
end Application;
process implementation Application.Impl
subcomponents
T1 : thread a_task.Impl;
T2 : thread a_task.Impl;
D : data counter.Impl;
connections
cx1 : data access D -> T1.fe;
cx2 : data access D -> T2.fe;
properties
Period => 10 ms applies to T1;
Deadline => 10 ms applies to T1;
Compute_Execution_Time => 1 ms .. 2 ms applies to T1;
Priority => 1 applies to T1;
Period => 5 ms applies to T2;
Deadline => 5 ms applies to T2;
Compute_Execution_Time => 1 ms .. 1 ms applies to T2;
Priority => 2 applies to T2;
end Application.Impl;
processor cpu
properties
Scheduling_Protocol=>(POSIX_1003_HIGHEST_PRIORITY_FIRST_PROTOCOL);
end cpu;
system a_system
end a_system;
system implementation a_system.Impl
subcomponents
process1 : process application.Impl;
cpu1 : processor cpu;
properties
Actual_Processor_Binding => (reference (cpu1)) applies to process1;
end a_system.Impl;
end multiple_tasks_interacting_with_shared_memory;
The solution above models two threads (called T1 and T2) sharing one resource
(called D). Notice the connexion between T1 and D, and T2
and D. As two connexions
exist with D, it means that any access to D has to be made
concurrently safe: the AADL
runtime will add in that case a semaphore to manage the access of D. Each thread will
lock this semaphore before any access to D and will release it when its
execution is completed.
The semaphore accesses are not directly handled by the user/progammer: it is
the AADL runtime that will define, lock and unlock such object.
For example, Ocarina will do it by the source code that it will generate from the AADL model.
Programming concurrent application is complex and it is difficult to write safe programs in
this context. Letting Ocarina managing semaphore management improves the quality of this
concurrent applications.
In practice,
when a thread connected to a
shared data component is dispatched, the AADL runtime/Ocarina locks any data connected to
the thread. Such data are unlocked when the thread completes the execution of its
dispatch. The Concurrency_Control_Protocol
manages how a thread expecting to enter
in the critical section is blocked and how thread priorities have to change to
forbid deadlocks, multiple blockings and priority inversion.
Both threads and data components can be subject of analysis with this kind of model.
About analysis regarding thread components, see recipe 1 where the possible analysis for
this AADL model are explained.
From a data point of view, the main temporal properties we may look for is
share resource waiting
time, and more specifically its worst case waiting time. Waiting time may be
called blocking time also and is the time a thread has to wait for the access
to the data. Indeed, if the data is shared by more than one thread,
the threads may have to wait if at dispatch time, the date is already locked.
In that case, the threads
have to wait for the release of data before accessing it.
Again, as with recipe 1, analysis can be performed either by simulation or by feasibility tests.
During an analysis, one can compute:
- The Worst/best/average waiting time a thread could have to wait for the access to
a shared resource.
- Detection of deadlock or priority inversion. Deadlocks may occur when two
threads are waiting each other on shared data. Priority inversion
occurs when a high priority thread is blocked and has to wait for the execution of
a low priority thread because of a shared data component. To avoid priority
inversion, data component must use specific concurrency protocol such as PIP or PCP.
- ...
As with recipe 1, such model can be analyzed by both OSATE and AADLInspector: with the
Marzhin simulator or Cheddar embedded into AADLInspector, or with the Cheddar OSATE plugin.
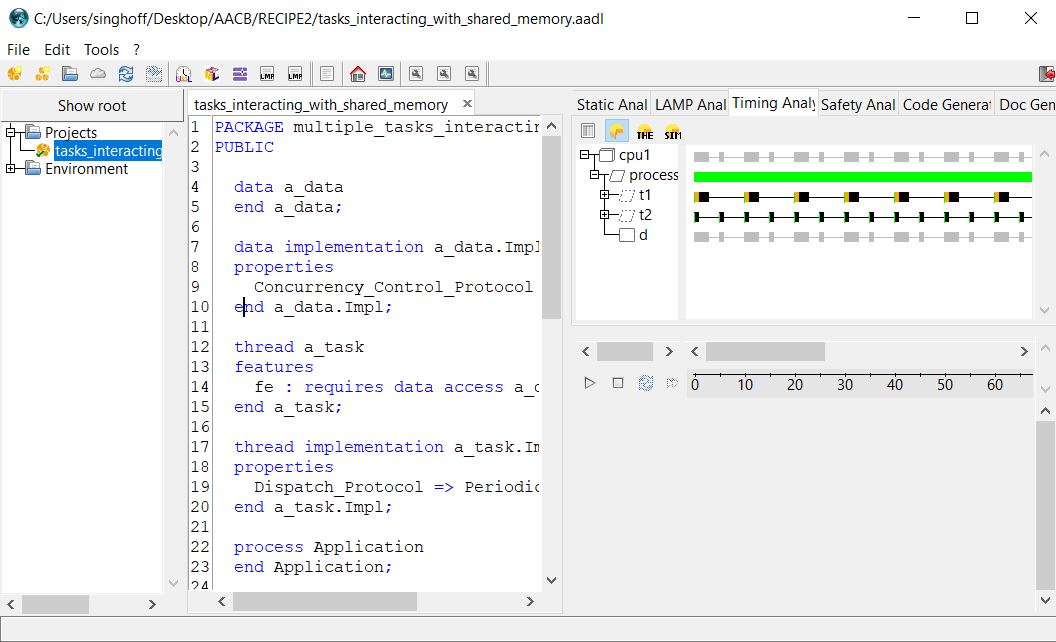
The two pictures below show an analysis of the model with both AADLInspector and
Cheddar OSATE plugin. On the right top corner of the AADLInspector windows, one can
see the scheduling of the tasks and of the D data. Grey vertical lines for
D show when the data is locked and unlocked.
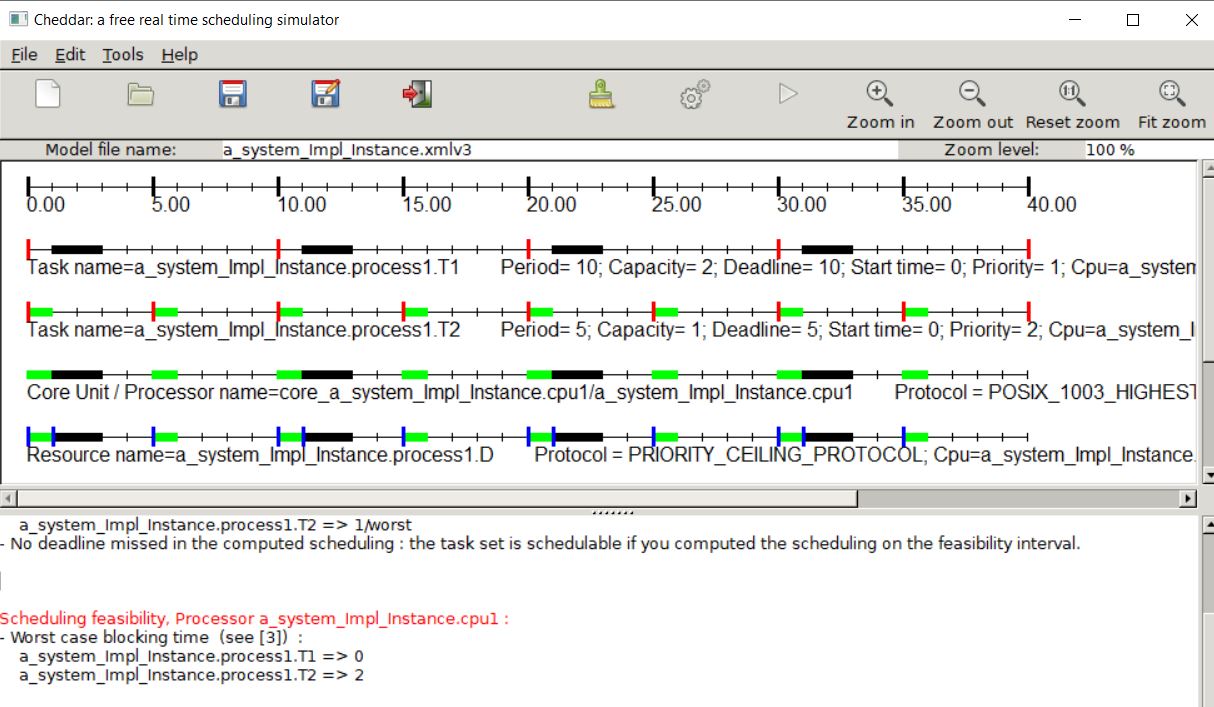
On the Cheddar window, are shown both the threads and D. Notice the name of the component
that shows the hierarchy of the AADL entities composing the instance model. As AADLInspector,
Cheddar shows each data
on a dedicated line. Horizontal rectangle shows when D is allocated with the color of the
thread that use it. Blue vertical rectangle displays when D is released.
A similar vertical rectangle in red shows when D is allocated too.
From such scheduling simulation Cheddar can display worst/best/average bloking time, priority
inversion and deadlock.
In the picture, Cheddar displays a worst case blocking time that is computed by
a feasibility tests, i.e. not from the scheduling simulation, which is usually a pessismitic
latency but which needs a lower computation time during analysis.
With this recipe, we can also use Ocarina to go further to the implementation.
To build an executable with Ocarina for this recipe, the process is the same than
with recipe 1. We need an AADL file scenario.aadl to drive to source code
generation.
Comparing to recipe 1, we need to provide new pieces of source code and AADL components
required to generate C code related to data component.
From the user/functional point of view, first we must write the C code that will
be called and runtime by PolyORB. This C
code provides an implementation of each subprogram component of the AADL model and
is composed of :
- subprograms to read and write the D component. In this example, we
assume that D is an integer, but the Data modeling annex of AADL allows
designers to model various other basic types, but also compound data
built with enumeration or structure
types similar to C.
- the subprograms that are run at each periodic release of each thread.
For the example of this recipe, the C code is given below. Notice that
threads T1 and T2 simply display they name and the current time at each release, while
counter_read and counter_write are the
subprograms to respectively read and update D.
#include ...
int current_value = 0;
void t1_spg (void)
{
printf ("[%d] T1 last read is %i\n", milliseconds_since_epoch(), current_value);
fflush (stdout);
}
void counter_read (int* value)
{
printf ("counter read: %d\n", *value);
current_value=*value;
}
#include ...
void t2_spg (void)
{
printf ("[%d] T2\n", milliseconds_since_epoch());
fflush (stdout);
}
void counter_write (int* value)
{
int v = *value;
v++;
*value = v;
printf ("counter Write : %d\n", *value);
}
Each of this C function is then referenced in the AADL model. In the sequel,
we show three important parts:
- Each of the 4 subprograms are modeled by subprogram AADL component, which gives
to Ocarina, where to find the C functions (in which C file and what is the name of the C function).
- At each periodic dispatch, T1 calls the C functions t1_spg
and counter_read
while T2 calls t2_spg and counter_write.
Those two sequences of subprogram calls are expressed by the AADL components
t1_sequence and t2_sequence.
- Finally, the thread description is given. Two important information
has to be provided there. First,
we must specify that each thread requires the access to the data component.
Second, the entry point of the program to run by the threads is expressed
by instiancing t1_sequence and t2_sequence components.
The result is the following model:
subprogram t1_spg
properties
source_language => (C);
source_name => "t1_spg";
source_text => ("t1.c");
end t1_spg;
subprogram t2_spg
properties
source_language => (C);
source_name => "t2_spg";
source_text => ("t2.c");
end t2_spg;
subprogram Write_spg
features
this : requires data access counter.Impl;
properties
source_language => (C);
source_name => "counter_write";
source_text => ("t2.c");
end Write_spg;
subprogram Read_spg
features
this : requires data access counter.Impl;
properties
source_language => (C);
source_name => "counter_read";
source_text => ("t1.c");
end Read_spg;
------------------------------------------------
-- Thread sequence of call
------------------------------------------------
subprogram t1_sequence
features
seq_cnt : requires data access counter.Impl;
end t1_sequence;
subprogram implementation t1_sequence.Impl
calls
Mycalls: {
Call_Read : subprogram counter.Read_counter;
Call_t1 : subprogram t1_Spg;
};
connections
C1 : data access seq_cnt -> Call_Read.this;
end t1_sequence.Impl;
subprogram t2_sequence
features
seq_cnt : requires data access counter.Impl;
end t2_sequence;
subprogram implementation t2_sequence.Impl
calls
Mycalls: {
Call_t2 : subprogram t2_Spg;
Call_Write : subprogram counter.Write_counter;
};
connections
C1 : data access seq_cnt -> Call_Write.this;
end t2_sequence.Impl;
-------------
-- Threads --
-------------
thread a_task
features
fe : requires data access counter.Impl;
end a_task;
thread implementation a_task.Impl
properties
Dispatch_Protocol => Periodic;
end a_task.Impl;
thread t1 extends a_task
end t1;
thread implementation t1.Impl
calls
Mycalls: {
call : subprogram t1_sequence.Impl;
};
connections
C1 : data access fe -> call.seq_cnt;
end t1.Impl;
thread t2 extends a_task
end t2;
thread implementation t2.Impl
calls
Mycalls: {
call : subprogram t2_sequence.Impl;
};
connections
C1 : data access fe -> call.seq_cnt;
end t2.Impl;
In the previous parts, we have not given the detail of the data
component. Contrary with the version of the model handled with AADLInspector
and OSATE in the beginning of this recipe, we must given extra information required
to generate and configure the PolyORB source code.
First, Ocarine needs information about the type and the structure
of the data stored in the component. Below, we use again the Data modeling annex and
its Data_Representation property to specify this.
Second, methods that threads can call to handle the
data is specified: one method to read the data and a second method to write it.
Last but not least, scheduling properties are provided to allow the use of
concurrency control protocol such as PCP. Two properties assigned to the data component
are specified here:
-
Priority, which assigns to the data component the value for the
priority ceiling, i.e. here a value of 250
-
And the Concurrency_Control_Protocol selects the PCP protocols to manage
priority inheritance during the data component accesses.
Those properties are some of them making our model compliant
with the Ravenscar profile, making it compliant with the schedulability analysis
providing by OSATE and AADLInspector. Ravenscar is explained in the sequel.
The model is then shown here:
data counter_Internal_Type
properties
Data_Model::Data_Representation => Integer;
end counter_Internal_Type;
data counter
features
Write_counter : provides subprogram access Write_spg;
Read_counter : provides subprogram access Read_spg;
properties
Priority => 250;
Concurrency_Control_Protocol => Priority_Ceiling;
end counter;
data implementation counter.Impl
subcomponents
Field : data counter_Internal_Type;
spgWrite : subprogram Write_spg;
spgRead : subprogram Read_spg;
connections
C1 : subprogram access SpgWrite -> Write_counter;
C2 : subprogram access SpgRead -> Read_counter;
properties
Data_Model::Data_Representation => Struct;
end counter.Impl;
Last brick of the model is the actual process gathering all
software entities for this example, which is exactly the same model
that we have handled with AADLInspector and OSATE:
-------------
-- Process --
-------------
process node_a
end node_a;
process implementation node_a.impl
subcomponents
t1 : thread t2.Impl;
t2 : thread t2.Impl;
D : data counter.Impl;
connections
C1 : data access D -> t1.fe;
C2 : data access D -> t2.fe;
properties
Period => 10 ms applies to T1;
Deadline => 10 ms applies to T1;
Compute_Execution_Time => 1 ms .. 2 ms applies to T1;
Priority => 1 applies to T1;
Period => 5 ms applies to T2;
Deadline => 5 ms applies to T2;
Compute_Execution_Time => 1 ms .. 1 ms applies to T2;
Priority => 2 applies to T2;
end node_a.impl;
To run the application, the C code must be generated and compiled before.
For details, see recipe 1 or the Ocarina tool description page.
AADL component properties for each tool
While AADL provides standard properties, each tool may handle
specific properties and/or specific values for standard properties.
This may lead to interoperability issues between AADL tools. Sometimes,
different values
handled by different tools make reference to the same concept/protocol/algorithm.
For tool specific properties regarding thread and their scheduling, see recipe 1.
For data component, the main property is the Concurrency_Control_Protocol
property.
This property specifies which protocol to apply with shared data.
Most of the tools provide the same protocols and quite the same
litterals for this property. Here is the mapping of each tool values:
| AADLInspector | OSATE2, Ocarina | Cheddar |
| PCP, Priority_Ceiling_Protocol | Priority_Ceiling | Priority_Ceiling_Protocol |
| PIP, Priority_Inheritance | Priority_Inheritance | Priority_Inheritance_Protocol |
| None_Specified | None_Specified | No_Protocol |
| IPCP, ICPP, Immediate_Priority_Ceiling_Protocol | Maximum_Priority | Immediate_Priority_Ceiling_Protocol |
| Semaphore | Semaphore | No_Protocol |
| Interrupt_Masking | Interrupt_Masking | No_Protocol |
| Protected_Access | Protected_Access | No_Protocol |
| Spin_Lock | Spin_Lock | No_Protocol |
Ravenscar profile and AADL
The example of AADL model above is compliant with Ravenscar.
Ravenscar is a part of the
Ada 2005 standard (burns 2007). It is a set of Ada program
restrictions usually enforced at compilation time,
which guarantees that the software architecture is
predictable including from a timing point of view. Ravenscar is
an Ada subset where real-time applications are
composed of a set of threads and shared data.
Ravenscar assumes that 1) threads are periodic and scheduled with
a fixed priority scheduler and 2) data components
are accessed with ICPP, or Inheritance Ceiling Priority
Protocol (Burns 2007).
For AADL designers, the interest of Ravenscar lays on the fact that if their
AADL models are compliant with Ravenscar, it guarantees that AADL tools will be able
to safely analyze their model, i.e. that the results of the analysis are sound, and
that they are what users will
see at execution time.
First handouts : a simple case study ... as a simple example
In this part, we will model and analyze a set of threads writing
or reading data from a shared memory area. The shared memory area is modeled by
a data component. Writing or reading an element will be modeled by the access of
the data component in mutual exclusion. The objective of this exercise is to gradually
build and analyze such model. In the first question, we will define two independant
threads, i.e. we do not model the shared memory area. In the next question,
we intend to model several readers and writers, always independents. Finally, in
the last question, we extend the second version of the model with the thread communications.
Mars Pathfinder
This case study
is extracted from (Cottet 2000) and is
about a simplified architecture model of the Mars !Pathfinder mission. In this
case study, you must look for a design mistake and propose
a solution for it. In 1997, Mars Pathfinder casts a mobile robot
called Sojourner on Mars. This mobile robot was controled by a
multitask software running on a VxWorks uniprocessor target.
This software was composed of the following tasks:
| Tasks | Priorities | Periods | Execution time |
| SCHED_BUS | 1 | 125 ms | 25 ms |
| DATA | 2 | 125 ms | 25 ms |
| CONTROL | 3 | 250 ms | 25 ms |
| RADIO | 4 | 250 ms | 25 ms |
| VIDEO | 5 | 250 ms | 25 ms |
| MESURE | 6 | 5000 ms | 50 ms |
| FORECAST | 7 | 5000 ms | Between 50 ms and 75 ms |
All the tasks are periodic, synchronous, and have deadlines equal to periods.
FORECAST is sometimes released for a job of 50 ms, and sometimes for a job of 75 ms,
depending of the size of the payload to handle.
Priority levels expressed bellow are VxWorks priorities : the lower the value is,
the higher the priority level is.
DATA, CONTROL, MESURE and FORECAST required a shared data which is accessed by a
critical section during all their execution times (i.e. all their capacity/WCET).
To reduce costs, those critical sections were implemented with a mutex that did
not use inheritance priority protocol such as PIP or PCP. In order to define those
critical sections without PIP/PCP, simply do not add
the Concurrency_Control_Protocol
property when defining your data component.
- During the mission of Mars PathFinder operators
noticed that some deadlines were missed, leading to frequent
reboots of the hardware. Design an AADL model to discover what
are the missed deadlines and why those threads where not able to meet their deadlines.
- How to solve this issue? Apply it on your AADL model. Test your
solution with AADLInspector or/and OSATE/Cheddar.
Possible solution/AADL model for this
case study here.
Fridge case study
We want to investigate the behavior of the software embedded into a fridge.
This control-command software
manages the production of cold air, an alarm and the door.
The software have to enforce two properties:
- Property 1: an alarm is raised when the door stays opened too much time.
- Property 2: the lamp of the fridge is managed according to the door since it has to
be switched on when the door is open and switched off otherwise.
The software is composed of 5 tasks with the following parameters:
| Tasks | Execution times | Periods |
| Thermostat | Never much more than 6 ms | 15 ms |
| Door | 4 ms sometimes, 2 ms otherwise | 30 ms |
| Lamp | Never much more than 1 ms | 7 ms |
| Alarm | 2 ms in many case, sometimes upto 3 ms | 10 ms |
| Sensor | Never much more than 2 ms | 14 ms |
Tasks are deadline on request tasks, i.e. deadline are equal to periods.
All tasks are synchronous, i.e. all tasks start at the same time, by convention time 0.
Task Thermostat and Alarm have to share a piece of memory during all their execution time
to enforce properties 1 and 2.
- Propose an AADL model with one processor running all those tasks with a
Rate Monotonic preemptive scheduling.
- Investigate the schedulability of this model with OSATE/Cheddar or AADLInspector.
- Assuming the following fridge.c file:
#include <stdio.h>
#include <po_hi_time.h>
void sensor_spg (void)
{
printf ("[%d] sensor\n", milliseconds_since_epoch());
fflush (stdout);
}
void lamp_spg (void)
{
printf ("[%d] lamp\n", milliseconds_since_epoch());
fflush (stdout);
}
void door_spg (void)
{
printf ("[%d] door\n", milliseconds_since_epoch());
fflush (stdout);
}
void thermostat_spg (void)
{
printf ("[%d] thermostat\n", milliseconds_since_epoch());
fflush (stdout);
}
void memory_write (int* value)
{
int v = *value;
v++;
*value = v;
printf ("Memory write : %d\n", *value);
}
int current_memory_value = 0;
void alarm_spg (void)
{
printf ("[%d] alarm last read is %i\n", milliseconds_since_epoch(), current_memory_value);
fflush (stdout);
}
void memory_read (int* value)
{
printf ("Memory value: %d\n", *value);
current_memory_value=*value;
}
Update your AADL model to produce an executable to simulate the execution of such system
with Ocarina.
- Investigate the generated files by Ocarina. Explain
what is the function of the activity.h and
activity.c, deployment.h and deployement.c
and also main.c.
- In practice, this model is not schedulable on one processor.
Propose a new version of this model with two processors.
We assume that:
- Tasks Alarm, Thermostat and their shared data
must be located on the same processor.
- Tasks Sensor, Door and Lamp are deployed on a second
processor.
- Update your AADL model to deploy the application on two processors.
Generate, compile and test your application thanks to Ocarina.
- In the generated code by Ocarina for two processors, what are the main differences
comparing with the generated code for one processor?
Possible solution/AADL model for this
case study here.